currentBatchId: LongProgressReporter Contract
ProgressReporter is the contract of stream execution progress reporters that report the statistics of execution of a streaming query.
| Method | Description | ||
|---|---|---|---|
|
Id of the current streaming micro-batch |
||
|
Universally unique identifier (UUID) of the streaming query (that stays unchanged between restarts) |
||
|
|
||
|
Logical query plan of the streaming query Used when
|
||
|
Name of the streaming query |
||
|
Streaming readers and sources with the new data (as a Used when:
|
||
|
OffsetSeqMetadata (with the current micro-batch event-time watermark and timestamp) |
||
|
|
||
|
Universally unique identifier (UUID) of the single run of the streaming query (that changes every restart) |
||
|
The one and only streaming writer or sink of the streaming query |
||
|
Streaming readers and sources of the streaming query |
||
|
|
||
|
Clock of the streaming query |
|
Note
|
StreamExecution is the one and only known direct extension of the ProgressReporter Contract in Spark Structured Streaming. |
ProgressReporter uses the spark.sql.streaming.noDataProgressEventInterval configuration property to control how long to wait between two progress events when there is no data (default: 10000L) when finishing trigger.
ProgressReporter uses yyyy-MM-dd'T'HH:mm:ss.SSS'Z' time format (with UTC timezone).
import org.apache.spark.sql.streaming.Trigger
import scala.concurrent.duration._
val sampleQuery = spark
.readStream
.format("rate")
.load
.writeStream
.format("console")
.option("truncate", false)
.trigger(Trigger.ProcessingTime(10.seconds))
.start
// Using public API
import org.apache.spark.sql.streaming.SourceProgress
scala> sampleQuery.
| lastProgress.
| sources.
| map { case sp: SourceProgress =>
| s"source = ${sp.description} => endOffset = ${sp.endOffset}" }.
| foreach(println)
source = RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8] => endOffset = 663
scala> println(sampleQuery.lastProgress.sources(0))
res40: org.apache.spark.sql.streaming.SourceProgress =
{
"description" : "RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8]",
"startOffset" : 333,
"endOffset" : 343,
"numInputRows" : 10,
"inputRowsPerSecond" : 0.9998000399920015,
"processedRowsPerSecond" : 200.0
}
// With a hack
import org.apache.spark.sql.execution.streaming.StreamingQueryWrapper
val offsets = sampleQuery.
asInstanceOf[StreamingQueryWrapper].
streamingQuery.
availableOffsets.
map { case (source, offset) =>
s"source = $source => offset = $offset" }
scala> offsets.foreach(println)
source = RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8] => offset = 293|
Tip
|
Configure logging of the concrete stream execution progress reporters to see what happens inside a |
progressBuffer Internal Property
progressBuffer: Queue[StreamingQueryProgress]progressBuffer is a scala.collection.mutable.Queue of StreamingQueryProgresses.
progressBuffer has a new StreamingQueryProgress added when ProgressReporter is requested to update progress of a streaming query.
When the size (the number of StreamingQueryProgresses) is above spark.sql.streaming.numRecentProgressUpdates threshold, the oldest StreamingQueryProgress is removed (dequeued).
progressBuffer is used when ProgressReporter is requested for the last and the recent StreamingQueryProgresses
status Method
status: StreamingQueryStatusstatus gives the current StreamingQueryStatus.
|
Note
|
status is used when StreamingQueryWrapper is requested for the current status of a streaming query (that is part of StreamingQuery Contract).
|
Updating Progress of Streaming Query — updateProgress Internal Method
updateProgress(newProgress: StreamingQueryProgress): UnitupdateProgress records the input newProgress and posts a QueryProgressEvent event.
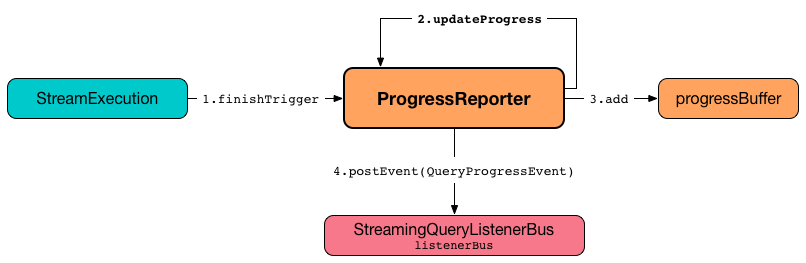
Figure 1. ProgressReporter’s Reporting Query Progress
updateProgress adds the input newProgress to progressBuffer.
updateProgress removes elements from progressBuffer if their number is or exceeds the value of spark.sql.streaming.numRecentProgressUpdates property.
updateProgress posts a QueryProgressEvent (with the input newProgress).
updateProgress prints out the following INFO message to the logs:
Streaming query made progress: [newProgress]|
Note
|
updateProgress synchronizes concurrent access to the progressBuffer internal registry.
|
|
Note
|
updateProgress is used exclusively when ProgressReporter is requested to finish up a trigger.
|
Initializing Query Progress for New Trigger — startTrigger Method
startTrigger(): UnitstartTrigger prints out the following DEBUG message to the logs:
Starting Trigger Calculation| Registry | New Value |
|---|---|
Requests the trigger clock for the current timestamp (in millis) |
|
Enables ( |
|
|
|
|
|
Clears the currentDurationsMs |
|
Note
|
|
Finishing Up Streaming Batch (Trigger) and Generating StreamingQueryProgress — finishTrigger Method
finishTrigger(hasNewData: Boolean): UnitInternally, finishTrigger sets currentTriggerEndTimestamp to the current time (using triggerClock).
finishTrigger extractExecutionStats.
finishTrigger calculates the processing time (in seconds) as the difference between the end and start timestamps.
finishTrigger calculates the input time (in seconds) as the difference between the start time of the current and last triggers.

Figure 2. ProgressReporter’s finishTrigger and Timestamps
finishTrigger prints out the following DEBUG message to the logs:
Execution stats: [executionStats]finishTrigger creates a SourceProgress (aka source statistics) for every source used.
finishTrigger creates a SinkProgress (aka sink statistics) for the sink.
finishTrigger creates a StreamingQueryProgress.
If there was any data (using the input hasNewData flag), finishTrigger resets lastNoDataProgressEventTime (i.e. becomes the minimum possible time) and updates query progress.
Otherwise, when no data was available (using the input hasNewData flag), finishTrigger updates query progress only when lastNoDataProgressEventTime passed.
In the end, finishTrigger disables isTriggerActive flag of StreamingQueryStatus (i.e. sets it to false).
|
Note
|
finishTrigger is used exclusively when MicroBatchExecution is requested to run the activated streaming query (after triggerExecution Phase at the end of a streaming batch).
|
Time-Tracking Section (Recording Execution Time for Progress Reporting) — reportTimeTaken Method
reportTimeTaken[T](
triggerDetailKey: String)(
body: => T): TreportTimeTaken measures the time to execute body and records it in the currentDurationsMs internal registry under triggerDetailKey key. If the triggerDetailKey key was recorded already, the current execution time is added.
In the end, reportTimeTaken prints out the following DEBUG message to the logs and returns the result of executing body.
[triggerDetailKey] took [time] ms|
Note
|
|
Updating Status Message — updateStatusMessage Method
updateStatusMessage(message: String): UnitupdateStatusMessage simply updates the message in the StreamingQueryStatus internal registry.
|
Note
|
|
Generating Execution Statistics — extractExecutionStats Internal Method
extractExecutionStats(hasNewData: Boolean): ExecutionStatsextractExecutionStats generates an ExecutionStats of the last execution of the streaming query.
Internally, extractExecutionStats generate watermark metric (using the event-time watermark of the OffsetSeqMetadata) if there is a EventTimeWatermark unary logical operator in the logical plan of the streaming query.
|
Note
|
EventTimeWatermark unary logical operator represents Dataset.withWatermark operator in a streaming query. |
extractExecutionStats extractStateOperatorMetrics.
extractExecutionStats extractSourceToNumInputRows.
extractExecutionStats finds the EventTimeWatermarkExec unary physical operator (with non-zero EventTimeStats) and generates max, min, and avg statistics.
In the end, extractExecutionStats creates a ExecutionStats with the execution statistics.
If the input hasNewData flag is turned off (false), extractExecutionStats returns an ExecutionStats with no input rows and event-time statistics (that require data to be processed to have any sense).
|
Note
|
extractExecutionStats is used exclusively when ProgressReporter is requested to finish up a streaming batch (trigger) and generate a StreamingQueryProgress.
|
Generating StateStoreWriter Metrics (StateOperatorProgress) — extractStateOperatorMetrics Internal Method
extractStateOperatorMetrics(
hasNewData: Boolean): Seq[StateOperatorProgress]extractStateOperatorMetrics requests the QueryExecution for the optimized execution plan (executedPlan) and finds all StateStoreWriter physical operators and requests them for StateOperatorProgress.
extractStateOperatorMetrics clears (zeros) the numRowsUpdated metric for the given hasNewData turned off (false).
extractStateOperatorMetrics returns an empty collection for the QueryExecution uninitialized (null).
|
Note
|
extractStateOperatorMetrics is used exclusively when ProgressReporter is requested to generate execution statistics.
|
extractSourceToNumInputRows Internal Method
extractSourceToNumInputRows(): Map[BaseStreamingSource, Long]extractSourceToNumInputRows…FIXME
|
Note
|
extractSourceToNumInputRows is used exclusively when ProgressReporter is requested to generate execution statistics.
|
formatTimestamp Internal Method
formatTimestamp(millis: Long): StringformatTimestamp…FIXME
|
Note
|
formatTimestamp is used when…FIXME
|
Recording Trigger Offsets (StreamProgress) — recordTriggerOffsets Method
recordTriggerOffsets(
from: StreamProgress,
to: StreamProgress): UnitrecordTriggerOffsets simply sets (records) the currentTriggerStartOffsets and currentTriggerEndOffsets internal registries to the json representations of the from and to StreamProgresses.
|
Note
|
|
Last StreamingQueryProgress — lastProgress Method
lastProgress: StreamingQueryProgresslastProgress…FIXME
|
Note
|
lastProgress is used when…FIXME
|
recentProgress Method
recentProgress: Array[StreamingQueryProgress]recentProgress…FIXME
|
Note
|
recentProgress is used when…FIXME
|
Internal Properties
| Name | Description | ||
|---|---|---|---|
|
scala.collection.mutable.HashMap of action names (aka triggerDetailKey) and their cumulative times (in milliseconds). Starts empty when
|
||
|
StreamingQueryStatus with the current status of the streaming query Available using status method
|
||
|
|||
|
|||
|
Start offsets (in JSON format) per source Used exclusively when finishing up a streaming batch (trigger) and generating StreamingQueryProgress (for a SourceProgress) Reset ( Initialized when recording trigger offsets (StreamProgress) |
||
|
|||
|
Default: |
||
|
|||
|