Dataset — Structured Query with Data Encoder
Dataset is a strongly-typed data structure in Spark SQL that represents a structured query.
|
Note
|
A structured query can be written using SQL or Dataset API. |
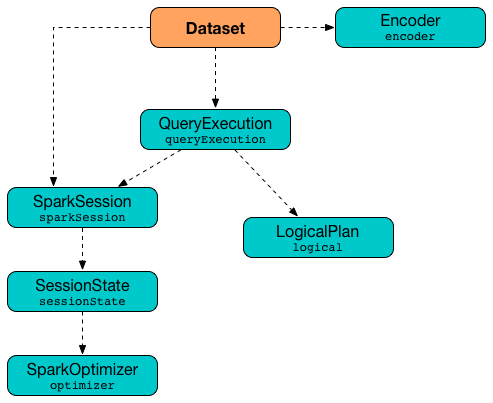
The following figure shows the relationship between different entities of Spark SQL that all together give the Dataset data structure.
Figure 1. Dataset’s Internals
It is therefore fair to say that Dataset consists of the following three elements:
-
QueryExecution (with the parsed unanalyzed LogicalPlan of a structured query)
-
Encoder (of the type of the records for fast serialization and deserialization to and from InternalRow)
When created, Dataset takes such a 3-element tuple with a SparkSession, a QueryExecution and an Encoder.
Dataset is created when:
-
Dataset.apply (for a LogicalPlan and a SparkSession with the Encoder in a Scala implicit scope)
-
Dataset.ofRows (for a LogicalPlan and a SparkSession)
-
Dataset.toDF untyped transformation is used
-
Dataset.select, Dataset.randomSplit and Dataset.mapPartitions typed transformations are used
-
KeyValueGroupedDataset.agg operator is used (that requests
KeyValueGroupedDatasetto aggUntyped) -
SparkSession.emptyDataset and SparkSession.range operators are used
-
CatalogImplis requested to makeDataset (when requested to list databases, tables, functions and columns) -
Spark Structured Streaming’s
MicroBatchExecutionis requested torunBatch
Datasets are lazy and structured query operators and expressions are only triggered when an action is invoked.
import org.apache.spark.sql.SparkSession
val spark: SparkSession = ...
scala> val dataset = spark.range(5)
dataset: org.apache.spark.sql.Dataset[Long] = [id: bigint]
// Variant 1: filter operator accepts a Scala function
dataset.filter(n => n % 2 == 0).count
// Variant 2: filter operator accepts a Column-based SQL expression
dataset.filter('value % 2 === 0).count
// Variant 3: filter operator accepts a SQL query
dataset.filter("value % 2 = 0").countThe Dataset API offers declarative and type-safe operators that makes for an improved experience for data processing (comparing to DataFrames that were a set of index- or column name-based Rows).
|
Note
|
As of Spark 2.0.0, DataFrame - the flagship data abstraction of previous versions of Spark SQL - is currently a mere type alias for See package object sql. |
Dataset offers convenience of RDDs with the performance optimizations of DataFrames and the strong static type-safety of Scala. The last feature of bringing the strong type-safety to DataFrame makes Dataset so appealing. All the features together give you a more functional programming interface to work with structured data.
scala> spark.range(1).filter('id === 0).explain(true)
== Parsed Logical Plan ==
'Filter ('id = 0)
+- Range (0, 1, splits=8)
== Analyzed Logical Plan ==
id: bigint
Filter (id#51L = cast(0 as bigint))
+- Range (0, 1, splits=8)
== Optimized Logical Plan ==
Filter (id#51L = 0)
+- Range (0, 1, splits=8)
== Physical Plan ==
*Filter (id#51L = 0)
+- *Range (0, 1, splits=8)
scala> spark.range(1).filter(_ == 0).explain(true)
== Parsed Logical Plan ==
'TypedFilter <function1>, class java.lang.Long, [StructField(value,LongType,true)], unresolveddeserializer(newInstance(class java.lang.Long))
+- Range (0, 1, splits=8)
== Analyzed Logical Plan ==
id: bigint
TypedFilter <function1>, class java.lang.Long, [StructField(value,LongType,true)], newInstance(class java.lang.Long)
+- Range (0, 1, splits=8)
== Optimized Logical Plan ==
TypedFilter <function1>, class java.lang.Long, [StructField(value,LongType,true)], newInstance(class java.lang.Long)
+- Range (0, 1, splits=8)
== Physical Plan ==
*Filter <function1>.apply
+- *Range (0, 1, splits=8)It is only with Datasets to have syntax and analysis checks at compile time (that was not possible using DataFrame, regular SQL queries or even RDDs).
Using Dataset objects turns DataFrames of Row instances into a DataFrames of case classes with proper names and types (following their equivalents in the case classes). Instead of using indices to access respective fields in a DataFrame and cast it to a type, all this is automatically handled by Datasets and checked by the Scala compiler.
If however a LogicalPlan is used to create a Dataset, the logical plan is first executed (using the current SessionState in the SparkSession) that yields the QueryExecution plan.
A Dataset is Queryable and Serializable, i.e. can be saved to a persistent storage.
|
Note
|
SparkSession and QueryExecution are transient attributes of a Dataset and therefore do not participate in Dataset serialization. The only firmly-tied feature of a Dataset is the Encoder.
|
You can request the "untyped" view of a Dataset or access the RDD that is generated after executing the query. It is supposed to give you a more pleasant experience while transitioning from the legacy RDD-based or DataFrame-based APIs you may have used in the earlier versions of Spark SQL or encourage migrating from Spark Core’s RDD API to Spark SQL’s Dataset API.
The default storage level for Datasets is MEMORY_AND_DISK because recomputing the in-memory columnar representation of the underlying table is expensive. You can however persist a Dataset.
|
Note
|
Spark 2.0 has introduced a new query model called Structured Streaming for continuous incremental execution of structured queries. That made possible to consider Datasets a static and bounded as well as streaming and unbounded data sets with a single unified API for different execution models. |
A Dataset is local if it was created from local collections using SparkSession.emptyDataset or SparkSession.createDataset methods and their derivatives like toDF. If so, the queries on the Dataset can be optimized and run locally, i.e. without using Spark executors.
| Name | Description | ||||||
|---|---|---|---|---|---|---|---|
Used when…FIXME |
|||||||
Deserializer expression to convert internal rows to objects of type Created lazily by requesting the ExpressionEncoder to resolveAndBind Used when:
|
|||||||
Implicit ExpressionEncoder Used when…FIXME |
|||||||
|
Analyzed logical plan with all logical commands executed and turned into a LocalRelation. When initialized, |
||||||
|
|
||||||
(lazily-created) RDD of JVM objects of type
Internally,
|
|||||||
Lazily-created SQLContext Used when…FIXME |
Getting Input Files of Relations (in Structured Query) — inputFiles Method
inputFiles: Array[String]inputFiles requests QueryExecution for optimized logical plan and collects the following logical operators:
-
LogicalRelation with FileRelation (as the BaseRelation)
inputFiles then requests the logical operators for their underlying files:
-
inputFiles of the
FileRelations -
locationUri of the
HiveTableRelation
Creating Dataset Instance
Dataset takes the following when created:
-
Encoder for the type
Tof the records
|
Note
|
You can also create a Dataset using LogicalPlan that is immediately executed using SessionState.
|
Internally, Dataset requests QueryExecution to analyze itself.
Dataset initializes the internal registries and counters.
Is Dataset Local? — isLocal Method
isLocal: BooleanisLocal flag is enabled (i.e. true) when operators like collect or take could be run locally, i.e. without using executors.
Internally, isLocal checks whether the logical query plan of a Dataset is LocalRelation.
Is Dataset Streaming? — isStreaming method
isStreaming: BooleanisStreaming is enabled (i.e. true) when the logical plan is streaming.
Internally, isStreaming takes the Dataset’s logical plan and gives whether the plan is streaming or not.
withNewRDDExecutionId Internal Method
withNewRDDExecutionId[U](body: => U): UwithNewRDDExecutionId executes the input body action under new execution id.
|
Caution
|
FIXME What’s the difference between withNewRDDExecutionId and withNewExecutionId?
|
|
Note
|
withNewRDDExecutionId is used when Dataset.foreach and Dataset.foreachPartition actions are used.
|
Creating DataFrame (For Logical Query Plan and SparkSession) — ofRows Internal Factory Method
ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame|
Note
|
ofRows is part of Dataset Scala object that is marked as a private[sql] and so can only be accessed from code in org.apache.spark.sql package.
|
ofRows returns DataFrame (which is the type alias for Dataset[Row]). ofRows uses RowEncoder to convert the schema (based on the input logicalPlan logical plan).
Internally, ofRows prepares the input logicalPlan for execution and creates a Dataset[Row] with the current SparkSession, the QueryExecution and RowEncoder.
|
Note
|
|
Tracking Multi-Job Structured Query Execution (PySpark) — withNewExecutionId Internal Method
withNewExecutionId[U](body: => U): UwithNewExecutionId executes the input body action under new execution id.
|
Note
|
withNewExecutionId sets a unique execution id so that all Spark jobs belong to the Dataset action execution.
|
|
Note
|
Feel free to contact me at jacek@japila.pl if you think I should re-consider my decision. |
Executing Action Under New Execution ID — withAction Internal Method
withAction[U](name: String, qe: QueryExecution)(action: SparkPlan => U)withAction requests QueryExecution for the optimized physical query plan and resets the metrics of every physical operator (in the physical plan).
withAction requests SQLExecution to execute the input action with the executable physical plan (tracked under a new execution id).
In the end, withAction notifies ExecutionListenerManager that the name action has finished successfully or with an exception.
|
Note
|
withAction uses SparkSession to access ExecutionListenerManager.
|
|
Note
|
|
Creating Dataset Instance (For LogicalPlan and SparkSession) — apply Internal Factory Method
apply[T: Encoder](sparkSession: SparkSession, logicalPlan: LogicalPlan): Dataset[T]|
Note
|
apply is part of Dataset Scala object that is marked as a private[sql] and so can only be accessed from code in org.apache.spark.sql package.
|
apply…FIXME
|
Note
|
|
Collecting All Rows From Spark Plan — collectFromPlan Internal Method
collectFromPlan(plan: SparkPlan): Array[T]collectFromPlan…FIXME
|
Note
|
collectFromPlan is used for Dataset.head, Dataset.collect and Dataset.collectAsList operators.
|
selectUntyped Internal Method
selectUntyped(columns: TypedColumn[_, _]*): Dataset[_]selectUntyped…FIXME
|
Note
|
selectUntyped is used exclusively when Dataset.select typed transformation is used.
|
Helper Method for Typed Transformations — withTypedPlan Internal Method
withTypedPlan[U: Encoder](logicalPlan: LogicalPlan): Dataset[U]withTypedPlan…FIXME
|
Note
|
withTypedPlan is annotated with Scala’s @inline annotation that requests the Scala compiler to try especially hard to inline it.
|
|
Note
|
withTypedPlan is used in the Dataset typed transformations, i.e. withWatermark, joinWith, hint, as, filter, limit, sample, dropDuplicates, filter, map, repartition, repartitionByRange, coalesce and sort with sortWithinPartitions (through the sortInternal internal method).
|
Helper Method for Set-Based Typed Transformations — withSetOperator Internal Method
withSetOperator[U: Encoder](
logicalPlan: LogicalPlan): Dataset[U]withSetOperator…FIXME
|
Note
|
withSetOperator is annotated with Scala’s @inline annotation that requests the Scala compiler to try especially hard to inline it.
|
|
Note
|
withSetOperator is used for the Dataset’s typed transformations (i.e. union, unionByName, intersect, intersectAll, except and exceptAll).
|
sortInternal Internal Method
sortInternal(global: Boolean, sortExprs: Seq[Column]): Dataset[T]sortInternal creates a Dataset with Sort unary logical operator (and the logicalPlan as the child logical plan).
val nums = Seq((0, "zero"), (1, "one")).toDF("id", "name")
// Creates a Sort logical operator:
// - descending sort direction for id column (specified explicitly)
// - name column is wrapped with ascending sort direction
val numsSorted = nums.sort('id.desc, 'name)
val logicalPlan = numsSorted.queryExecution.logical
scala> println(logicalPlan.numberedTreeString)
00 'Sort ['id DESC NULLS LAST, 'name ASC NULLS FIRST], true
01 +- Project [_1#11 AS id#14, _2#12 AS name#15]
02 +- LocalRelation [_1#11, _2#12]Internally, sortInternal firstly builds ordering expressions for the given sortExprs columns, i.e. takes the sortExprs columns and makes sure that they are SortOrder expressions already (and leaves them untouched) or wraps them into SortOrder expressions with Ascending sort direction.
In the end, sortInternal creates a Dataset with Sort unary logical operator (with the ordering expressions, the given global flag, and the logicalPlan as the child logical plan).
|
Note
|
sortInternal is used for the sort and sortWithinPartitions typed transformations in the Dataset API (with the only change of the global flag being enabled and disabled, respectively).
|
Helper Method for Untyped Transformations and Basic Actions — withPlan Internal Method
withPlan(logicalPlan: LogicalPlan): DataFramewithPlan simply uses ofRows internal factory method to create a DataFrame for the input LogicalPlan and the current SparkSession.
|
Note
|
withPlan is annotated with Scala’s @inline annotation that requests the Scala compiler to try especially hard to inline it.
|
|
Note
|
withPlan is used in the Dataset untyped transformations (i.e. join, crossJoin and select) and basic actions (i.e. createTempView, createOrReplaceTempView, createGlobalTempView and createOrReplaceGlobalTempView).
|