import org.apache.spark.sql.streaming.Trigger
import scala.concurrent.duration._
val sq = spark
.readStream
.format("rate")
.load
.writeStream
.format("console")
.option("truncate", false)
.trigger(Trigger.Continuous(15.seconds)) // <-- Uses ContinuousExecution for execution
.queryName("rate2console")
.start
scala> :type sq
org.apache.spark.sql.streaming.StreamingQuery
assert(sq.isActive)
// sq.stopContinuous Stream Processing (Structured Streaming V2)
Continuous Stream Processing is one of the two stream processing engines in Spark Structured Streaming that is used for execution of structured streaming queries with Trigger.Continuous trigger.
|
Note
|
The other feature-richer stream processing engine is Micro-Batch Stream Processing. |
Continuous Stream Processing execution engine uses the novel Data Source API V2 (Spark SQL) and for the very first time makes stream processing truly continuous.
|
Tip
|
Read up on Data Source API V2 in The Internals of Spark SQL book. |
Because of the two innovative changes Continuous Stream Processing is often referred to as Structured Streaming V2.
Under the covers, Continuous Stream Processing uses ContinuousExecution stream execution engine. When requested to run an activated streaming query, ContinuousExecution adds WriteToContinuousDataSourceExec physical operator as the top-level operator in the physical query plan of the streaming query.
scala> :type sq
org.apache.spark.sql.streaming.StreamingQuery
scala> sq.explain
== Physical Plan ==
WriteToContinuousDataSource ConsoleWriter[numRows=20, truncate=false]
+- *(1) Project [timestamp#758, value#759L]
+- *(1) ScanV2 rate[timestamp#758, value#759L]From now on, you may think of a streaming query as a soon-to-be-generated ContinuousWriteRDD - an RDD data structure that Spark developers use to describe a distributed computation.
When the streaming query is started (and the top-level WriteToContinuousDataSourceExec physical operator is requested to execute and generate a recipe for a distributed computation (as an RDD[InternalRow])), it simply requests the underlying ContinuousWriteRDD to collect.
That collect operator is how a Spark job is run (as tasks over all partitions of the RDD) as described by the ContinuousWriteRDD.compute "protocol" (a recipe for the tasks to be scheduled to run on Spark executors).
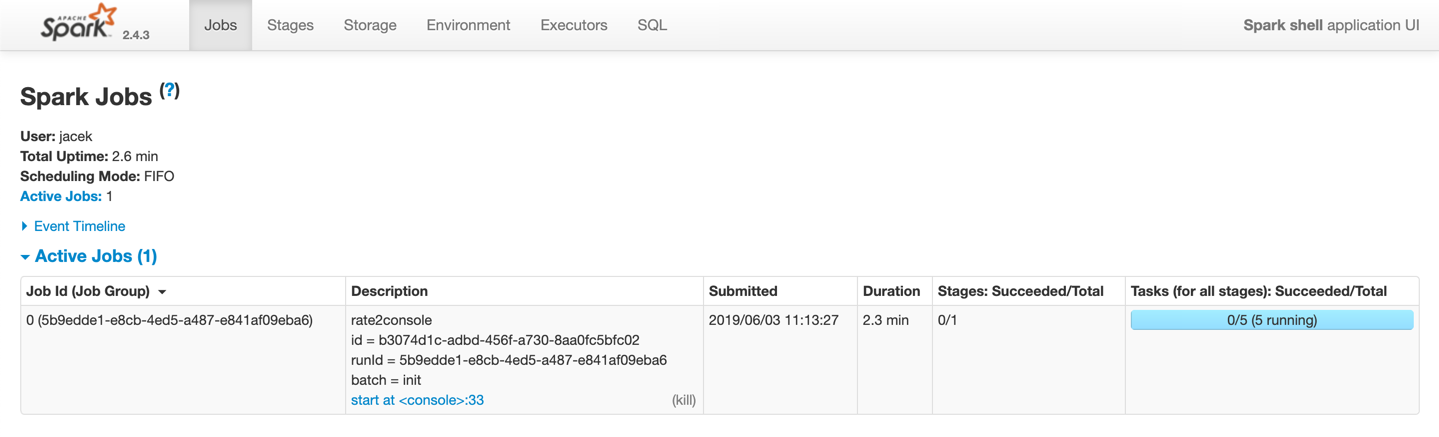
Figure 1. Creating Instance of StreamExecution
While the tasks are computing partitions (of the ContinuousWriteRDD), they keep running until killed or completed. And that’s the ingenious design trick of how the streaming query (as a Spark job with the distributed tasks running on executors) runs continuously and indefinitely.
When DataStreamReader is requested to create a streaming query for a ContinuousReadSupport data source, it creates…FIXME