// Create a bucketed data source table
// It is one of the most complex examples of a LogicalRelation with a HadoopFsRelation
val tableName = "bucketed_4_id"
spark
.range(100)
.withColumn("part", $"id" % 2)
.write
.partitionBy("part")
.bucketBy(4, "id")
.sortBy("id")
.mode("overwrite")
.saveAsTable(tableName)
val q = spark.table(tableName)
val sparkPlan = q.queryExecution.executedPlan
scala> :type sparkPlan
org.apache.spark.sql.execution.SparkPlan
scala> println(sparkPlan.numberedTreeString)
00 *(1) FileScan parquet default.bucketed_4_id[id#7L,part#8L] Batched: true, Format: Parquet, Location: CatalogFileIndex[file:/Users/jacek/dev/oss/spark/spark-warehouse/bucketed_4_id], PartitionCount: 2, PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:bigint>, SelectedBucketsCount: 4 out of 4
import org.apache.spark.sql.execution.FileSourceScanExec
val scan = sparkPlan.collectFirst { case exec: FileSourceScanExec => exec }.get
scala> :type scan
org.apache.spark.sql.execution.FileSourceScanExec
scala> scan.metadata.toSeq.sortBy(_._1).map { case (k, v) => s"$k -> $v" }.foreach(println)
Batched -> true
Format -> Parquet
Location -> CatalogFileIndex[file:/Users/jacek/dev/oss/spark/spark-warehouse/bucketed_4_id]
PartitionCount -> 2
PartitionFilters -> []
PushedFilters -> []
ReadSchema -> struct<id:bigint>
SelectedBucketsCount -> 4 out of 4FileSourceScanExec Leaf Physical Operator
FileSourceScanExec is a leaf physical operator (being a DataSourceScanExec) that represents a scan over collections of files (incl. Hive tables).
FileSourceScanExec is created exclusively for a LogicalRelation logical operator with a HadoopFsRelation when FileSourceStrategy execution planning strategy is executed.
FileSourceScanExec uses the single input RDD as the input RDDs (in Whole-Stage Java Code Generation).
When executed, FileSourceScanExec operator creates a FileScanRDD (for bucketed and non-bucketed reads).
scala> :type scan
org.apache.spark.sql.execution.FileSourceScanExec
val rdd = scan.execute
scala> println(rdd.toDebugString)
(6) MapPartitionsRDD[7] at execute at <console>:28 []
| FileScanRDD[2] at execute at <console>:27 []
import org.apache.spark.sql.execution.datasources.FileScanRDD
assert(rdd.dependencies.head.rdd.isInstanceOf[FileScanRDD])FileSourceScanExec supports bucket pruning so it only scans the bucket files required for a query.
scala> :type scan
org.apache.spark.sql.execution.FileSourceScanExec
import org.apache.spark.sql.execution.datasources.FileScanRDD
val rdd = scan.inputRDDs.head.asInstanceOf[FileScanRDD]
import org.apache.spark.sql.execution.datasources.FilePartition
val bucketFiles = for {
FilePartition(bucketId, files) <- rdd.filePartitions
f <- files
} yield s"Bucket $bucketId => $f"
scala> println(bucketFiles.size)
51
scala> bucketFiles.foreach(println)
Bucket 0 => path: file:///Users/jacek/dev/oss/spark/spark-warehouse/bucketed_4_id/part=0/part-00004-5301d371-01c3-47d4-bb6b-76c3c94f3699_00000.c000.snappy.parquet, range: 0-423, partition values: [0]
Bucket 0 => path: file:///Users/jacek/dev/oss/spark/spark-warehouse/bucketed_4_id/part=0/part-00001-5301d371-01c3-47d4-bb6b-76c3c94f3699_00000.c000.snappy.parquet, range: 0-423, partition values: [0]
...
Bucket 3 => path: file:///Users/jacek/dev/oss/spark/spark-warehouse/bucketed_4_id/part=1/part-00005-5301d371-01c3-47d4-bb6b-76c3c94f3699_00003.c000.snappy.parquet, range: 0-423, partition values: [1]
Bucket 3 => path: file:///Users/jacek/dev/oss/spark/spark-warehouse/bucketed_4_id/part=1/part-00000-5301d371-01c3-47d4-bb6b-76c3c94f3699_00003.c000.snappy.parquet, range: 0-431, partition values: [1]
Bucket 3 => path: file:///Users/jacek/dev/oss/spark/spark-warehouse/bucketed_4_id/part=1/part-00007-5301d371-01c3-47d4-bb6b-76c3c94f3699_00003.c000.snappy.parquet, range: 0-423, partition values: [1]FileSourceScanExec uses a HashPartitioning or the default UnknownPartitioning as the output partitioning scheme.
FileSourceScanExec is a ColumnarBatchScan and supports batch decoding only when the FileFormat (of the HadoopFsRelation) supports it.
FileSourceScanExec supports data source filters that are printed out to the console (at INFO logging level) and available as metadata (e.g. in web UI or explain).
Pushed Filters: [pushedDownFilters]| Key | Name (in web UI) | Description |
|---|---|---|
|
metadata time (ms) |
|
|
number of files |
|
|
number of output rows |
|
|
scan time |
As a DataSourceScanExec, FileSourceScanExec uses Scan for the prefix of the node name.
val fileScanExec: FileSourceScanExec = ... // see the example earlier
assert(fileScanExec.nodeName startsWith "Scan")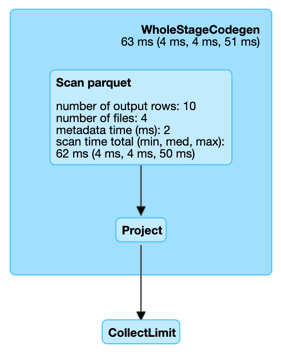
Figure 1. FileSourceScanExec in web UI (Details for Query)
FileSourceScanExec uses File for nodeNamePrefix (that is used for the simple node description in query plans).
val fileScanExec: FileSourceScanExec = ... // see the example earlier
assert(fileScanExec.nodeNamePrefix == "File")
scala> println(fileScanExec.simpleString)
FileScan csv [id#20,name#21,city#22] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/Users/jacek/dev/oss/datasets/people.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:string,name:string,city:string>| Name | Description | ||
|---|---|---|---|
|
|||
|
Data source filters that are dataFilters expressions converted to their respective filters
|
|
Tip
|
Enable Add the following line to Refer to Logging. |
Creating RDD for Non-Bucketed Reads — createNonBucketedReadRDD Internal Method
createNonBucketedReadRDD(
readFile: (PartitionedFile) => Iterator[InternalRow],
selectedPartitions: Seq[PartitionDirectory],
fsRelation: HadoopFsRelation): RDD[InternalRow]createNonBucketedReadRDD calculates the maximum size of partitions (maxSplitBytes) based on the following properties:
-
spark.sql.files.maxPartitionBytes (default:
128m) -
spark.sql.files.openCostInBytes (default:
4m)
createNonBucketedReadRDD sums up the size of all the files (with the extra spark.sql.files.openCostInBytes) for the given selectedPartitions and divides the sum by the "default parallelism" (i.e. number of CPU cores assigned to a Spark application) that gives bytesPerCore.
The maximum size of partitions is then the minimum of spark.sql.files.maxPartitionBytes and the bigger of spark.sql.files.openCostInBytes and the bytesPerCore.
createNonBucketedReadRDD prints out the following INFO message to the logs:
Planning scan with bin packing, max size: [maxSplitBytes] bytes, open cost is considered as scanning [openCostInBytes] bytes.For every file (as Hadoop’s FileStatus) in every partition (as PartitionDirectory in the given selectedPartitions), createNonBucketedReadRDD gets the HDFS block locations to create PartitionedFiles (possibly split per the maximum size of partitions if the FileFormat of the HadoopFsRelation is splittable). The partitioned files are then sorted by number of bytes to read (aka split size) in decreasing order (from the largest to the smallest).
createNonBucketedReadRDD "compresses" multiple splits per partition if together they are smaller than the maxSplitBytes ("Next Fit Decreasing") that gives the necessary partitions (file blocks as FilePartitions).
In the end, createNonBucketedReadRDD creates a FileScanRDD (with the given (PartitionedFile) ⇒ Iterator[InternalRow] read function and the partitions).
|
Note
|
createNonBucketedReadRDD is used exclusively when FileSourceScanExec physical operator is requested for the input RDD (and neither the optional bucketing specification of the HadoopFsRelation is defined nor bucketing is enabled).
|
selectedPartitions Internal Lazily-Initialized Property
selectedPartitions: Seq[PartitionDirectory]selectedPartitions…FIXME
|
Note
|
|
Creating FileSourceScanExec Instance
FileSourceScanExec takes the following when created:
-
Output schema attributes
-
partitionFiltersexpressions -
dataFiltersexpressions
FileSourceScanExec initializes the internal registries and counters.
Output Partitioning Scheme — outputPartitioning Attribute
outputPartitioning: Partitioning|
Note
|
outputPartitioning is part of the SparkPlan Contract to specify output data partitioning.
|
outputPartitioning can be one of the following:
-
HashPartitioning (with the bucket column names and the number of buckets of the bucketing specification of the HadoopFsRelation) when bucketing is enabled and the HadoopFsRelation has a bucketing specification defined
-
UnknownPartitioning (with
0partitions) otherwise
Creating FileScanRDD with Bucketing Support — createBucketedReadRDD Internal Method
createBucketedReadRDD(
bucketSpec: BucketSpec,
readFile: (PartitionedFile) => Iterator[InternalRow],
selectedPartitions: Seq[PartitionDirectory],
fsRelation: HadoopFsRelation): RDD[InternalRow]createBucketedReadRDD prints the following INFO message to the logs:
Planning with [numBuckets] bucketscreateBucketedReadRDD maps the available files of the input selectedPartitions into PartitionedFiles. For every file, createBucketedReadRDD getBlockLocations and getBlockHosts.
createBucketedReadRDD then groups the PartitionedFiles by bucket ID.
|
Note
|
Bucket ID is of the format _0000n, i.e. the bucket ID prefixed with up to four 0s.
|
createBucketedReadRDD prunes (filters out) the bucket files for the bucket IDs that are not listed in the bucket IDs for bucket pruning.
createBucketedReadRDD creates a FilePartition (file block) for every bucket ID and the (pruned) bucket PartitionedFiles.
In the end, createBucketedReadRDD creates a FileScanRDD (with the input readFile for the read function and the file blocks (FilePartitions) for every bucket ID for partitions)
|
Tip
|
Use |
|
Note
|
createBucketedReadRDD is used exclusively when FileSourceScanExec physical operator is requested for the inputRDD (and the optional bucketing specification of the HadoopFsRelation is defined and bucketing is enabled).
|
supportsBatch Attribute
supportsBatch: Boolean|
Note
|
supportsBatch is part of the ColumnarBatchScan Contract to enable vectorized decoding.
|
supportsBatch is enabled (true) only when the FileFormat (of the HadoopFsRelation) supports vectorized decoding. Otherwise, supportsBatch is disabled (i.e. false).
|
Note
|
FileFormat does not support vectorized decoding by default (i.e. supportBatch flag is disabled). Only ParquetFileFormat and OrcFileFormat have support for it under certain conditions. |
FileSourceScanExec As ColumnarBatchScan
FileSourceScanExec is a ColumnarBatchScan and supports batch decoding only when the FileFormat (of the HadoopFsRelation) supports it.
FileSourceScanExec has needsUnsafeRowConversion flag enabled for ParquetFileFormat data sources exclusively.
FileSourceScanExec has vectorTypes…FIXME
needsUnsafeRowConversion Flag
needsUnsafeRowConversion: Boolean|
Note
|
needsUnsafeRowConversion is part of ColumnarBatchScan Contract to control the name of the variable for an input row while generating the Java source code to consume generated columns or row from a physical operator.
|
needsUnsafeRowConversion is enabled (i.e. true) when the following conditions all hold:
-
FileFormat of the HadoopFsRelation is ParquetFileFormat
-
spark.sql.parquet.enableVectorizedReader configuration property is enabled (default:
true)
Otherwise, needsUnsafeRowConversion is disabled (i.e. false).
|
Note
|
needsUnsafeRowConversion is used when FileSourceScanExec is executed (and supportsBatch flag is off).
|
Fully-Qualified Class Names (Types) of Concrete ColumnVectors — vectorTypes Method
vectorTypes: Option[Seq[String]]|
Note
|
vectorTypes is part of ColumnarBatchScan Contract to..FIXME.
|
vectorTypes simply requests the FileFormat of the HadoopFsRelation for vectorTypes.
Executing Physical Operator (Generating RDD[InternalRow]) — doExecute Method
doExecute(): RDD[InternalRow]|
Note
|
doExecute is part of the SparkPlan Contract to generate the runtime representation of a structured query as a distributed computation over internal binary rows on Apache Spark (i.e. RDD[InternalRow]).
|
doExecute branches off per supportsBatch flag.
|
Note
|
supportsBatch flag can be enabled for ParquetFileFormat and OrcFileFormat built-in file formats (under certain conditions). |
With supportsBatch flag enabled, doExecute creates a WholeStageCodegenExec physical operator (with the FileSourceScanExec for the child physical operator and codegenStageId as 0) and executes it right after.
With supportsBatch flag disabled, doExecute creates an unsafeRows RDD to scan over which is different per needsUnsafeRowConversion flag.
If needsUnsafeRowConversion flag is on, doExecute takes the inputRDD and creates a new RDD by applying a function to each partition (using RDD.mapPartitionsWithIndexInternal):
-
Creates a UnsafeProjection for the schema
-
Initializes the UnsafeProjection
-
Maps over the rows in a partition iterator using the
UnsafeProjectionprojection
Otherwise, doExecute simply takes the inputRDD as the unsafeRows RDD (with no changes).
doExecute takes the numOutputRows metric and creates a new RDD by mapping every element in the unsafeRows and incrementing the numOutputRows metric.
|
Tip
|
Use With supportsBatch off and needsUnsafeRowConversion on you should see two more RDDs in the RDD lineage. |
Creating Input RDD of Internal Rows — inputRDD Internal Property
inputRDD: RDD[InternalRow]|
Note
|
inputRDD is a Scala lazy value which is computed once when accessed and cached afterwards.
|
inputRDD is an input RDD of internal binary rows (i.e. InternalRow) that is used when FileSourceScanExec physical operator is requested for inputRDDs and execution.
When created, inputRDD requests HadoopFsRelation to get the underlying FileFormat that is in turn requested to build a data reader with partition column values appended (with the input parameters from the properties of HadoopFsRelation and pushedDownFilters).
In case HadoopFsRelation has bucketing specification defined and bucketing support is enabled, inputRDD creates a FileScanRDD with bucketing (with the bucketing specification, the reader, selectedPartitions and the HadoopFsRelation itself). Otherwise, inputRDD createNonBucketedReadRDD.
|
Note
|
createBucketedReadRDD accepts a bucketing specification while createNonBucketedReadRDD does not. |
Output Data Ordering — outputOrdering Attribute
outputOrdering: Seq[SortOrder]|
Note
|
outputOrdering is part of the SparkPlan Contract to specify output data ordering.
|
outputOrdering is a SortOrder expression for every sort column in Ascending order only when all the following hold:
-
HadoopFsRelation has a bucketing specification defined
-
All the buckets have a single file in it
Otherwise, outputOrdering is simply empty (Nil).
updateDriverMetrics Internal Method
updateDriverMetrics(): UnitupdateDriverMetrics updates the following performance metrics:
-
numFiles metric with the total of all the sizes of the files in the selectedPartitions
-
metadataTime metric with the time spent in the selectedPartitions
In the end, updateDriverMetrics requests the SQLMetrics object to posts the metric updates.
|
Note
|
updateDriverMetrics is used exclusively when FileSourceScanExec physical operator is requested for the input RDD (the very first time).
|
getBlockLocations Internal Method
getBlockLocations(file: FileStatus): Array[BlockLocation]getBlockLocations simply requests the given Hadoop FileStatus for the block locations (getBlockLocations) if it is a Hadoop LocatedFileStatus. Otherwise, getBlockLocations returns an empty array.
|
Note
|
getBlockLocations is used when FileSourceScanExec physical operator is requested to createBucketedReadRDD and createNonBucketedReadRDD.
|