package pl.japila.spark.sql.streaming
case class DemoSink(
sqlContext: SQLContext,
parameters: Map[String, String],
partitionColumns: Seq[String],
outputMode: OutputMode) extends Sink {
override def addBatch(batchId: Long, data: DataFrame): Unit = {
println(s"addBatch($batchId)")
data.explain()
// Why so many lines just to show the input DataFrame?
data.sparkSession.createDataFrame(
data.sparkSession.sparkContext.parallelize(data.collect()), data.schema)
.show(10)
}
}Demo: Developing Custom Streaming Sink (and Monitoring SQL Queries in web UI)
The demo shows the steps to develop a custom streaming sink and use it to monitor whether and what SQL queries are executed at runtime (using web UI’s SQL tab).
|
Note
|
The main motivation was to answer the question Why does a single structured query run multiple SQL queries per batch? that happened to have turned out fairly surprising. You’re very welcome to upvote the question and answers at your earliest convenience. Thanks! |
The steps are as follows:
Findings (aka surprises):
-
Custom sinks require that you define a checkpoint location using checkpointLocation option (or spark.sql.streaming.checkpointLocation Spark property). Remove the checkpoint directory (or use a different one every start of a streaming query) to have consistent results.
Creating Custom Sink — DemoSink
A streaming sink follows the Sink contract and a sample implementation could look as follows.
Save the file under src/main/scala in your project.
Creating StreamSinkProvider — DemoSinkProvider
package pl.japila.spark.sql.streaming
class DemoSinkProvider extends StreamSinkProvider
with DataSourceRegister {
override def createSink(
sqlContext: SQLContext,
parameters: Map[String, String],
partitionColumns: Seq[String],
outputMode: OutputMode): Sink = {
DemoSink(sqlContext, parameters, partitionColumns, outputMode)
}
override def shortName(): String = "demo"
}Save the file under src/main/scala in your project.
Optional Sink Registration using META-INF/services
The step is optional, but greatly improve the experience when using the custom sink so you can use it by its name (rather than a fully-qualified class name or using a special class name for the sink provider).
Create org.apache.spark.sql.sources.DataSourceRegister in META-INF/services directory with the following content.
pl.japila.spark.sql.streaming.DemoSinkProviderSave the file under src/main/resources in your project.
build.sbt Definition
If you use my beloved build tool sbt to manage the project, use the following build.sbt.
organization := "pl.japila.spark"
name := "spark-structured-streaming-demo-sink"
version := "0.1"
scalaVersion := "2.11.11"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.2.0"Packaging DemoSink
The step depends on what build tool you use to manage the project. Use whatever command you use to create a jar file with the above classes compiled and bundled together.
$ sbt package
[info] Loading settings from plugins.sbt ...
[info] Loading project definition from /Users/jacek/dev/sandbox/spark-structured-streaming-demo-sink/project
[info] Loading settings from build.sbt ...
[info] Set current project to spark-structured-streaming-demo-sink (in build file:/Users/jacek/dev/sandbox/spark-structured-streaming-demo-sink/)
[info] Compiling 1 Scala source to /Users/jacek/dev/sandbox/spark-structured-streaming-demo-sink/target/scala-2.11/classes ...
[info] Done compiling.
[info] Packaging /Users/jacek/dev/sandbox/spark-structured-streaming-demo-sink/target/scala-2.11/spark-structured-streaming-demo-sink_2.11-0.1.jar ...
[info] Done packaging.
[success] Total time: 5 s, completed Sep 12, 2017 9:34:19 AMThe jar with the sink is /Users/jacek/dev/sandbox/spark-structured-streaming-demo-sink/target/scala-2.11/spark-structured-streaming-demo-sink_2.11-0.1.jar.
Using DemoSink in Streaming Query
The following code reads data from the rate source and simply outputs the result to our custom DemoSink.
// Make sure the DemoSink jar is available
$ ls /Users/jacek/dev/sandbox/spark-structured-streaming-demo-sink/target/scala-2.11/spark-structured-streaming-demo-sink_2.11-0.1.jar
/Users/jacek/dev/sandbox/spark-structured-streaming-demo-sink/target/scala-2.11/spark-structured-streaming-demo-sink_2.11-0.1.jar
// "Install" the DemoSink using --jars command-line option
$ ./bin/spark-shell --jars /Users/jacek/dev/sandbox/spark-structured-streaming-custom-sink/target/scala-2.11/spark-structured-streaming-custom-sink_2.11-0.1.jar
scala> spark.version
res0: String = 2.3.0-SNAPSHOT
import org.apache.spark.sql.streaming._
import scala.concurrent.duration._
val sq = spark.
readStream.
format("rate").
load.
writeStream.
format("demo").
option("checkpointLocation", "/tmp/demo-checkpoint").
trigger(Trigger.ProcessingTime(10.seconds)).
start
// In the end...
scala> sq.stop
17/09/12 09:59:28 INFO StreamExecution: Query [id = 03cd78e3-94e2-439c-9c12-cfed0c996812, runId = 6938af91-9806-4404-965a-5ae7525d5d3f] was stoppedMonitoring SQL Queries using web UI’s SQL Tab
You should find that every trigger (aka batch) results in 3 SQL queries. Why?
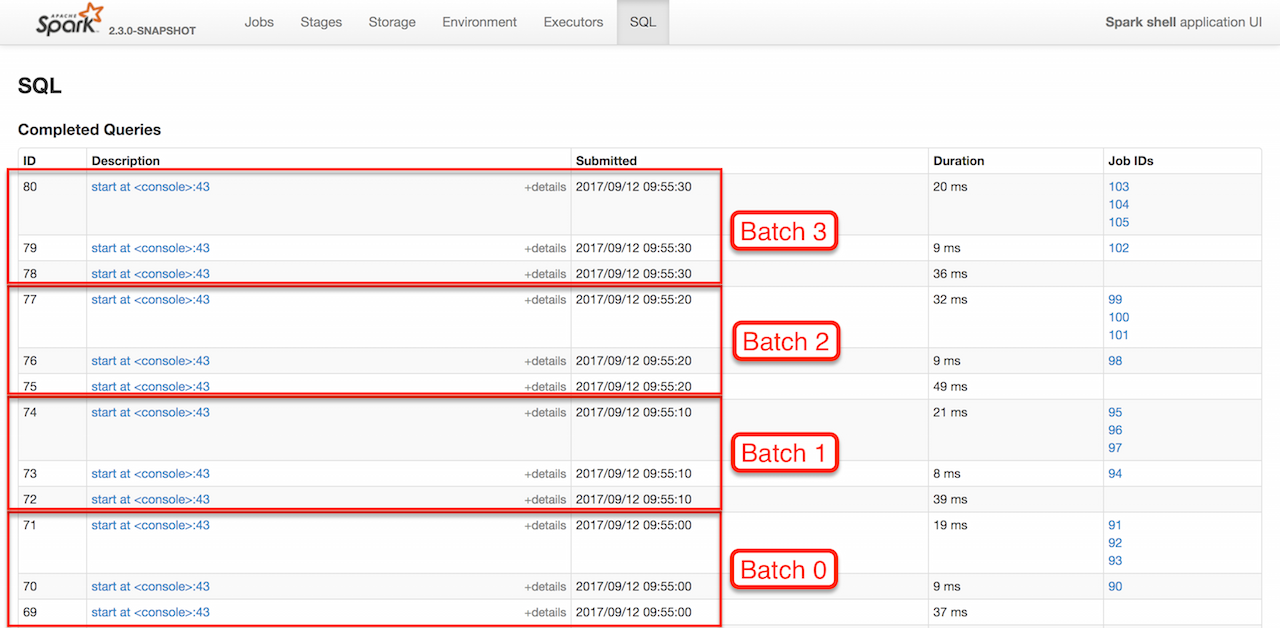
Figure 1. web UI’s SQL Tab and Completed Queries (3 Queries per Batch)
The answer lies in what sources and sink a streaming query uses (and differs per streaming query).
In our case, DemoSink collects the rows from the input DataFrame and shows it afterwards. That gives 2 SQL queries (as you can see after executing the following batch queries).
// batch non-streaming query
val data = (0 to 3).toDF("id")
// That gives one SQL query
data.collect
// That gives one SQL query, too
data.showThe remaining query (which is the first among the queries) is executed when you load the data.
That can be observed easily when you change DemoSink to not "touch" the input data (in addBatch) in any way.
override def addBatch(batchId: Long, data: DataFrame): Unit = {
println(s"addBatch($batchId)")
}Re-run the streaming query (using the new DemoSink) and use web UI’s SQL tab to see the queries. You should have just one query per batch (and no Spark jobs given nothing is really done in the sink’s addBatch).

Figure 2. web UI’s SQL Tab and Completed Queries (1 Query per Batch)