val q = spark.range(10).
groupBy('id % 2 as "group").
agg(sum("id") as "sum")
// HashAggregateExec selected due to:
// 1. sum uses mutable types for aggregate expression
// 2. just a single id column reference of LongType data type
scala> q.explain
== Physical Plan ==
*HashAggregate(keys=[(id#0L % 2)#12L], functions=[sum(id#0L)])
+- Exchange hashpartitioning((id#0L % 2)#12L, 200)
+- *HashAggregate(keys=[(id#0L % 2) AS (id#0L % 2)#12L], functions=[partial_sum(id#0L)])
+- *Range (0, 10, step=1, splits=8)
val execPlan = q.queryExecution.sparkPlan
scala> println(execPlan.numberedTreeString)
00 HashAggregate(keys=[(id#0L % 2)#15L], functions=[sum(id#0L)], output=[group#3L, sum#7L])
01 +- HashAggregate(keys=[(id#0L % 2) AS (id#0L % 2)#15L], functions=[partial_sum(id#0L)], output=[(id#0L % 2)#15L, sum#17L])
02 +- Range (0, 10, step=1, splits=8)
// Going low level...watch your steps :)
import q.queryExecution.optimizedPlan
import org.apache.spark.sql.catalyst.plans.logical.Aggregate
val aggLog = optimizedPlan.asInstanceOf[Aggregate]
import org.apache.spark.sql.catalyst.planning.PhysicalAggregation
import org.apache.spark.sql.catalyst.expressions.aggregate.AggregateExpression
val aggregateExpressions: Seq[AggregateExpression] = PhysicalAggregation.unapply(aggLog).get._2
val aggregateBufferAttributes = aggregateExpressions.
flatMap(_.aggregateFunction.aggBufferAttributes)
import org.apache.spark.sql.execution.aggregate.HashAggregateExec
// that's the exact reason why HashAggregateExec was selected
// Aggregation execution planning strategy prefers HashAggregateExec
scala> val useHash = HashAggregateExec.supportsAggregate(aggregateBufferAttributes)
useHash: Boolean = true
val hashAggExec = execPlan.asInstanceOf[HashAggregateExec]
scala> println(execPlan.numberedTreeString)
00 HashAggregate(keys=[(id#0L % 2)#15L], functions=[sum(id#0L)], output=[group#3L, sum#7L])
01 +- HashAggregate(keys=[(id#0L % 2) AS (id#0L % 2)#15L], functions=[partial_sum(id#0L)], output=[(id#0L % 2)#15L, sum#17L])
02 +- Range (0, 10, step=1, splits=8)
val hashAggExecRDD = hashAggExec.execute // <-- calls doExecute
scala> println(hashAggExecRDD.toDebugString)
(8) MapPartitionsRDD[3] at execute at <console>:30 []
| MapPartitionsRDD[2] at execute at <console>:30 []
| MapPartitionsRDD[1] at execute at <console>:30 []
| ParallelCollectionRDD[0] at execute at <console>:30 []HashAggregateExec Aggregate Physical Operator for Hash-Based Aggregation
HashAggregateExec is a unary physical operator (i.e. with one child physical operator) for hash-based aggregation that is created (indirectly through AggUtils.createAggregate) when:
-
Aggregation execution planning strategy selects the aggregate physical operator for an Aggregate logical operator
-
Structured Streaming’s
StatefulAggregationStrategystrategy creates plan for streamingEventTimeWatermarkor Aggregate logical operators
|
Note
|
HashAggregateExec is the preferred aggregate physical operator for Aggregation execution planning strategy (over ObjectHashAggregateExec and SortAggregateExec).
|
HashAggregateExec supports Java code generation (aka codegen).
HashAggregateExec uses TungstenAggregationIterator (to iterate over UnsafeRows in partitions) when executed.
| Key | Name (in web UI) | Description | ||
|---|---|---|---|---|
|
aggregate time |
|||
|
avg hash probe |
|
||
|
number of output rows |
Number of groups (per partition) that (depending on the number of partitions and the side of ShuffleExchangeExec operator) is the number of groups
|
||
|
peak memory |
|||
|
spill size |
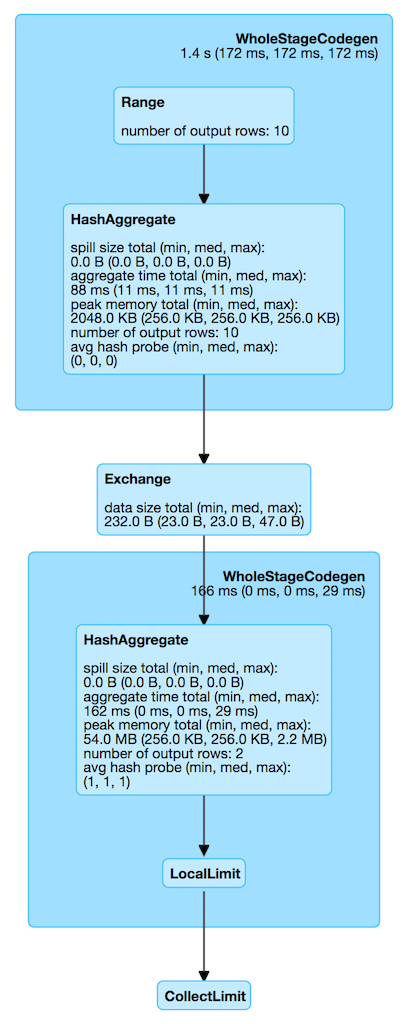
Figure 1. HashAggregateExec in web UI (Details for Query)
| Name | Description |
|---|---|
Output schema for the input NamedExpressions |
requiredChildDistribution varies per the input required child distribution expressions.
| requiredChildDistributionExpressions | Distribution |
|---|---|
Defined, but empty |
|
Non-empty |
ClusteredDistribution for |
Undefined ( |
|
Note
|
(No distinct in aggregation)
(one distinct in aggregation)
FIXME for the following two cases in aggregation with one distinct. |
|
Note
|
The prefix for variable names for HashAggregateExec operators in CodegenSupport-generated code is agg.
|
| Name | Description |
|---|---|
|
All the AttributeReferences of the AggregateFunctions of the AggregateExpressions |
|
Optional pair of numbers for controlled fall-back to a sort-based aggregation when the hash-based approach is unable to acquire enough memory. |
|
DeclarativeAggregate expressions (from the AggregateFunctions of the AggregateExpressions) |
|
StructType built from the aggregateBufferAttributes |
|
StructType built from the groupingAttributes |
|
Attributes of the groupingExpressions |
|
Note
|
See testFallbackStartsAt internal property and spark.sql.TungstenAggregate.testFallbackStartsAt Spark property. Search logs for the following INFO message to know whether the switch has happened. |
finishAggregate Method
finishAggregate(
hashMap: UnsafeFixedWidthAggregationMap,
sorter: UnsafeKVExternalSorter,
peakMemory: SQLMetric,
spillSize: SQLMetric,
avgHashProbe: SQLMetric): KVIterator[UnsafeRow, UnsafeRow]finishAggregate…FIXME
|
Note
|
finishAggregate is used exclusively when HashAggregateExec is requested to generate the Java code for doProduceWithKeys.
|
Generating Java Source Code for Whole-Stage Consume Path with Grouping Keys — doConsumeWithKeys Internal Method
doConsumeWithKeys(ctx: CodegenContext, input: Seq[ExprCode]): StringdoConsumeWithKeys…FIXME
|
Note
|
doConsumeWithKeys is used exclusively when HashAggregateExec is requested to generate the Java code for whole-stage consume path (with named expressions for the grouping keys).
|
Generating Java Source Code for Whole-Stage Consume Path without Grouping Keys — doConsumeWithoutKeys Internal Method
doConsumeWithoutKeys(ctx: CodegenContext, input: Seq[ExprCode]): StringdoConsumeWithoutKeys…FIXME
|
Note
|
doConsumeWithoutKeys is used exclusively when HashAggregateExec is requested to generate the Java code for whole-stage consume path (with no named expressions for the grouping keys).
|
Generating Java Source Code for Consume Path in Whole-Stage Code Generation — doConsume Method
doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String|
Note
|
doConsume is part of CodegenSupport Contract to generate the Java source code for consume path in Whole-Stage Code Generation.
|
doConsume executes doConsumeWithoutKeys when no named expressions for the grouping keys were specified for the HashAggregateExec or doConsumeWithKeys otherwise.
Generating Java Source Code For "produce" Path (In Whole-Stage Code Generation) — doProduceWithKeys Internal Method
doProduceWithKeys(ctx: CodegenContext): StringdoProduceWithKeys…FIXME
|
Note
|
doProduceWithKeys is used exclusively when HashAggregateExec physical operator is requested to generate the Java source code for "produce" path in whole-stage code generation (when there are no groupingExpressions).
|
doProduceWithoutKeys Internal Method
doProduceWithoutKeys(ctx: CodegenContext): StringdoProduceWithoutKeys…FIXME
|
Note
|
doProduceWithoutKeys is used exclusively when HashAggregateExec physical operator is requested to generate the Java source code for "produce" path in whole-stage code generation.
|
generateResultFunction Internal Method
generateResultFunction(ctx: CodegenContext): StringgenerateResultFunction…FIXME
|
Note
|
generateResultFunction is used exclusively when HashAggregateExec physical operator is requested to doProduceWithKeys (when HashAggregateExec physical operator is requested to generate the Java source code for "produce" path in whole-stage code generation)
|
supportsAggregate Object Method
supportsAggregate(aggregateBufferAttributes: Seq[Attribute]): BooleansupportsAggregate firstly creates the schema (from the input aggregation buffer attributes) and requests UnsafeFixedWidthAggregationMap to supportsAggregationBufferSchema (i.e. the schema uses mutable field data types only that have fixed length and can be mutated in place in an UnsafeRow).
|
Note
|
|
Executing Physical Operator (Generating RDD[InternalRow]) — doExecute Method
doExecute(): RDD[InternalRow]|
Note
|
doExecute is part of SparkPlan Contract to generate the runtime representation of a structured query as a distributed computation over internal binary rows on Apache Spark (i.e. RDD[InternalRow]).
|
doExecute requests the child physical operator to execute (that triggers physical query planning and generates an RDD[InternalRow]) and transforms it by executing the following function on internal rows per partition with index (using RDD.mapPartitionsWithIndex that creates another RDD):
-
Records the start execution time (
beforeAgg) -
Requests the
Iterator[InternalRow](from executing the child physical operator) for the next element-
If there is no input (an empty partition), but there are grouping keys used,
doExecutesimply returns an empty iterator -
Otherwise,
doExecutecreates a TungstenAggregationIterator and branches off per whether there are rows to process and the grouping keys.
-
For empty partitions and no grouping keys, doExecute increments the numOutputRows metric and requests the TungstenAggregationIterator to create a single UnsafeRow as the only element of the result iterator.
For non-empty partitions or there are grouping keys used, doExecute returns the TungstenAggregationIterator.
In the end, doExecute calculates the aggTime metric and returns an Iterator[UnsafeRow] that can be as follows:
-
Empty
-
A single-element
Iterator[UnsafeRow]with the single UnsafeRow
|
Note
|
The numOutputRows, peakMemory, spillSize and avgHashProbe metrics are used exclusively to create the TungstenAggregationIterator. |
|
Note
|
|
Generating Java Source Code for Produce Path in Whole-Stage Code Generation — doProduce Method
doProduce(ctx: CodegenContext): String|
Note
|
doProduce is part of CodegenSupport Contract to generate the Java source code for produce path in Whole-Stage Code Generation.
|
doProduce executes doProduceWithoutKeys when no named expressions for the grouping keys were specified for the HashAggregateExec or doProduceWithKeys otherwise.
Creating HashAggregateExec Instance
HashAggregateExec takes the following when created:
-
Required child distribution expressions
-
Named expressions for grouping keys
-
Aggregate attributes
-
Output named expressions
-
Child physical plan
HashAggregateExec initializes the internal registries and counters.
Creating UnsafeFixedWidthAggregationMap Instance — createHashMap Method
createHashMap(): UnsafeFixedWidthAggregationMapcreateHashMap creates a UnsafeFixedWidthAggregationMap (with the empty aggregation buffer, the bufferSchema, the groupingKeySchema, the current TaskMemoryManager, 1024 * 16 initial capacity and the page size of the TaskMemoryManager)
|
Note
|
createHashMap is used exclusively when HashAggregateExec physical operator is requested to generate the Java source code for "produce" path (in Whole-Stage Code Generation).
|