CatalogImpl
CatalogImpl is the Catalog in Spark SQL that…FIXME
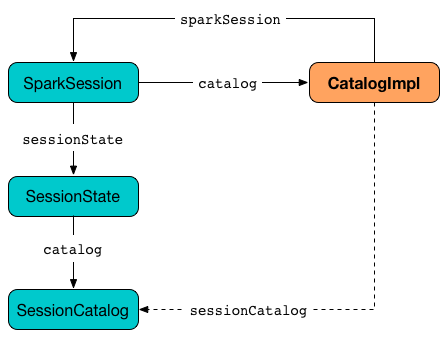
Figure 1. CatalogImpl uses SessionCatalog (through SparkSession)
|
Note
|
CatalogImpl is in org.apache.spark.sql.internal package.
|
Creating Table — createTable Method
createTable(
tableName: String,
source: String,
schema: StructType,
options: Map[String, String]): DataFrame|
Note
|
createTable is part of Catalog Contract to…FIXME.
|
createTable…FIXME
getTable Method
getTable(tableName: String): Table
getTable(dbName: String, tableName: String): Table|
Note
|
getTable is part of Catalog Contract to…FIXME.
|
getTable…FIXME
getFunction Method
getFunction(
functionName: String): Function
getFunction(
dbName: String,
functionName: String): Function|
Note
|
getFunction is part of Catalog Contract to…FIXME.
|
getFunction…FIXME
functionExists Method
functionExists(
functionName: String): Boolean
functionExists(
dbName: String,
functionName: String): Boolean|
Note
|
functionExists is part of Catalog Contract to…FIXME.
|
functionExists…FIXME
Caching Table or View In-Memory — cacheTable Method
cacheTable(tableName: String): UnitInternally, cacheTable first creates a DataFrame for the table followed by requesting CacheManager to cache it.
|
Note
|
cacheTable uses the session-scoped SharedState to access the CacheManager.
|
|
Note
|
cacheTable is part of Catalog contract.
|
Removing All Cached Tables From In-Memory Cache — clearCache Method
clearCache(): UnitclearCache requests CacheManager to remove all cached tables from in-memory cache.
|
Note
|
clearCache is part of Catalog contract.
|
Creating External Table From Path — createExternalTable Method
createExternalTable(tableName: String, path: String): DataFrame
createExternalTable(tableName: String, path: String, source: String): DataFrame
createExternalTable(
tableName: String,
source: String,
options: Map[String, String]): DataFrame
createExternalTable(
tableName: String,
source: String,
schema: StructType,
options: Map[String, String]): DataFramecreateExternalTable creates an external table tableName from the given path and returns the corresponding DataFrame.
import org.apache.spark.sql.SparkSession
val spark: SparkSession = ...
val readmeTable = spark.catalog.createExternalTable("readme", "README.md", "text")
readmeTable: org.apache.spark.sql.DataFrame = [value: string]
scala> spark.catalog.listTables.filter(_.name == "readme").show
+------+--------+-----------+---------+-----------+
| name|database|description|tableType|isTemporary|
+------+--------+-----------+---------+-----------+
|readme| default| null| EXTERNAL| false|
+------+--------+-----------+---------+-----------+
scala> sql("select count(*) as count from readme").show(false)
+-----+
|count|
+-----+
|99 |
+-----+The source input parameter is the name of the data source provider for the table, e.g. parquet, json, text. If not specified, createExternalTable uses spark.sql.sources.default setting to know the data source format.
|
Note
|
source input parameter must not be hive as it leads to a AnalysisException.
|
createExternalTable sets the mandatory path option when specified explicitly in the input parameter list.
createExternalTable parses tableName into TableIdentifier (using SparkSqlParser). It creates a CatalogTable and then executes (by toRDD) a CreateTable logical plan. The result DataFrame is a Dataset[Row] with the QueryExecution after executing SubqueryAlias logical plan and RowEncoder.
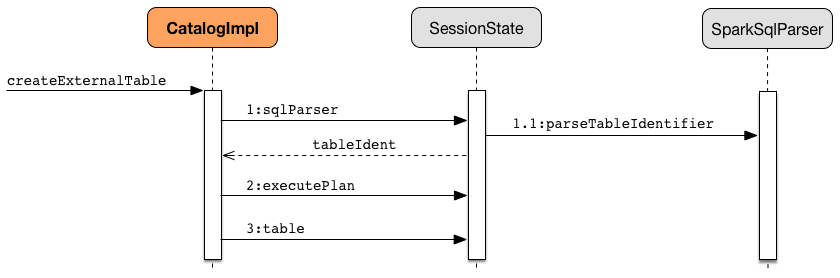
Figure 2. CatalogImpl.createExternalTable
|
Note
|
createExternalTable is part of Catalog contract.
|
Listing Tables in Database (as Dataset) — listTables Method
listTables(): Dataset[Table]
listTables(dbName: String): Dataset[Table]|
Note
|
listTables is part of Catalog Contract to get a list of tables in the specified database.
|
Internally, listTables requests SessionCatalog to list all tables in the specified dbName database and converts them to Tables.
In the end, listTables creates a Dataset with the tables.
Listing Columns of Table (as Dataset) — listColumns Method
listColumns(tableName: String): Dataset[Column]
listColumns(dbName: String, tableName: String): Dataset[Column]|
Note
|
listColumns is part of Catalog Contract to…FIXME.
|
listColumns requests SessionCatalog for the table metadata.
listColumns takes the schema from the table metadata and creates a Column for every field (with the optional comment as the description).
In the end, listColumns creates a Dataset with the columns.
Converting TableIdentifier to Table — makeTable Internal Method
makeTable(tableIdent: TableIdentifier): TablemakeTable creates a Table using the input TableIdentifier and the table metadata (from the current SessionCatalog) if available.
|
Note
|
makeTable uses SparkSession to access SessionState that is then used to access SessionCatalog.
|
|
Note
|
makeTable is used when CatalogImpl is requested to listTables or getTable.
|
Creating Dataset from DefinedByConstructorParams Data — makeDataset Method
makeDataset[T <: DefinedByConstructorParams](
data: Seq[T],
sparkSession: SparkSession): Dataset[T]makeDataset creates an ExpressionEncoder (from DefinedByConstructorParams) and encodes elements of the input data to internal binary rows.
makeDataset then creates a LocalRelation logical operator. makeDataset requests SessionState to execute the plan and creates the result Dataset.
|
Note
|
makeDataset is used when CatalogImpl is requested to list databases, tables, functions and columns
|
Refreshing Analyzed Logical Plan of Table Query and Re-Caching It — refreshTable Method
refreshTable(tableName: String): Unit|
Note
|
refreshTable is part of Catalog Contract to…FIXME.
|
refreshTable requests SessionState for the SQL parser to parse a TableIdentifier given the table name.
|
Note
|
refreshTable uses SparkSession to access the SessionState.
|
refreshTable requests SessionCatalog for the table metadata.
refreshTable then creates a DataFrame for the table name.
For a temporary or persistent VIEW table, refreshTable requests the analyzed logical plan of the DataFrame (for the table) to refresh itself.
For other types of table, refreshTable requests SessionCatalog for refreshing the table metadata (i.e. invalidating the table).
If the table has been cached, refreshTable requests CacheManager to uncache and cache the table DataFrame again.
|
Note
|
refreshTable uses SparkSession to access the SharedState that is used to access CacheManager.
|
refreshByPath Method
refreshByPath(resourcePath: String): Unit|
Note
|
refreshByPath is part of Catalog Contract to…FIXME.
|
refreshByPath…FIXME
dropGlobalTempView Method
dropGlobalTempView(
viewName: String): Boolean|
Note
|
dropGlobalTempView is part of Catalog contract].
|
dropGlobalTempView…FIXME
listColumns Internal Method
listColumns(tableIdentifier: TableIdentifier): Dataset[Column]listColumns…FIXME
|
Note
|
listColumns is used exclusively when CatalogImpl is requested to listColumns.
|