val q = spark.range(10).
groupBy('id % 2 as "group").
agg(sum("id") as "sum")
val execPlan = q.queryExecution.sparkPlan
scala> println(execPlan.numberedTreeString)
00 HashAggregate(keys=[(id#0L % 2)#11L], functions=[sum(id#0L)], output=[group#3L, sum#7L])
01 +- HashAggregate(keys=[(id#0L % 2) AS (id#0L % 2)#11L], functions=[partial_sum(id#0L)], output=[(id#0L % 2)#11L, sum#13L])
02 +- Range (0, 10, step=1, splits=8)
import org.apache.spark.sql.execution.aggregate.HashAggregateExec
val hashAggExec = execPlan.asInstanceOf[HashAggregateExec]
val hashAggExecRDD = hashAggExec.execute
// MapPartitionsRDD is in private[spark] scope
// Use :paste -raw for the following helper object
package org.apache.spark
object AccessPrivateSpark {
import org.apache.spark.rdd.RDD
def mapPartitionsRDD[T](hashAggExecRDD: RDD[T]) = {
import org.apache.spark.rdd.MapPartitionsRDD
hashAggExecRDD.asInstanceOf[MapPartitionsRDD[_, _]]
}
}
// END :paste -raw
import org.apache.spark.AccessPrivateSpark
val mpRDD = AccessPrivateSpark.mapPartitionsRDD(hashAggExecRDD)
val f = mpRDD.iterator(_, _)
import org.apache.spark.sql.execution.aggregate.TungstenAggregationIterator
// FIXME How to show that TungstenAggregationIterator is used?TungstenAggregationIterator — Iterator of UnsafeRows for HashAggregateExec Physical Operator
TungstenAggregationIterator is a AggregationIterator that the HashAggregateExec aggregate physical operator uses when executed (to process UnsafeRows per partition and calculate aggregations).
TungstenAggregationIterator prefers hash-based aggregation (before switching to sort-based aggregation).
When created, TungstenAggregationIterator gets SQL metrics from the HashAggregateExec aggregate physical operator being executed, i.e. numOutputRows, peakMemory, spillSize and avgHashProbe metrics.
-
numOutputRows is used when
TungstenAggregationIteratoris requested for the next UnsafeRow (and it has one) -
peakMemory, spillSize and avgHashProbe are used at the end of every task (one per partition)
The metrics are then displayed as part of HashAggregateExec aggregate physical operator (e.g. in web UI in Details for Query).
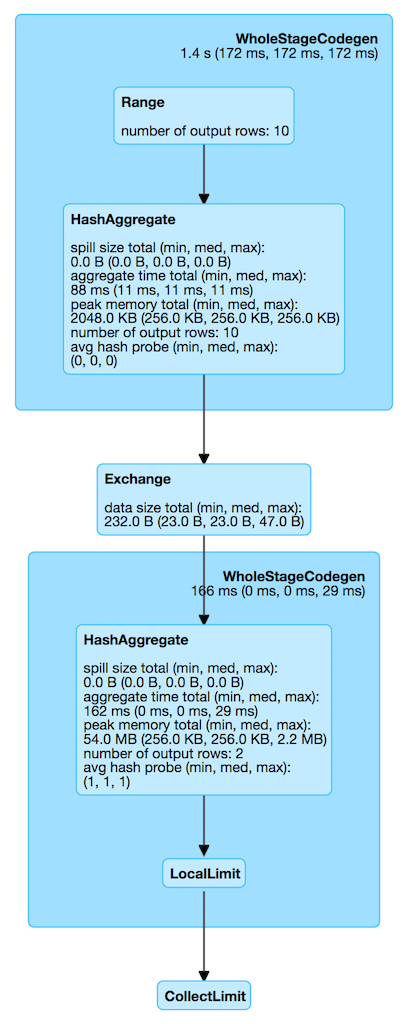
Figure 1. HashAggregateExec in web UI (Details for Query)
| Name | Description |
|---|---|
|
Used when…FIXME |
|
UnsafeFixedWidthAggregationMap with the following:
Used when |
|
UnsafeRow that is the aggregation buffer containing initial buffer values. Used when…FIXME |
|
|
|
Flag to indicate whether
Enabled ( Used when…FIXME |
processInputs Internal Method
processInputs(fallbackStartsAt: (Int, Int)): UnitprocessInputs…FIXME
|
Note
|
processInputs is used exclusively when TungstenAggregationIterator is created (and sets the internal flags to indicate whether to use a hash-based aggregation or, in the worst case, a sort-based aggregation when there is not enough memory for groups and their buffers).
|
Switching to Sort-Based Aggregation (From Preferred Hash-Based Aggregation) — switchToSortBasedAggregation Internal Method
switchToSortBasedAggregation(): UnitswitchToSortBasedAggregation…FIXME
|
Note
|
switchToSortBasedAggregation is used exclusively when TungstenAggregationIterator is requested to processInputs (and the externalSorter is used).
|
Getting Next UnsafeRow — next Method
next(): UnsafeRow|
Note
|
next is part of Scala’s scala.collection.Iterator interface that returns the next element and discards it from the iterator.
|
next…FIXME
hasNext Method
hasNext: Boolean|
Note
|
hasNext is part of Scala’s scala.collection.Iterator interface that tests whether this iterator can provide another element.
|
hasNext…FIXME
Creating TungstenAggregationIterator Instance
TungstenAggregationIterator takes the following when created:
-
Grouping named expressions
-
Aggregate attributes
-
Output named expressions
-
Function to create a new
MutableProjectiongiven Catalyst expressions and attributes (i.e.(Seq[Expression], Seq[Attribute]) ⇒ MutableProjection) -
Output attributes (of the child of the HashAggregateExec physical operator)
-
Iterator of InternalRows (from a single partition of the child of the HashAggregateExec physical operator)
-
(used for testing) Optional
HashAggregateExec's testFallbackStartsAt -
numOutputRowsSQLMetric -
peakMemorySQLMetric -
spillSizeSQLMetric -
avgHashProbeSQLMetric
|
Note
|
The SQL metrics (numOutputRows, peakMemory, spillSize and avgHashProbe) belong to the HashAggregateExec physical operator that created the TungstenAggregationIterator.
|
TungstenAggregationIterator initializes the internal registries and counters.
TungstenAggregationIterator starts processing input rows and pre-loads the first key-value pair from the UnsafeFixedWidthAggregationMap if did not switch to sort-based aggregation.
generateResultProjection Method
generateResultProjection(): (UnsafeRow, InternalRow) => UnsafeRow|
Note
|
generateResultProjection is part of the AggregationIterator Contract to…FIXME.
|
generateResultProjection…FIXME
Creating UnsafeRow — outputForEmptyGroupingKeyWithoutInput Method
outputForEmptyGroupingKeyWithoutInput(): UnsafeRowoutputForEmptyGroupingKeyWithoutInput…FIXME
|
Note
|
outputForEmptyGroupingKeyWithoutInput is used when…FIXME
|