scala> :type spark
org.apache.spark.sql.SparkSession
scala> :type spark.sessionState
org.apache.spark.sql.internal.SessionStateSessionState — State Separation Layer Between SparkSessions
SessionState is the state separation layer between Spark SQL sessions, including SQL configuration, tables, functions, UDFs, SQL parser, and everything else that depends on a SQLConf.
SessionState is available as the sessionState property of a SparkSession.
SessionState is created when SparkSession is requested to instantiateSessionState (when requested for the SessionState per spark.sql.catalogImplementation configuration property).
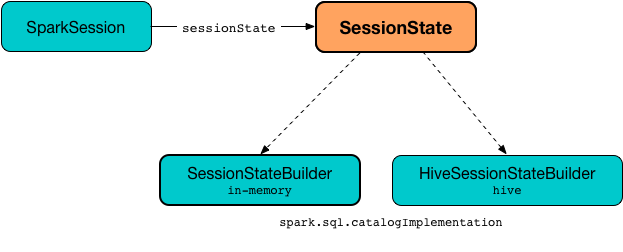
Figure 1. Creating SessionState
|
Note
|
When requested for the SessionState, There are two
|
| Name | Type | Description |
|---|---|---|
|
Initialized lazily (i.e. only when requested the first time) using the analyzerBuilder factory function. Used when…FIXME |
|
|
Metastore of tables and databases Used when…FIXME |
|
|
Used when…FIXME |
|
|
Used when…FIXME |
|
|
Used when…FIXME |
|
|
Used when…FIXME |
|
|
Used exclusively when |
|
|
|
Used when…FIXME |
|
Used when…FIXME |
|
|
|
Used to manage streaming queries in Spark Structured Streaming |
|
Interface to register user-defined functions. Used when…FIXME |
|
Note
|
SessionState is a private[sql] class and, given the package org.apache.spark.sql.internal, SessionState should be considered internal.
|
Creating SessionState Instance
SessionState takes the following when created:
-
catalogBuilderfunction to create a SessionCatalog (i.e.() ⇒ SessionCatalog) -
analyzerBuilderfunction to create an Analyzer (i.e.() ⇒ Analyzer) -
optimizerBuilderfunction to create an Optimizer (i.e.() ⇒ Optimizer) -
resourceLoaderBuilderfunction to create aSessionResourceLoader(i.e.() ⇒ SessionResourceLoader) -
createQueryExecutionfunction to create a QueryExecution given a LogicalPlan (i.e.LogicalPlan ⇒ QueryExecution) -
createClonefunction to clone theSessionStategiven a SparkSession (i.e.(SparkSession, SessionState) ⇒ SessionState)
clone Method
clone(newSparkSession: SparkSession): SessionStateclone…FIXME
|
Note
|
clone is used when…
|
"Executing" Logical Plan (Creating QueryExecution For LogicalPlan) — executePlan Method
executePlan(plan: LogicalPlan): QueryExecutionexecutePlan simply executes the createQueryExecution function on the input logical plan (that simply creates a QueryExecution with the current SparkSession and the input logical plan).
refreshTable Method
refreshTable(tableName: String): UnitrefreshTable…FIXME
|
Note
|
refreshTable is used…FIXME
|
Creating New Hadoop Configuration — newHadoopConf Method
newHadoopConf(): ConfigurationnewHadoopConf returns a new Hadoop Configuration (with the SparkContext.hadoopConfiguration and all the configuration properties of the SQLConf).
|
Note
|
newHadoopConf is used by ScriptTransformation, ParquetRelation, StateStoreRDD, and SessionState itself, and few other places.
|
Creating New Hadoop Configuration With Extra Options — newHadoopConfWithOptions Method
newHadoopConfWithOptions(options: Map[String, String]): ConfigurationnewHadoopConfWithOptions creates a new Hadoop Configuration with the input options set (except path and paths options that are skipped).
|
Note
|
|