// Sample DataFrames
val tokens = Seq(
(0, "playing"),
(1, "with"),
(2, "InMemoryTableScanExec")
).toDF("id", "token")
val ids = spark.range(10)
// Cache DataFrames
tokens.cache
ids.cache
val q = tokens.join(ids, Seq("id"), "outer")
scala> q.explain
== Physical Plan ==
*Project [coalesce(cast(id#5 as bigint), id#10L) AS id#33L, token#6]
+- SortMergeJoin [cast(id#5 as bigint)], [id#10L], FullOuter
:- *Sort [cast(id#5 as bigint) ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(cast(id#5 as bigint), 200)
: +- InMemoryTableScan [id#5, token#6]
: +- InMemoryRelation [id#5, token#6], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
: +- LocalTableScan [id#5, token#6]
+- *Sort [id#10L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id#10L, 200)
+- InMemoryTableScan [id#10L]
+- InMemoryRelation [id#10L], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas)
+- *Range (0, 10, step=1, splits=8)InMemoryTableScanExec Leaf Physical Operator
InMemoryTableScanExec is a leaf physical operator that represents an InMemoryRelation logical operator at execution time.
InMemoryTableScanExec is created exclusively when InMemoryScans execution planning strategy is executed and finds an InMemoryRelation logical operator in a logical query plan.
InMemoryTableScanExec takes the following to be created:
-
Attribute expressions
-
Predicate expressions
-
InMemoryRelation logical operator
InMemoryTableScanExec is a ColumnarBatchScan that supports batch decoding (when created for a DataSourceReader that supports it, i.e. the DataSourceReader is a SupportsScanColumnarBatch with the enableBatchRead flag enabled).
InMemoryTableScanExec supports partition batch pruning (only when spark.sql.inMemoryColumnarStorage.partitionPruning internal configuration property is enabled which is so by default).
val q = spark.range(4).cache
val plan = q.queryExecution.executedPlan
import org.apache.spark.sql.execution.columnar.InMemoryTableScanExec
val inmemoryScan = plan.collectFirst { case exec: InMemoryTableScanExec => exec }.get
assert(inmemoryScan.supportCodegen == inmemoryScan.supportsBatch)| Key | Name (in web UI) | Description |
|---|---|---|
number of output rows |
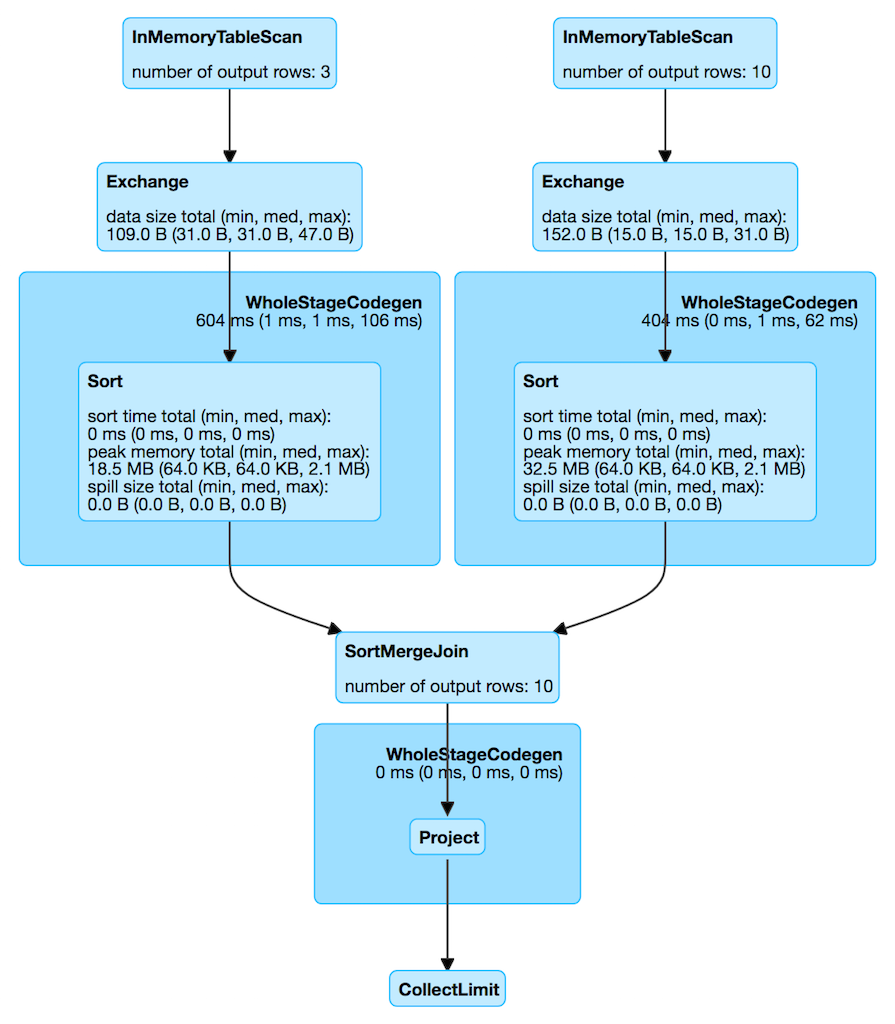
Figure 1. InMemoryTableScanExec in web UI (Details for Query)
InMemoryTableScanExec supports Java code generation only if batch decoding is enabled.
InMemoryTableScanExec gives the single inputRDD as the only RDD of internal rows (when WholeStageCodegenExec physical operator is executed).
InMemoryTableScanExec uses spark.sql.inMemoryTableScanStatistics.enable flag (default: false) to enable accumulators (that seems to be exclusively for testing purposes).
| Name | Description |
|---|---|
Schema of a columnar batch Used exclusively when |
|
PartitionStatistics of the InMemoryRelation Used when |
vectorTypes Method
vectorTypes: Option[Seq[String]]|
Note
|
vectorTypes is part of ColumnarBatchScan Contract to…FIXME.
|
vectorTypes uses spark.sql.columnVector.offheap.enabled internal configuration property to select the name of the concrete column vector, i.e. OnHeapColumnVector or OffHeapColumnVector when the property is off or on, respectively.
vectorTypes gives as many column vectors as the attribute expressions.
supportsBatch Property
supportsBatch: Boolean|
Note
|
supportsBatch is part of ColumnarBatchScan Contract to control whether the physical operator supports vectorized decoding or not.
|
supportsBatch is enabled when all of the following holds:
-
spark.sql.inMemoryColumnarStorage.enableVectorizedReader configuration property is enabled (default:
true) -
The output schema of the InMemoryRelation uses primitive data types only, i.e. BooleanType, ByteType, ShortType, IntegerType, LongType, FloatType, DoubleType
-
The number of nested fields in the output schema of the InMemoryRelation is at most spark.sql.codegen.maxFields internal configuration property
partitionFilters Property
partitionFilters: Seq[Expression]|
Note
|
partitionFilters is a Scala lazy value which is computed once when accessed and cached afterwards.
|
partitionFilters…FIXME
|
Note
|
partitionFilters is used when…FIXME
|
Applying Partition Batch Pruning to Cached Column Buffers (Creating MapPartitionsRDD of Filtered CachedBatches) — filteredCachedBatches Internal Method
filteredCachedBatches(): RDD[CachedBatch]filteredCachedBatches requests PartitionStatistics for the output schema and InMemoryRelation for cached column buffers (as a RDD[CachedBatch]).
filteredCachedBatches takes the cached column buffers (as a RDD[CachedBatch]) and transforms the RDD per partition with index (i.e. RDD.mapPartitionsWithIndexInternal) as follows:
-
Creates a partition filter as a new GenPredicate for the partitionFilters expressions (concatenated together using
Andbinary operator and the schema) -
Requests the generated partition filter
Predicatetoinitialize -
Uses spark.sql.inMemoryColumnarStorage.partitionPruning internal configuration property to enable partition batch pruning and filtering out (skipping)
CachedBatchesin a partition based on column stats and the generated partition filterPredicate
|
Note
|
If spark.sql.inMemoryColumnarStorage.partitionPruning internal configuration property is disabled (i.e. false), filteredCachedBatches does nothing and simply passes all CachedBatch elements along.
|
|
Note
|
spark.sql.inMemoryColumnarStorage.partitionPruning internal configuration property is enabled by default. |
|
Note
|
filteredCachedBatches is used exclusively when InMemoryTableScanExec is requested for the inputRDD internal property.
|
createAndDecompressColumn Internal Method
createAndDecompressColumn(cachedColumnarBatch: CachedBatch): ColumnarBatchcreateAndDecompressColumn takes the number of rows in the input CachedBatch.
createAndDecompressColumn requests OffHeapColumnVector or OnHeapColumnVector to allocate column vectors (with the number of rows and columnarBatchSchema) per the spark.sql.columnVector.offheap.enabled internal configuration flag, i.e. true or false, respectively.
|
Note
|
spark.sql.columnVector.offheap.enabled internal configuration flag is disabled by default which means that OnHeapColumnVector is used. |
createAndDecompressColumn creates a ColumnarBatch for the allocated column vectors (as an array of ColumnVector).
createAndDecompressColumn sets the number of rows in the columnar batch.
For every Attribute createAndDecompressColumn requests ColumnAccessor to decompress the column.
createAndDecompressColumn registers a callback to be executed on a task completion that will close the ColumnarBatch.
In the end, createAndDecompressColumn returns the ColumnarBatch.
|
Note
|
createAndDecompressColumn is used exclusively when InMemoryTableScanExec is requested for the input RDD of internal rows.
|
Creating Input RDD of Internal Rows — inputRDD Internal Property
inputRDD: RDD[InternalRow]|
Note
|
inputRDD is a Scala lazy value which is computed once when accessed and cached afterwards.
|
inputRDD firstly applies partition batch pruning to cached column buffers (and creates a filtered cached batches as a RDD[CachedBatch]).
With supportsBatch flag on, inputRDD finishes with a new MapPartitionsRDD (using RDD.map) by createAndDecompressColumn on all cached columnar batches.
|
Caution
|
Show examples of supportsBatch enabled and disabled |
// Demo: A MapPartitionsRDD in the RDD lineage
val q = spark.range(4).cache
val plan = q.queryExecution.executedPlan
import org.apache.spark.sql.execution.columnar.InMemoryTableScanExec
val inmemoryScan = plan.collectFirst { case exec: InMemoryTableScanExec => exec }.get
// supportsBatch flag is on since the schema is a single column of longs
assert(inmemoryScan.supportsBatch)
val rdd = inmemoryScan.inputRDDs.head
scala> rdd.toDebugString
res2: String =
(8) MapPartitionsRDD[5] at inputRDDs at <console>:27 []
| MapPartitionsRDD[4] at inputRDDs at <console>:27 []
| *(1) Range (0, 4, step=1, splits=8)
MapPartitionsRDD[3] at cache at <console>:23 []
| MapPartitionsRDD[2] at cache at <console>:23 []
| MapPartitionsRDD[1] at cache at <console>:23 []
| ParallelCollectionRDD[0] at cache at <console>:23 []With supportsBatch flag off, inputRDD firstly applies partition batch pruning to cached column buffers (and creates a filtered cached batches as a RDD[CachedBatch]).
|
Note
|
Indeed. inputRDD applies partition batch pruning to cached column buffers (and creates a filtered cached batches as a RDD[CachedBatch]) twice which seems unnecessary.
|
In the end, inputRDD creates a new MapPartitionsRDD (using RDD.map) with a ColumnarIterator applied to all cached columnar batches that is created as follows:
-
For every
CachedBatchin the partition iterator adds the total number of rows in the batch to numOutputRows SQL metric -
Requests
GenerateColumnAccessorto generate the Java code for aColumnarIteratorto perform expression evaluation for the given column types. -
Requests
ColumnarIteratorto initialize
// Demo: A MapPartitionsRDD in the RDD lineage (supportsBatch flag off)
import java.sql.Date
import java.time.LocalDate
val q = Seq(Date.valueOf(LocalDate.now)).toDF("date").cache
val plan = q.queryExecution.executedPlan
import org.apache.spark.sql.execution.columnar.InMemoryTableScanExec
val inmemoryScan = plan.collectFirst { case exec: InMemoryTableScanExec => exec }.get
// supportsBatch flag is off since the schema uses java.sql.Date
assert(inmemoryScan.supportsBatch == false)
val rdd = inmemoryScan.inputRDDs.head
scala> rdd.toDebugString
res2: String =
(1) MapPartitionsRDD[12] at inputRDDs at <console>:28 []
| MapPartitionsRDD[11] at inputRDDs at <console>:28 []
| LocalTableScan [date#15]
MapPartitionsRDD[9] at cache at <console>:25 []
| MapPartitionsRDD[8] at cache at <console>:25 []
| ParallelCollectionRDD[7] at cache at <console>:25 []|
Note
|
inputRDD is used when InMemoryTableScanExec is requested for the input RDDs and to execute.
|
Executing Physical Operator (Generating RDD[InternalRow]) — doExecute Method
doExecute(): RDD[InternalRow]|
Note
|
doExecute is part of SparkPlan Contract to generate the runtime representation of a structured query as a distributed computation over internal binary rows on Apache Spark (i.e. RDD[InternalRow]).
|
doExecute branches off per supportsBatch flag.
With supportsBatch flag on, doExecute creates a WholeStageCodegenExec (with the InMemoryTableScanExec physical operator as the child and codegenStageId as 0) and requests it to execute.
Otherwise, when supportsBatch flag is off, doExecute simply gives the input RDD of internal rows.
buildFilter Property
buildFilter: PartialFunction[Expression, Expression]|
Note
|
buildFilter is a Scala lazy value which is computed once when accessed and cached afterwards.
|
buildFilter is a Scala PartialFunction that accepts an Expression and produces an Expression, i.e. PartialFunction[Expression, Expression].
| Input Expression | Description |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
For every In the end, |
|
Note
|
buildFilter is used exclusively when InMemoryTableScanExec is requested for partitionFilters.
|
innerChildren Method
innerChildren: Seq[QueryPlan[_]]|
Note
|
innerChildren is part of QueryPlan Contract to…FIXME.
|
innerChildren…FIXME