// Cache Dataset -- it is lazy and so nothing really happens
val data = spark.range(1).cache
// Trigger caching by executing an action
// The common idiom is to execute count since it's fairly cheap
data.countDataset Caching and Persistence
One of the optimizations in Spark SQL is Dataset caching (aka Dataset persistence) which is available using the Dataset API using the following basic actions:
cache is simply persist with MEMORY_AND_DISK storage level.
At this point you could use web UI’s Storage tab to review the Datasets persisted. Visit http://localhost:4040/storage.
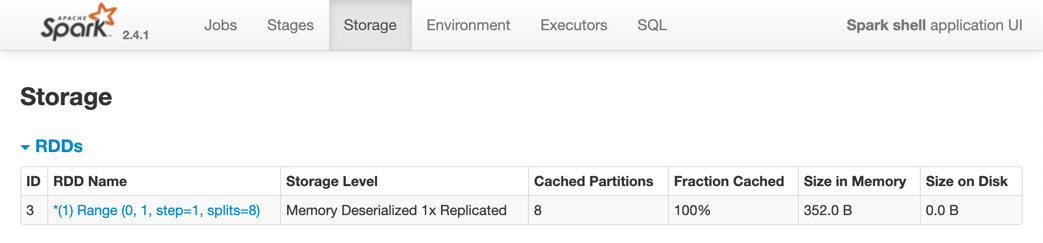
Figure 1. web UI’s Storage tab
persist uses CacheManager for an in-memory cache of structured queries (and InMemoryRelation logical operators), and is used to cache structured queries (which simply registers the structured queries as InMemoryRelation leaf logical operators).
At withCachedData phase (of execution of a structured query), QueryExecution requests the CacheManager to replace segments of a logical query plan with their cached data (including subqueries).
scala> println(data.queryExecution.withCachedData.numberedTreeString)
00 InMemoryRelation [id#9L], StorageLevel(disk, memory, deserialized, 1 replicas)
01 +- *(1) Range (0, 1, step=1, splits=8)// Use the cached Dataset in another query
// Notice InMemoryRelation in use for cached queries
scala> df.withColumn("newId", 'id).explain(extended = true)
== Parsed Logical Plan ==
'Project [*, 'id AS newId#16]
+- Range (0, 1, step=1, splits=Some(8))
== Analyzed Logical Plan ==
id: bigint, newId: bigint
Project [id#0L, id#0L AS newId#16L]
+- Range (0, 1, step=1, splits=Some(8))
== Optimized Logical Plan ==
Project [id#0L, id#0L AS newId#16L]
+- InMemoryRelation [id#0L], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
+- *Range (0, 1, step=1, splits=Some(8))
== Physical Plan ==
*Project [id#0L, id#0L AS newId#16L]
+- InMemoryTableScan [id#0L]
+- InMemoryRelation [id#0L], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
+- *Range (0, 1, step=1, splits=Some(8))
// Clear in-memory cache using SQL
// Equivalent to spark.catalog.clearCache
scala> sql("CLEAR CACHE").collect
res1: Array[org.apache.spark.sql.Row] = Array()
// Visit http://localhost:4040/storage to confirm the cleaning|
Note
|
You can also use SQL’s You could however use Use SQL’s Use SQL’s Use SQL’s |
|
Note
|
Be careful what you cache, i.e. what Dataset is cached, as it gives different queries cached. |
|
Tip
|
You can check whether a Dataset was cached or not using the following code: |
SQL’s CACHE TABLE
SQL’s CACHE TABLE corresponds to requesting the session-specific Catalog to caching the table.
Internally, CACHE TABLE becomes CacheTableCommand runnable command that…FIXME