import org.apache.spark.sql.streaming.Trigger
import scala.concurrent.duration._
val sq = spark
.readStream
.format("rate")
.load
.writeStream
.format("console")
.option("truncate", false)
.trigger(Trigger.Continuous(1.minute)) // <-- Gives ContinuousExecution
.queryName("rate2console")
.start
import org.apache.spark.sql.streaming.StreamingQuery
assert(sq.isInstanceOf[StreamingQuery])
// The following gives access to the internals
// And to ContinuousExecution
import org.apache.spark.sql.execution.streaming.StreamingQueryWrapper
val engine = sq.asInstanceOf[StreamingQueryWrapper].streamingQuery
import org.apache.spark.sql.execution.streaming.StreamExecution
assert(engine.isInstanceOf[StreamExecution])
import org.apache.spark.sql.execution.streaming.continuous.ContinuousExecution
val continuousEngine = engine.asInstanceOf[ContinuousExecution]
assert(continuousEngine.trigger == Trigger.Continuous(1.minute))ContinuousExecution — Stream Execution Engine of Continuous Stream Processing
ContinuousExecution is the stream execution engine of Continuous Stream Processing.
ContinuousExecution is created when StreamingQueryManager is requested to create a streaming query with a StreamWriteSupport sink and a ContinuousTrigger (when DataStreamWriter is requested to start an execution of the streaming query).
ContinuousExecution can only run streaming queries with StreamingRelationV2 with ContinuousReadSupport data source.
ContinuousExecution supports one ContinuousReader only in a streaming query (and asserts it when addOffset and committing an epoch). When requested for available streaming sources, ContinuousExecution simply gives the single ContinuousReader.
When created (for a streaming query), ContinuousExecution is given the analyzed logical plan. The analyzed logical plan is immediately transformed to include a ContinuousExecutionRelation for every StreamingRelationV2 with ContinuousReadSupport data source (and is the logical plan internally).
|
Note
|
ContinuousExecution uses the same instance of ContinuousExecutionRelation for the same instances of StreamingRelationV2 with ContinuousReadSupport data source.
|
When requested to run the streaming query, ContinuousExecution collects ContinuousReadSupport data sources (inside ContinuousExecutionRelation) from the analyzed logical plan and requests each and every ContinuousReadSupport to create a ContinuousReader (that are stored in continuousSources internal registry).
ContinuousExecution uses __epoch_coordinator_id local property for…FIXME
ContinuousExecution uses __continuous_start_epoch local property for…FIXME
ContinuousExecution uses __continuous_epoch_interval local property for…FIXME
|
Tip
|
Enable Add the following line to Refer to Logging. |
Running Activated Streaming Query — runActivatedStream Method
runActivatedStream(sparkSessionForStream: SparkSession): Unit|
Note
|
runActivatedStream is part of StreamExecution Contract to run a streaming query.
|
runActivatedStream simply runs the streaming query in continuous mode as long as the state is ACTIVE.
Running Streaming Query in Continuous Mode — runContinuous Internal Method
runContinuous(sparkSessionForQuery: SparkSession): UnitrunContinuous initializes the continuousSources internal registry by traversing the analyzed logical plan to find ContinuousExecutionRelation leaf logical operators and requests their ContinuousReadSupport data sources to create a ContinuousReader (with the sources metadata directory under the checkpoint directory).
runContinuous initializes the uniqueSources internal registry to be the continuousSources distinct.
runContinuous gets the start offsets (they may or may not be available).
runContinuous transforms the analyzed logical plan. For every ContinuousExecutionRelation runContinuous finds the corresponding ContinuousReader (in the continuousSources), requests it to deserialize the start offsets (from their JSON representation), and then setStartOffset. In the end, runContinuous creates a StreamingDataSourceV2Relation (with the read schema of the ContinuousReader and the ContinuousReader itself).
runContinuous rewires the transformed plan (with the StreamingDataSourceV2Relation) to use the new attributes from the source (the reader).
|
Note
|
CurrentTimestamp and CurrentDate expressions are not supported for continuous processing.
|
runContinuous requests the StreamWriteSupport to create a StreamWriter (with the run ID of the streaming query).
runContinuous creates a WriteToContinuousDataSource (with the StreamWriter and the transformed logical query plan).
runContinuous finds the only ContinuousReader (of the only StreamingDataSourceV2Relation) in the query plan with the WriteToContinuousDataSource.
In queryPlanning time-tracking section, runContinuous creates an IncrementalExecution (that becomes the lastExecution) that is immediately executed (i.e. the entire query execution pipeline is executed up to and including executedPlan).
runContinuous sets the following local properties:
-
__is_continuous_processing as
true -
__epoch_coordinator_id as the currentEpochCoordinatorId, i.e. runId followed by
--with a random UUID -
__continuous_epoch_interval as the interval of the ContinuousTrigger
runContinuous uses the EpochCoordinatorRef helper to create a remote reference to the EpochCoordinator RPC endpoint (with the StreamWriter, the ContinuousReader, the currentEpochCoordinatorId, and the currentBatchId).
|
Note
|
The EpochCoordinator RPC endpoint runs on the driver as the single point to coordinate epochs across partition tasks. |
runContinuous creates a daemon epoch update thread and starts it immediately.
In runContinuous time-tracking section, runContinuous requests the physical query plan (of the IncrementalExecution) to execute (that simply requests the physical operator to doExecute and generate an RDD[InternalRow]).
|
Note
|
runContinuous is used exclusively when ContinuousExecution is requested to run an activated streaming query.
|
Getting Start Offsets From Checkpoint — getStartOffsets Internal Method
getStartOffsets(sparkSessionToRunBatches: SparkSession): OffsetSeqgetStartOffsets…FIXME
|
Note
|
getStartOffsets is used exclusively when ContinuousExecution is requested to run a streaming query in continuous mode.
|
Committing Epoch — commit Method
commit(epoch: Long): UnitIn essence, commit adds the given epoch to commit log and the committedOffsets, and requests the ContinuousReader to commit the corresponding offset. In the end, commit removes old log entries from the offset and commit logs (to keep spark.sql.streaming.minBatchesToRetain entries only).
Internally, commit recordTriggerOffsets (with the from and to offsets as the committedOffsets and availableOffsets, respectively).
At this point, commit may simply return when the stream execution thread is no longer alive (died).
commit requests the commit log to store a metadata for the epoch.
commit requests the single ContinuousReader to deserialize the offset for the epoch (from the offset write-ahead log).
commit adds the single ContinuousReader and the offset (for the epoch) to the committedOffsets registry.
commit requests the single ContinuousReader to commit the offset.
commit requests the offset and commit logs to remove log entries to keep spark.sql.streaming.minBatchesToRetain only.
commit then acquires the awaitProgressLock, wakes up all threads waiting for the awaitProgressLockCondition and in the end releases the awaitProgressLock.
|
Note
|
commit supports only one continuous source (registered in the continuousSources internal registry).
|
commit asserts that the given epoch is available in the offsetLog internal registry (i.e. the offset for the given epoch has been reported before).
|
Note
|
commit is used exclusively when EpochCoordinator is requested to commitEpoch.
|
addOffset Method
addOffset(
epoch: Long,
reader: ContinuousReader,
partitionOffsets: Seq[PartitionOffset]): UnitIn essense, addOffset requests the given ContinuousReader to mergeOffsets (with the given PartitionOffsets) and then requests the OffsetSeqLog to register the offset with the given epoch.
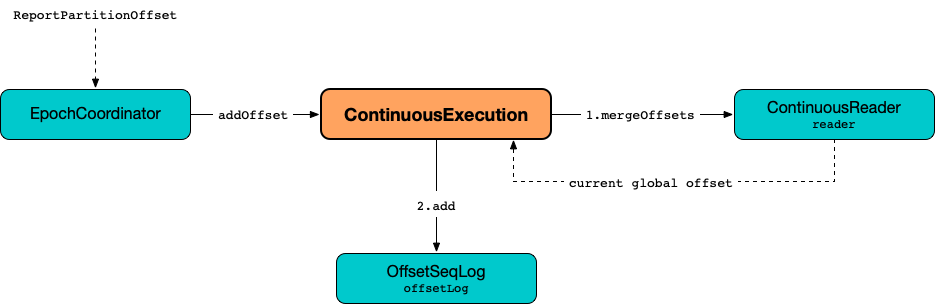
Figure 1. ContinuousExecution.addOffset
Internally, addOffset requests the given ContinuousReader to mergeOffsets (with the given PartitionOffsets) and to get the current "global" offset back.
addOffset then requests the OffsetSeqLog to add the current "global" offset for the given epoch.
addOffset requests the OffsetSeqLog for the offset at the previous epoch.
If the offsets at the current and previous epochs are the same, addOffset turns the noNewData internal flag on.
addOffset then acquires the awaitProgressLock, wakes up all threads waiting for the awaitProgressLockCondition and in the end releases the awaitProgressLock.
|
Note
|
addOffset supports exactly one continuous source.
|
|
Note
|
addOffset is used exclusively when EpochCoordinator is requested to handle a ReportPartitionOffset message.
|
Analyzed Logical Plan of Streaming Query — logicalPlan Property
logicalPlan: LogicalPlan|
Note
|
logicalPlan is part of StreamExecution Contract that is the analyzed logical plan of the streaming query.
|
logicalPlan resolves StreamingRelationV2 leaf logical operators (with a ContinuousReadSupport source) to ContinuousExecutionRelation leaf logical operators.
Internally, logicalPlan transforms the analyzed logical plan as follows:
-
For every StreamingRelationV2 leaf logical operator with a ContinuousReadSupport source,
logicalPlanlooks it up for the corresponding ContinuousExecutionRelation (if available in the internal lookup registry) or creates aContinuousExecutionRelation(with theContinuousReadSupportsource, the options and the output attributes of theStreamingRelationV2operator) -
For any other
StreamingRelationV2,logicalPlanthrows anUnsupportedOperationException:Data source [name] does not support continuous processing.
Creating ContinuousExecution Instance
ContinuousExecution takes the following when created:
ContinuousExecution initializes the internal properties.
Stopping Stream Processing (Execution of Streaming Query) — stop Method
stop(): Unit|
Note
|
stop is part of the StreamingQuery Contract to stop a streaming query.
|
stop transitions the streaming query to TERMINATED state.
If the queryExecutionThread is alive (i.e. it has been started and has not yet died), stop interrupts it and waits for this thread to die.
In the end, stop prints out the following INFO message to the logs:
Query [prettyIdString] was stopped|
Note
|
prettyIdString is in the format of queryName [id = [id], runId = [runId]].
|
awaitEpoch Internal Method
awaitEpoch(epoch: Long): UnitawaitEpoch…FIXME
|
Note
|
awaitEpoch seems to be used exclusively in tests.
|
Internal Properties
| Name | Description | ||
|---|---|---|---|
|
Registry of ContinuousReaders (in the analyzed logical plan of the streaming query) Used when Use sources to access the current value |
||
|
Used when…FIXME |
||
|
TriggerExecutor for the Trigger:
Used when…FIXME
|