val nums = Seq((0 to 4).toArray).toDF("nums")
val q = nums.withColumn("explode", explode($"nums"))
scala> q.explain
== Physical Plan ==
Generate explode(nums#3), true, false, [explode#12]
+- LocalTableScan [nums#3]
val sparkPlan = q.queryExecution.executedPlan
import org.apache.spark.sql.execution.GenerateExec
val ge = sparkPlan.asInstanceOf[GenerateExec]
scala> :type ge
org.apache.spark.sql.execution.GenerateExec
val rdd = ge.execute
scala> rdd.toDebugString
res1: String =
(1) MapPartitionsRDD[2] at execute at <console>:26 []
| MapPartitionsRDD[1] at execute at <console>:26 []
| ParallelCollectionRDD[0] at execute at <console>:26 []GenerateExec Unary Physical Operator
GenerateExec is a unary physical operator (i.e. with one child physical operator) that is created exclusively when BasicOperators execution planning strategy is requested to resolve a Generate logical operator.
When executed, GenerateExec executes (aka evaluates) the Generator expression on every row in a RDD partition.
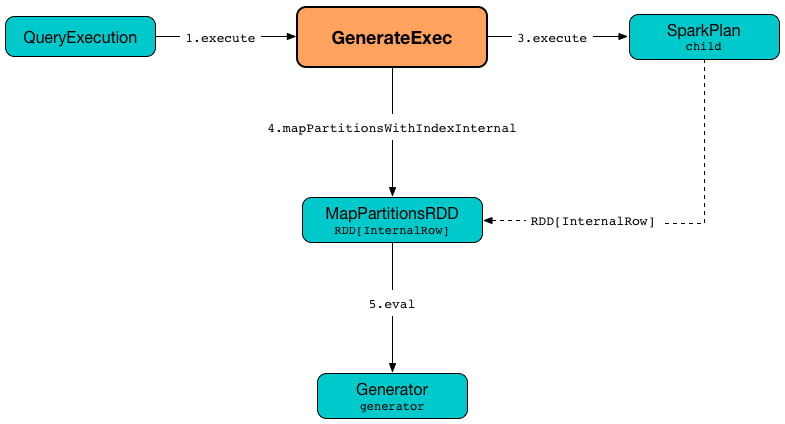
Figure 1. GenerateExec’s Execution —
doExecute Method|
Note
|
child physical operator has to support CodegenSupport. |
GenerateExec supports Java code generation (aka codegen).
GenerateExec does not support Java code generation (aka whole-stage codegen), i.e. supportCodegen flag is turned off.
scala> :type ge
org.apache.spark.sql.execution.GenerateExec
scala> ge.supportCodegen
res2: Boolean = false// Turn spark.sql.codegen.comments on to see comments in the code
// ./bin/spark-shell --conf spark.sql.codegen.comments=true
// inline function gives Inline expression
val q = spark.range(1)
.selectExpr("inline(array(struct(1, 'a'), struct(2, 'b')))")
scala> q.explain
== Physical Plan ==
Generate inline([[1,a],[2,b]]), false, false, [col1#47, col2#48]
+- *Project
+- *Range (0, 1, step=1, splits=8)
val sparkPlan = q.queryExecution.executedPlan
import org.apache.spark.sql.execution.GenerateExec
val ge = sparkPlan.asInstanceOf[GenerateExec]
import org.apache.spark.sql.execution.WholeStageCodegenExec
val wsce = ge.child.asInstanceOf[WholeStageCodegenExec]
val (_, code) = wsce.doCodeGen
import org.apache.spark.sql.catalyst.expressions.codegen.CodeFormatter
val formattedCode = CodeFormatter.format(code)
scala> println(formattedCode)
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIterator(references);
/* 003 */ }
/* 004 */
/* 005 */ /**
* Codegend pipeline for
* Project
* +- Range (0, 1, step=1, splits=8)
*/
/* 006 */ final class GeneratedIterator extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private org.apache.spark.sql.execution.metric.SQLMetric range_numOutputRows;
/* 010 */ private boolean range_initRange;
/* 011 */ private long range_number;
/* 012 */ private TaskContext range_taskContext;
/* 013 */ private InputMetrics range_inputMetrics;
/* 014 */ private long range_batchEnd;
/* 015 */ private long range_numElementsTodo;
/* 016 */ private scala.collection.Iterator range_input;
/* 017 */ private UnsafeRow range_result;
/* 018 */ private org.apache.spark.sql.catalyst.expressions.codegen.BufferHolder range_holder;
/* 019 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter range_rowWriter;
/* 020 */
/* 021 */ public GeneratedIterator(Object[] references) {
/* 022 */ this.references = references;
/* 023 */ }
/* 024 */
/* 025 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 026 */ partitionIndex = index;
/* 027 */ this.inputs = inputs;
/* 028 */ range_numOutputRows = (org.apache.spark.sql.execution.metric.SQLMetric) references[0];
/* 029 */ range_initRange = false;
/* 030 */ range_number = 0L;
/* 031 */ range_taskContext = TaskContext.get();
/* 032 */ range_inputMetrics = range_taskContext.taskMetrics().inputMetrics();
/* 033 */ range_batchEnd = 0;
/* 034 */ range_numElementsTodo = 0L;
/* 035 */ range_input = inputs[0];
/* 036 */ range_result = new UnsafeRow(1);
/* 037 */ range_holder = new org.apache.spark.sql.catalyst.expressions.codegen.BufferHolder(range_result, 0);
/* 038 */ range_rowWriter = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(range_holder, 1);
/* 039 */
/* 040 */ }
/* 041 */
/* 042 */ private void initRange(int idx) {
/* 043 */ java.math.BigInteger index = java.math.BigInteger.valueOf(idx);
/* 044 */ java.math.BigInteger numSlice = java.math.BigInteger.valueOf(8L);
/* 045 */ java.math.BigInteger numElement = java.math.BigInteger.valueOf(1L);
/* 046 */ java.math.BigInteger step = java.math.BigInteger.valueOf(1L);
/* 047 */ java.math.BigInteger start = java.math.BigInteger.valueOf(0L);
/* 048 */ long partitionEnd;
/* 049 */
/* 050 */ java.math.BigInteger st = index.multiply(numElement).divide(numSlice).multiply(step).add(start);
/* 051 */ if (st.compareTo(java.math.BigInteger.valueOf(Long.MAX_VALUE)) > 0) {
/* 052 */ range_number = Long.MAX_VALUE;
/* 053 */ } else if (st.compareTo(java.math.BigInteger.valueOf(Long.MIN_VALUE)) < 0) {
/* 054 */ range_number = Long.MIN_VALUE;
/* 055 */ } else {
/* 056 */ range_number = st.longValue();
/* 057 */ }
/* 058 */ range_batchEnd = range_number;
/* 059 */
/* 060 */ java.math.BigInteger end = index.add(java.math.BigInteger.ONE).multiply(numElement).divide(numSlice)
/* 061 */ .multiply(step).add(start);
/* 062 */ if (end.compareTo(java.math.BigInteger.valueOf(Long.MAX_VALUE)) > 0) {
/* 063 */ partitionEnd = Long.MAX_VALUE;
/* 064 */ } else if (end.compareTo(java.math.BigInteger.valueOf(Long.MIN_VALUE)) < 0) {
/* 065 */ partitionEnd = Long.MIN_VALUE;
/* 066 */ } else {
/* 067 */ partitionEnd = end.longValue();
/* 068 */ }
/* 069 */
/* 070 */ java.math.BigInteger startToEnd = java.math.BigInteger.valueOf(partitionEnd).subtract(
/* 071 */ java.math.BigInteger.valueOf(range_number));
/* 072 */ range_numElementsTodo = startToEnd.divide(step).longValue();
/* 073 */ if (range_numElementsTodo < 0) {
/* 074 */ range_numElementsTodo = 0;
/* 075 */ } else if (startToEnd.remainder(step).compareTo(java.math.BigInteger.valueOf(0L)) != 0) {
/* 076 */ range_numElementsTodo++;
/* 077 */ }
/* 078 */ }
/* 079 */
/* 080 */ protected void processNext() throws java.io.IOException {
/* 081 */ // PRODUCE: Project
/* 082 */ // PRODUCE: Range (0, 1, step=1, splits=8)
/* 083 */ // initialize Range
/* 084 */ if (!range_initRange) {
/* 085 */ range_initRange = true;
/* 086 */ initRange(partitionIndex);
/* 087 */ }
/* 088 */
/* 089 */ while (true) {
/* 090 */ long range_range = range_batchEnd - range_number;
/* 091 */ if (range_range != 0L) {
/* 092 */ int range_localEnd = (int)(range_range / 1L);
/* 093 */ for (int range_localIdx = 0; range_localIdx < range_localEnd; range_localIdx++) {
/* 094 */ long range_value = ((long)range_localIdx * 1L) + range_number;
/* 095 */
/* 096 */ // CONSUME: Project
/* 097 */ // CONSUME: WholeStageCodegen
/* 098 */ append(unsafeRow);
/* 099 */
/* 100 */ if (shouldStop()) { range_number = range_value + 1L; return; }
/* 101 */ }
/* 102 */ range_number = range_batchEnd;
/* 103 */ }
/* 104 */
/* 105 */ range_taskContext.killTaskIfInterrupted();
/* 106 */
/* 107 */ long range_nextBatchTodo;
/* 108 */ if (range_numElementsTodo > 1000L) {
/* 109 */ range_nextBatchTodo = 1000L;
/* 110 */ range_numElementsTodo -= 1000L;
/* 111 */ } else {
/* 112 */ range_nextBatchTodo = range_numElementsTodo;
/* 113 */ range_numElementsTodo = 0;
/* 114 */ if (range_nextBatchTodo == 0) break;
/* 115 */ }
/* 116 */ range_numOutputRows.add(range_nextBatchTodo);
/* 117 */ range_inputMetrics.incRecordsRead(range_nextBatchTodo);
/* 118 */
/* 119 */ range_batchEnd += range_nextBatchTodo * 1L;
/* 120 */ }
/* 121 */ }
/* 122 */
/* 123 */ }The output schema of a GenerateExec is…FIXME
| Key | Name (in web UI) | Description |
|---|---|---|
number of output rows |
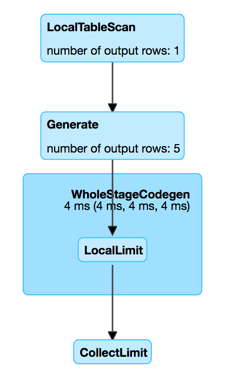
Figure 2. GenerateExec in web UI (Details for Query)
producedAttributes…FIXME
outputPartitioning…FIXME
boundGenerator…FIXME
GenerateExec gives child's input RDDs (when WholeStageCodegenExec is executed).
GenerateExec requires that…FIXME
Generating Java Source Code for Produce Path in Whole-Stage Code Generation — doProduce Method
doProduce(ctx: CodegenContext): String|
Note
|
doProduce is part of CodegenSupport Contract to generate the Java source code for produce path in Whole-Stage Code Generation.
|
doProduce…FIXME
Generating Java Source Code for Consume Path in Whole-Stage Code Generation — doConsume Method
doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String|
Note
|
doConsume is part of CodegenSupport Contract to generate the Java source code for consume path in Whole-Stage Code Generation.
|
doConsume…FIXME
codeGenCollection Internal Method
codeGenCollection(
ctx: CodegenContext,
e: CollectionGenerator,
input: Seq[ExprCode],
row: ExprCode): StringcodeGenCollection…FIXME
|
Note
|
codeGenCollection is used exclusively when GenerateExec is requested to generate the Java code for the "consume" path in whole-stage code generation (when Generator is a CollectionGenerator).
|
codeGenTraversableOnce Internal Method
codeGenTraversableOnce(
ctx: CodegenContext,
e: Expression,
input: Seq[ExprCode],
row: ExprCode): StringcodeGenTraversableOnce…FIXME
|
Note
|
codeGenTraversableOnce is used exclusively when GenerateExec is requested to generate the Java code for the consume path in whole-stage code generation (when Generator is not a CollectionGenerator).
|
codeGenAccessor Internal Method
codeGenAccessor(
ctx: CodegenContext,
source: String,
name: String,
index: String,
dt: DataType,
nullable: Boolean,
initialChecks: Seq[String]): ExprCodecodeGenAccessor…FIXME
|
Note
|
codeGenAccessor is used…FIXME
|
Creating GenerateExec Instance
GenerateExec takes the following when created:
-
Child physical operator
Executing Physical Operator (Generating RDD[InternalRow]) — doExecute Method
doExecute(): RDD[InternalRow]|
Note
|
doExecute is part of SparkPlan Contract to generate the runtime representation of a structured query as a distributed computation over internal binary rows on Apache Spark (i.e. RDD[InternalRow]).
|
doExecute…FIXME