JDBCRelation([table]) [numPartitions=[number]]JDBCRelation — Relation with Inserting or Overwriting Data, Column Pruning and Filter Pushdown
JDBCRelation is a BaseRelation that supports inserting or overwriting data and column pruning with filter pushdown.
As a BaseRelation, JDBCRelation defines the schema of tuples (data) and the SQLContext.
As a InsertableRelation, JDBCRelation supports inserting or overwriting data.
As a PrunedFilteredScan, JDBCRelation supports building distributed data scan with column pruning and filter pushdown.
JDBCRelation is created when:
-
DataFrameReaderis requested to load data from an external table using JDBC data source -
JdbcRelationProvideris requested to create a BaseRelation for reading data from a JDBC table
When requested for a human-friendly text representation, JDBCRelation requests the JDBCOptions for the name of the table and the number of partitions (if defined).
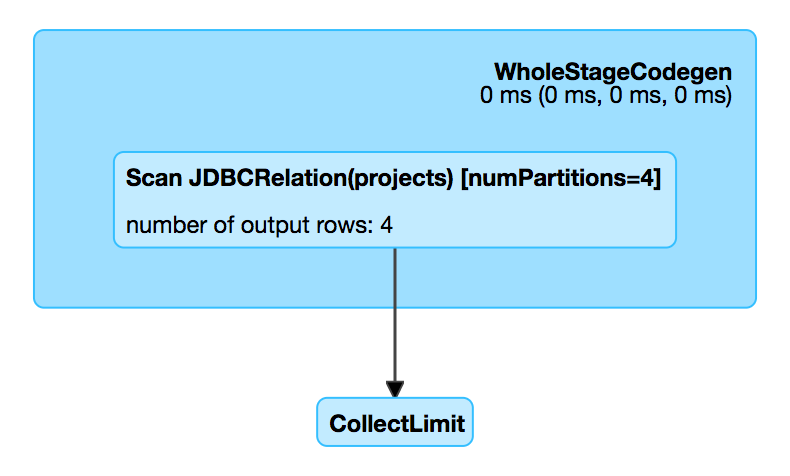
Figure 1. JDBCRelation in web UI (Details for Query)
scala> df.explain
== Physical Plan ==
*Scan JDBCRelation(projects) [numPartitions=1] [id#0,name#1,website#2] ReadSchema: struct<id:int,name:string,website:string>JDBCRelation uses the SparkSession to return a SQLContext.
JDBCRelation turns the needConversion flag off (to announce that buildScan returns an RDD[InternalRow] already and DataSourceStrategy execution planning strategy does not have to do the RDD conversion).
Finding Unhandled Filter Predicates — unhandledFilters Method
unhandledFilters(filters: Array[Filter]): Array[Filter]|
Note
|
unhandledFilters is part of BaseRelation Contract to find unhandled Filter predicates.
|
unhandledFilters returns the Filter predicates in the input filters that could not be converted to a SQL expression (and are therefore unhandled by the JDBC data source natively).
Schema of Tuples (Data) — schema Property
schema: StructType|
Note
|
schema is part of BaseRelation Contract to return the schema of the tuples in a relation.
|
schema uses JDBCRDD to resolveTable given the JDBCOptions (that simply returns the Catalyst schema of the table, also known as the default table schema).
If customSchema JDBC option was defined, schema uses JdbcUtils to replace the data types in the default table schema.
Inserting or Overwriting Data to JDBC Table — insert Method
insert(data: DataFrame, overwrite: Boolean): Unit|
Note
|
insert is part of InsertableRelation Contract that inserts or overwrites data in a relation.
|
insert simply requests the input DataFrame for a DataFrameWriter that in turn is requested to save the data to a table using the JDBC data source (itself!) with the url, table and all options.
insert also requests the DataFrameWriter to set the save mode as Overwrite or Append per the input overwrite flag.
|
Note
|
insert uses a "trick" to reuse a code that is responsible for saving data to a JDBC table.
|
Building Distributed Data Scan with Column Pruning and Filter Pushdown — buildScan Method
buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row]|
Note
|
buildScan is part of PrunedFilteredScan Contract to build a distributed data scan (as a RDD[Row]) with support for column pruning and filter pushdown.
|
buildScan uses the JDBCRDD object to create a RDD[Row] for a distributed data scan.