StateStoreRDD — RDD for Updating State (in StateStores Across Spark Cluster)
StateStoreRDD is an RDD for executing storeUpdateFunction with StateStore (and data from partitions of the data RDD).
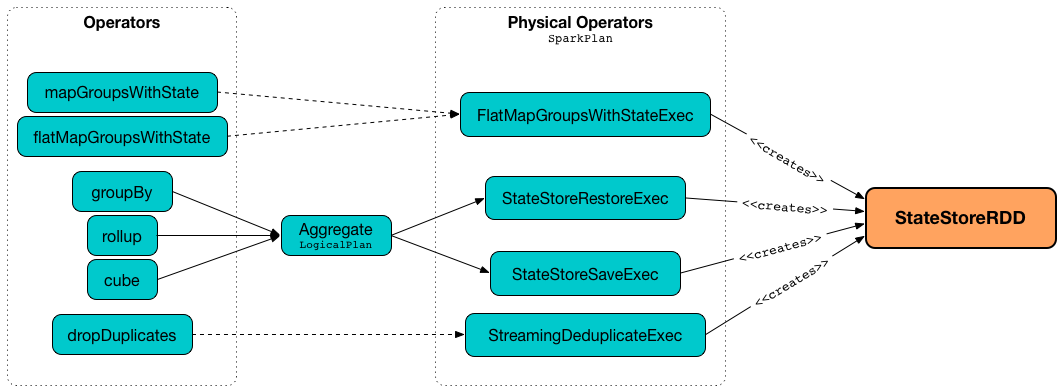
StateStoreRDD is created for the following stateful physical operators (using StateStoreOps.mapPartitionsWithStateStore):
Figure 1. StateStoreRDD, Physical and Logical Plans, and operators
StateStoreRDD uses StateStoreCoordinator for the preferred locations of a partition for job scheduling.

Figure 2. StateStoreRDD and StateStoreCoordinator
getPartitions is exactly the partitions of the data RDD.
Computing Partition — compute Method
compute(
partition: Partition,
ctxt: TaskContext): Iterator[U]|
Note
|
compute is part of the RDD Contract to compute a given partition.
|
compute computes dataRDD passing the result on to storeUpdateFunction (with a configured StateStore).
Internally, (and similarly to getPreferredLocations) compute creates a StateStoreProviderId with StateStoreId (using checkpointLocation, operatorId and the index of the input partition) and queryRunId.
compute then requests StateStore for the store for the StateStoreProviderId.
In the end, compute computes dataRDD (using the input partition and ctxt) followed by executing storeUpdateFunction (with the store and the result).
Placement Preferences of Partition (Preferred Locations) — getPreferredLocations Method
getPreferredLocations(partition: Partition): Seq[String]|
Note
|
getPreferredLocations is a part of the RDD Contract to specify placement preferences (aka preferred task locations), i.e. where tasks should be executed to be as close to the data as possible.
|
getPreferredLocations creates a StateStoreProviderId with StateStoreId (using checkpointLocation, operatorId and the index of the input partition) and queryRunId.
|
Note
|
checkpointLocation and operatorId are shared across different partitions and so the only difference in StateStoreProviderIds is the partition index. |
In the end, getPreferredLocations requests StateStoreCoordinatorRef for the location of the state store for the StateStoreProviderId.
|
Note
|
StateStoreCoordinator coordinates instances of StateStores across Spark executors in the cluster, and tracks their locations for job scheduling.
|
Creating StateStoreRDD Instance
StateStoreRDD takes the following to be created:
-
Store update function (
(StateStore, Iterator[T]) ⇒ Iterator[U]whereTis the type of rows in the data RDD) -
Optional StateStoreCoordinatorRef
StateStoreRDD initializes the internal properties.