active: Array[StreamingQuery]StreamingQueryManager — Streaming Query Management
StreamingQueryManager is the management interface for active streaming queries of a SparkSession.
| Method | Description |
|---|---|
Active structured queries |
|
Registers (adds) a StreamingQueryListener |
|
Waits until any streaming query terminats or |
|
Gets the StreamingQuery by id |
|
De-registers (removes) the StreamingQueryListener |
|
Resets the internal registry of the terminated streaming queries (that lets awaitAnyTermination to be used again) |
StreamingQueryManager is available using SparkSession.streams property.
scala> :type spark
org.apache.spark.sql.SparkSession
scala> :type spark.streams
org.apache.spark.sql.streaming.StreamingQueryManagerStreamingQueryManager is created when SessionState is created.
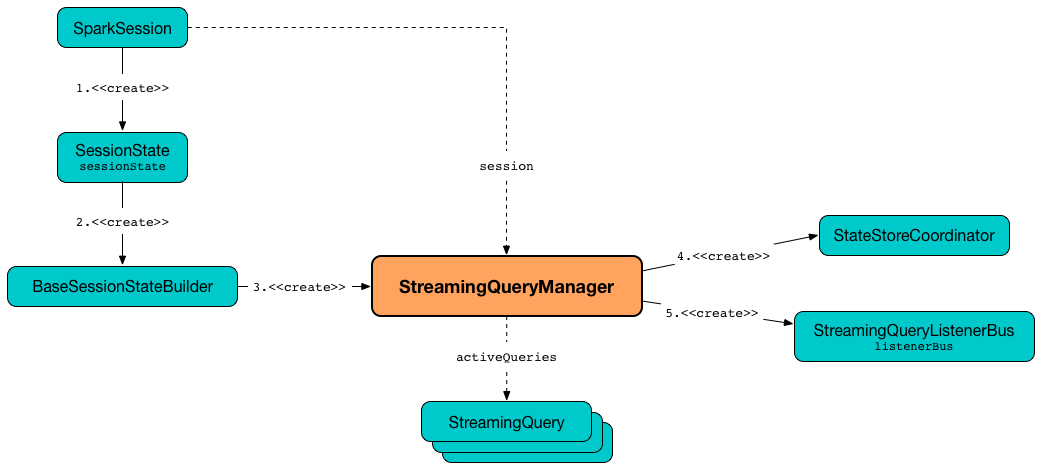
Figure 1. StreamingQueryManager
|
Tip
|
Read up on SessionState in The Internals of Spark SQL gitbook. |
StreamingQueryManager is used (internally) to create a StreamingQuery (and its StreamExecution).
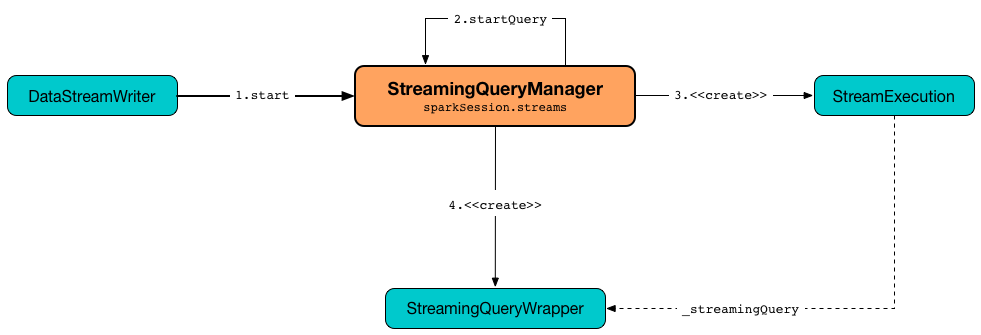
Figure 2. StreamingQueryManager Creates StreamingQuery (and StreamExecution)
StreamingQueryManager is notified about state changes of a structured query and passes them along (to registered listeners).
StreamingQueryListenerBus — listenerBus Internal Property
listenerBus: StreamingQueryListenerBuslistenerBus is a StreamingQueryListenerBus (for the current SparkSession) that is created immediately when StreamingQueryManager is created.
listenerBus is used for the following:
Getting All Active Streaming Queries — active Method
active: Array[StreamingQuery]active gets all active streaming queries.
Getting Active Continuous Query By Name — get Method
get(name: String): StreamingQueryget method returns a StreamingQuery by name.
It may throw an IllegalArgumentException when no StreamingQuery exists for the name.
java.lang.IllegalArgumentException: There is no active query with name hello
at org.apache.spark.sql.StreamingQueryManager$$anonfun$get$1.apply(StreamingQueryManager.scala:59)
at org.apache.spark.sql.StreamingQueryManager$$anonfun$get$1.apply(StreamingQueryManager.scala:59)
at scala.collection.MapLike$class.getOrElse(MapLike.scala:128)
at scala.collection.AbstractMap.getOrElse(Map.scala:59)
at org.apache.spark.sql.StreamingQueryManager.get(StreamingQueryManager.scala:58)
... 49 elided Registering StreamingQueryListener — addListener Method
addListener(listener: StreamingQueryListener): UnitaddListener requests the StreamingQueryListenerBus to add the input listener.
De-Registering StreamingQueryListener — removeListener Method
removeListener(listener: StreamingQueryListener): UnitremoveListener requests StreamingQueryListenerBus to remove the input listener.
Waiting for Any Streaming Query Termination — awaitAnyTermination Method
awaitAnyTermination(): Unit
awaitAnyTermination(timeoutMs: Long): BooleanawaitAnyTermination acquires a lock on awaitTerminationLock and waits until any streaming query has finished (i.e. lastTerminatedQuery is available) or timeoutMs has expired.
awaitAnyTermination re-throws the StreamingQueryException from lastTerminatedQuery if it reported one.
resetTerminated Method
resetTerminated(): UnitresetTerminated forgets about the past-terminated query (so that awaitAnyTermination can be used again to wait for a new streaming query termination).
Internally, resetTerminated acquires a lock on awaitTerminationLock and simply resets lastTerminatedQuery (i.e. sets it to null).
Creating Streaming Query — createQuery Internal Method
createQuery(
userSpecifiedName: Option[String],
userSpecifiedCheckpointLocation: Option[String],
df: DataFrame,
extraOptions: Map[String, String],
sink: BaseStreamingSink,
outputMode: OutputMode,
useTempCheckpointLocation: Boolean,
recoverFromCheckpointLocation: Boolean,
trigger: Trigger,
triggerClock: Clock): StreamingQueryWrappercreateQuery creates a StreamingQueryWrapper (for a StreamExecution per the input user-defined properties).
Internally, createQuery first finds the name of the checkpoint directory of a query (aka checkpoint location) in the following order:
-
Exactly the input
userSpecifiedCheckpointLocationif defined -
spark.sql.streaming.checkpointLocation Spark property if defined for the parent directory with a subdirectory per the optional
userSpecifiedName(or a randomly-generated UUID) -
(only when
useTempCheckpointLocationis enabled) A temporary directory (as specified byjava.io.tmpdirJVM property) with a subdirectory withtemporaryprefix.
|
Note
|
userSpecifiedCheckpointLocation can be any path that is acceptable by Hadoop’s Path.
|
If the directory name for the checkpoint location could not be found, createQuery reports a AnalysisException.
checkpointLocation must be specified either through option("checkpointLocation", ...) or SparkSession.conf.set("spark.sql.streaming.checkpointLocation", ...)createQuery reports a AnalysisException when the input recoverFromCheckpointLocation flag is turned off but there is offsets directory in the checkpoint location.
createQuery makes sure that the logical plan of the structured query is analyzed (i.e. no logical errors have been found).
Unless spark.sql.streaming.unsupportedOperationCheck Spark property is turned on, createQuery checks the logical plan of the streaming query for unsupported operations.
(only when spark.sql.adaptive.enabled Spark property is turned on) createQuery prints out a WARN message to the logs:
WARN spark.sql.adaptive.enabled is not supported in streaming DataFrames/Datasets and will be disabled.In the end, createQuery creates a StreamingQueryWrapper with a new MicroBatchExecution.
|
Note
|
|
|
Note
|
userSpecifiedName corresponds to queryName option (that can be defined using DataStreamWriter's queryName method) while userSpecifiedCheckpointLocation is checkpointLocation option.
|
|
Note
|
createQuery is used exclusively when StreamingQueryManager is requested to start a streaming query (when DataStreamWriter is requested to start an execution of a streaming query).
|
Starting Streaming Query Execution — startQuery Internal Method
startQuery(
userSpecifiedName: Option[String],
userSpecifiedCheckpointLocation: Option[String],
df: DataFrame,
extraOptions: Map[String, String],
sink: BaseStreamingSink,
outputMode: OutputMode,
useTempCheckpointLocation: Boolean = false,
recoverFromCheckpointLocation: Boolean = true,
trigger: Trigger = ProcessingTime(0),
triggerClock: Clock = new SystemClock()): StreamingQuerystartQuery starts a streaming query and returns a handle to it.
|
Note
|
trigger defaults to 0 milliseconds (as ProcessingTime(0)).
|
Internally, startQuery first creates a StreamingQueryWrapper, registers it in activeQueries internal registry (by the id), requests it for the underlying StreamExecution and starts it.
In the end, startQuery returns the StreamingQueryWrapper (as part of the fluent API so you can chain operators) or throws the exception that was reported when attempting to start the query.
startQuery throws an IllegalArgumentException when there is another query registered under name. startQuery looks it up in the activeQueries internal registry.
Cannot start query with name [name] as a query with that name is already activestartQuery throws an IllegalStateException when a query is started again from checkpoint. startQuery looks it up in activeQueries internal registry.
Cannot start query with id [id] as another query with same id is already active. Perhaps you are attempting to restart a query from checkpoint that is already active.
|
Note
|
startQuery is used exclusively when DataStreamWriter is requested to start an execution of the streaming query.
|
Posting StreamingQueryListener Event to StreamingQueryListenerBus — postListenerEvent Internal Method
postListenerEvent(event: StreamingQueryListener.Event): UnitpostListenerEvent simply posts the input event to the internal event bus for streaming events (StreamingQueryListenerBus).
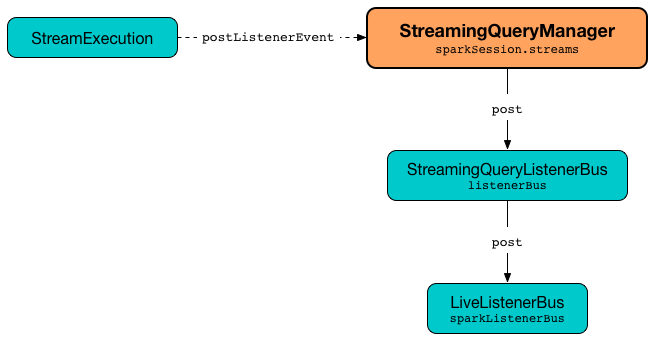
Figure 3. StreamingQueryManager Propagates StreamingQueryListener Events
|
Note
|
postListenerEvent is used exclusively when StreamExecution is requested to post a streaming event.
|
Handling Termination of Streaming Query (and Deactivating Query in StateStoreCoordinator) — notifyQueryTermination Internal Method
notifyQueryTermination(terminatedQuery: StreamingQuery): UnitnotifyQueryTermination removes the terminatedQuery from activeQueries internal registry (by the query id).
notifyQueryTermination records the terminatedQuery in lastTerminatedQuery internal registry (when no earlier streaming query was recorded or the terminatedQuery terminated due to an exception).
notifyQueryTermination notifies others that are blocked on awaitTerminationLock.
In the end, notifyQueryTermination requests StateStoreCoordinator to deactivate all active runs of the streaming query.
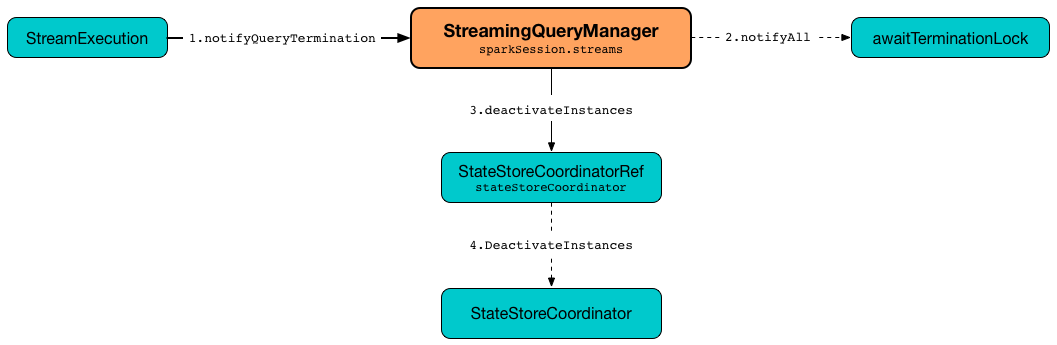
Figure 4. StreamingQueryManager’s Marking Streaming Query as Terminated
|
Note
|
notifyQueryTermination is used exclusively when StreamExecution is requested to run a streaming query and the query has finished (running streaming batches) (with or without an exception).
|