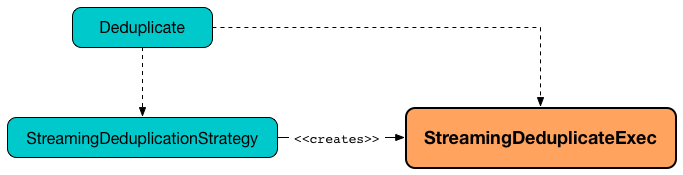
StreamingDeduplicateExec Unary Physical Operator for Streaming Deduplication
StreamingDeduplicateExec is a unary physical operator that writes state to StateStore with support for streaming watermark.
|
Note
|
A unary physical operator ( Read up on UnaryExecNode (and physical operators in general) in The Internals of Spark SQL book. |
StreamingDeduplicateExec is created exclusively when StreamingDeduplicationStrategy plans Deduplicate unary logical operators.
Figure 1. StreamingDeduplicateExec and StreamingDeduplicationStrategy
val uniqueValues = spark.
readStream.
format("rate").
load.
dropDuplicates("value") // <-- creates Deduplicate logical operator
scala> println(uniqueValues.queryExecution.logical.numberedTreeString)
00 Deduplicate [value#214L], true
01 +- StreamingRelation DataSource(org.apache.spark.sql.SparkSession@4785f176,rate,List(),None,List(),None,Map(),None), rate, [timestamp#213, value#214L]
scala> uniqueValues.explain
== Physical Plan ==
StreamingDeduplicate [value#214L], StatefulOperatorStateInfo(<unknown>,5a65879c-67bc-4e77-b417-6100db6a52a2,0,0), 0
+- Exchange hashpartitioning(value#214L, 200)
+- StreamingRelation rate, [timestamp#213, value#214L]
// Start the query and hence StreamingDeduplicateExec
import scala.concurrent.duration._
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
val sq = uniqueValues.
writeStream.
format("console").
option("truncate", false).
trigger(Trigger.ProcessingTime(10.seconds)).
outputMode(OutputMode.Update).
start
// sorting not supported for non-aggregate queries
// and so values are unsorted
-------------------------------------------
Batch: 0
-------------------------------------------
+---------+-----+
|timestamp|value|
+---------+-----+
+---------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+-----------------------+-----+
|timestamp |value|
+-----------------------+-----+
|2017-07-25 22:12:03.018|0 |
|2017-07-25 22:12:08.018|5 |
|2017-07-25 22:12:04.018|1 |
|2017-07-25 22:12:06.018|3 |
|2017-07-25 22:12:05.018|2 |
|2017-07-25 22:12:07.018|4 |
+-----------------------+-----+
-------------------------------------------
Batch: 2
-------------------------------------------
+-----------------------+-----+
|timestamp |value|
+-----------------------+-----+
|2017-07-25 22:12:10.018|7 |
|2017-07-25 22:12:09.018|6 |
|2017-07-25 22:12:12.018|9 |
|2017-07-25 22:12:13.018|10 |
|2017-07-25 22:12:15.018|12 |
|2017-07-25 22:12:11.018|8 |
|2017-07-25 22:12:14.018|11 |
|2017-07-25 22:12:16.018|13 |
|2017-07-25 22:12:17.018|14 |
|2017-07-25 22:12:18.018|15 |
+-----------------------+-----+
// Eventually...
sq.stopStreamingDeduplicateExec uses the performance metrics of StateStoreWriter.
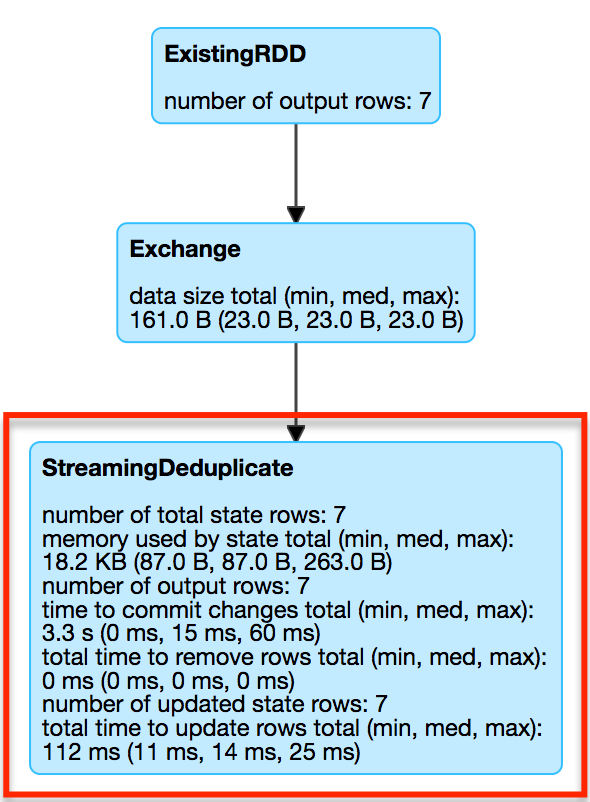
Figure 2. StreamingDeduplicateExec in web UI (Details for Query)
The output schema of StreamingDeduplicateExec is exactly the child's output schema.
The output partitioning of StreamingDeduplicateExec is exactly the child's output partitioning.
/**
// Start spark-shell with debugging and Kafka support
SPARK_SUBMIT_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005" \
./bin/spark-shell \
--packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.3.0-SNAPSHOT
*/
// Reading
val topic1 = spark.
readStream.
format("kafka").
option("subscribe", "topic1").
option("kafka.bootstrap.servers", "localhost:9092").
option("startingOffsets", "earliest").
load
// Processing with deduplication
// Don't use watermark
// The following won't work due to https://issues.apache.org/jira/browse/SPARK-21546
/**
val records = topic1.
withColumn("eventtime", 'timestamp). // <-- just to put the right name given the purpose
withWatermark(eventTime = "eventtime", delayThreshold = "30 seconds"). // <-- use the renamed eventtime column
dropDuplicates("value"). // dropDuplicates will use watermark
// only when eventTime column exists
// include the watermark column => internal design leak?
select('key cast "string", 'value cast "string", 'eventtime).
as[(String, String, java.sql.Timestamp)]
*/
val records = topic1.
dropDuplicates("value").
select('key cast "string", 'value cast "string").
as[(String, String)]
scala> records.explain
== Physical Plan ==
*Project [cast(key#0 as string) AS key#249, cast(value#1 as string) AS value#250]
+- StreamingDeduplicate [value#1], StatefulOperatorStateInfo(<unknown>,68198b93-6184-49ae-8098-006c32cc6192,0,0), 0
+- Exchange hashpartitioning(value#1, 200)
+- *Project [key#0, value#1]
+- StreamingRelation kafka, [key#0, value#1, topic#2, partition#3, offset#4L, timestamp#5, timestampType#6]
// Writing
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
import scala.concurrent.duration._
val sq = records.
writeStream.
format("console").
option("truncate", false).
trigger(Trigger.ProcessingTime(10.seconds)).
queryName("from-kafka-topic1-to-console").
outputMode(OutputMode.Update).
start
// Eventually...
sq.stop|
Tip
|
Enable Add the following line to Refer to Logging. |
Executing Physical Operator (Generating RDD[InternalRow]) — doExecute Method
doExecute(): RDD[InternalRow]|
Note
|
doExecute is part of SparkPlan Contract to generate the runtime representation of an physical operator as a distributed computation over internal binary rows on Apache Spark (i.e. RDD[InternalRow]).
|
Internally, doExecute initializes metrics.
doExecute executes child physical operator and creates a StateStoreRDD with storeUpdateFunction that:
-
Generates an unsafe projection to access the key field (using keyExpressions and the output schema of child).
-
Filters out rows from
Iterator[InternalRow]that matchwatermarkPredicateForData(when defined and timeoutConf isEventTimeTimeout) -
For every row (as
InternalRow)-
Extracts the key from the row (using the unsafe projection above)
-
Gets the saved state in
StateStorefor the key -
(when there was a state for the key in the row) Filters out (aka drops) the row
-
(when there was no state for the key in the row) Stores a new (and empty) state for the key and increments numUpdatedStateRows and numOutputRows metrics.
-
-
In the end,
storeUpdateFunctioncreates aCompletionIteratorthat executes a completion function (akacompletionFunction) after it has successfully iterated through all the elements (i.e. when a client has consumed all the rows).The completion function does the following:
-
Updates allUpdatesTimeMs metric (that is the total time to execute
storeUpdateFunction) -
Updates allRemovalsTimeMs metric with the time taken to remove keys older than the watermark from the StateStore
-
Updates commitTimeMs metric with the time taken to commit the changes to the StateStore
-
Creating StreamingDeduplicateExec Instance
StreamingDeduplicateExec takes the following when created:
-
Duplicate keys (as used in dropDuplicates operator)
Checking Out Whether Last Batch Execution Requires Another Non-Data Batch or Not — shouldRunAnotherBatch Method
shouldRunAnotherBatch(newMetadata: OffsetSeqMetadata): Boolean|
Note
|
shouldRunAnotherBatch is part of the StateStoreWriter Contract to indicate whether MicroBatchExecution should run another non-data batch (based on the updated OffsetSeqMetadata with the current event-time watermark and the batch timestamp).
|
shouldRunAnotherBatch…FIXME