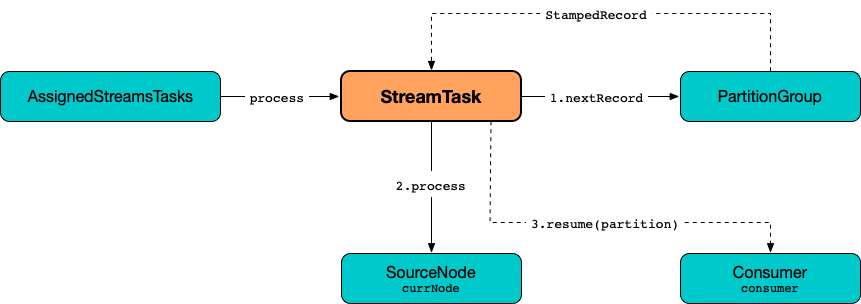
StreamTask
StreamTask is a concrete stream processor task that uses a PartitionGroup (with the partitions assigned) to determine which record should be processed (as ordered by partition timestamp).
When requested to process a single record, StreamTask requests the PartitionGroup for the next stamped record (record with timestamp) and the RecordQueue. StreamTask uses a RecordInfo to hold the RecordQueue (with the source processor node and the partition) of the currently-processed stamped record. Eventually, StreamTask requests the source processor node (of the RecordQueue and the partition) to process the record.
Figure 1. StreamTask and Processing Single Record
|
Note
|
It is at the discretion of a processor node (incl. a source processor node) to forward the record downstream (to child processors if there are any). |
StreamTask is created exclusively when TaskCreator is requested to create one.
StreamTask is a concrete ProcessorNodePunctuator that can punctuate processors (execute scheduled periodic actions).
When requested to initialize a processor topology (as a task), StreamTask…FIXME
StreamTask uses commitOffsetNeeded flag to…FIXME
StreamTask uses buffered.records.per.partition configuration property (default: 1000) to control whether to pause or resume a partition (when processing a single record or bufferring new records, respectively).
StreamTask uses max.task.idle.ms configuration property (default: 0L) to…FIXME
|
Tip
|
Enable Add the following line to Refer to Application Logging Using log4j. |
Creating StreamTask Instance
StreamTask takes the following to be created:
-
Assigned partitions (Kafka TopicPartition)
-
Kafka Consumer (
Consumer<byte[], byte[]>)
StreamTask initializes the internal properties.
StreamTask and PartitionGroup (of RecordCollectors per Assigned Partition)
StreamTask creates a PartitionGroup (with RecordQueues per every partition assigned) when…FIXME
StreamTask uses the PartitionGroup for the following:
StreamTask and RecordCollector
StreamTask creates a new RecordCollector (or is given one for testing) when created.
The RecordCollector is requested to initialize (with the Kafka Producer) when StreamTask is created and resumed.
StreamTask uses the RecordCollector for the following:
The RecordCollector is requested to close when StreamTask is requested to suspend and maybeAbortTransactionAndCloseRecordCollector.
Suspending Task — suspend Method
void suspend() (1)
// PRIVATE API
suspend(boolean clean, boolean isZombie)-
Uses
cleanenabled (true) andisZombiedisabled (false)
|
Note
|
suspend is part of Task Contract to suspend the task.
|
suspend prints out the following DEBUG message to the logs:
Suspendingsuspend closes the processor topology.
With clean flag enabled (true), suspend commits the task (with startNewTransaction flag disabled) first. With exactly-once support enabled, suspend requests the ProcessorStateManager to checkpoint (with the checkpointable offsets) and the RecordCollector to close.
With clean flag disabled (false), suspend maybeAbortTransactionAndCloseRecordCollector.
|
Note
|
The private suspend is used when StreamTask is requested to close.
|
maybeAbortTransactionAndCloseRecordCollector Internal Method
void maybeAbortTransactionAndCloseRecordCollector(
boolean isZombie)maybeAbortTransactionAndCloseRecordCollector…FIXME
|
Note
|
maybeAbortTransactionAndCloseRecordCollector is used exclusively when suspend (with clean flag disabled).
|
Closing Processor Topology — closeTopology Internal Method
void closeTopology()closeTopology prints out the following TRACE message to the logs:
Closing processor topologycloseTopology requests the PartitionGroup to clear.
With the task initialized, closeTopology requests every ProcessorNode (in the ProcessorTopology) to close.
In case of RuntimeException while closing ProcessorNodes, closeTopology re-throws it.
|
Note
|
closeTopology is used exclusively when StreamTask is requested to suspend.
|
Closing Task — close Method
void close(
boolean clean,
boolean isZombie)|
Note
|
close is part of Task Contract to close the task.
|
close prints out the following DEBUG message to the logs:
Closingclose suspends the task followed by closeSuspended. In the end, close sets the taskClosed flag off (false).
Initializing Topology (of Processor Nodes) — initializeTopology Method
void initializeTopology()|
Note
|
initializeTopology is part of Task Contract to initialize a topology of processor nodes.
|
initializeTopology initialize the ProcessorNodes in the ProcessorTopology.
With exactly-once support enabled, initializeTopology requests the Kafka Producer to start a new transaction (using Producer.beginTransaction) and turns the transactionInFlight flag on.
initializeTopology then requests the InternalProcessorContext to initialize.
In the end, initializeTopology turns the taskInitialized flag on (true) and the idleStartTime to UNKNOWN.
Initializing ProcessorNodes (in ProcessorTopology) — initTopology Internal Method
void initTopology()initTopology prints out the following TRACE message to the logs:
Initializing processor nodes of the topologyinitTopology then walks over all the processor nodes in the topology and requests them to initialize (one by one). While doing this node initialization, initTopology requests the InternalProcessorContext to set the current node to the processor node that is currently initialized and, after initialization, resets the current node (to null).
|
Note
|
initTopology is used exclusively when StreamTask is requested to initialize the topology.
|
Processing Single Record — process Method
boolean process()process processes a single record and returns true when processed successfully, and false when there were no records to process.
Internally, process requests the PartitionGroup for the next stamped record (record with timestamp) and the RecordQueue (with the RecordInfo).
Figure 2. StreamTask and Processing Single Record
process prints out the following TRACE message to the logs:
Start processing one record [record]process requests the RecordInfo for the source processor node.
process updates the ProcessorContext to hold the current record and the source processor node.
process requests the source processor node to process the record.
process prints out the following TRACE message to the logs:
Completed processing one record [record]process requests the RecordInfo for the partition and stores it and the record’s offset in the consumedOffsets internal registry.
process turns the commitNeeded flag on (true).
(only if the size of the queue of the RecordInfo is exactly buffered.records.per.partition configuration property (default: 1000)) process requests the Kafka consumer to resume the partition (and consume records from the partition again).
process resets the current node (and requests the InternalProcessorContext to set the current node to be null).
In case of a ProducerFencedException, process throws a TaskMigratedException.
In case of a KafkaException, process throws a StreamsException.
|
Note
|
process is used exclusively when AssignedStreamsTasks is requested to request the running stream tasks to process records (one record per task).
|
closeSuspended Method
void closeSuspended(
boolean clean,
boolean isZombie,
RuntimeException firstException)|
Note
|
closeSuspended is part of Task Contract to…FIXME.
|
closeSuspended…FIXME
Buffering New Records (From Partition) — addRecords Method
void addRecords(
TopicPartition partition,
Iterable<ConsumerRecord<byte[], byte[]>> records)addRecords simply requests the PartitionGroup to add the new records to the RecordQueue for the specified partition.
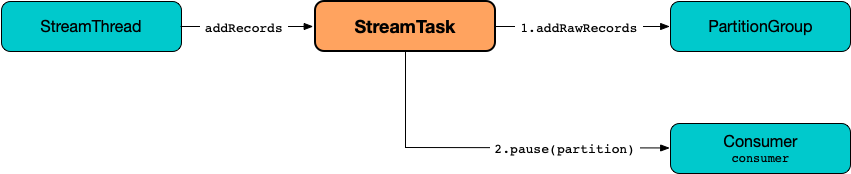
Figure 3. StreamTask and Buffering New Records
addRecords prints out the following TRACE message to the logs:
Added records into the buffered queue of partition [partition], new queue size is [newQueueSize]When the size of the buffered record queue exceeds buffered.records.per.partition configuration property, addRecords requests the Kafka Consumer to pause the partition.
|
Note
|
addRecords uses Consumer.pause method to "pause the partition", i.e. to suspend fetching from the requested partitions. Future calls to KafkaConsumer.poll will not return any records from these partitions until they have been resumed using KafkaConsumer.resume.
|
|
Note
|
|
Punctuating Processor (Executing Scheduled Periodic Action) — punctuate Method
void punctuate(
ProcessorNode node,
long timestamp,
PunctuationType type,
Punctuator punctuator)|
Note
|
punctuate is part of ProcessorNodePunctuator Contract to punctuate a processor.
|
punctuate updateProcessorContext with a "dummy" stamped record and the given ProcessorNode.
punctuate prints out the following TRACE message to the logs:
Punctuating processor [name] with timestamp [timestamp] and punctuation type [type]In the end, punctuate requests the given ProcessorNode to punctuate.
In case of a ProducerFencedException, punctuate throws a TaskMigratedException.
In case of a KafkaException, punctuate throws a StreamsException:
[logPrefix]Exception caught while punctuating processor '[name]' Attempting to Punctuate by Stream Time — maybePunctuateStreamTime Method
boolean maybePunctuateStreamTime()maybePunctuateStreamTime requests the PartitionGroup for the minimum partition timestamp across all partitions.
maybePunctuateStreamTime requests the stream-time PunctuationQueue to mayPunctuate with the minimum timestamp.
In the end, maybePunctuateStreamTime returns whatever the stream-time PunctuationQueue returned.
If the minimum timestamp is UNKNOWN, maybePunctuateStreamTime returns false.
|
Note
|
maybePunctuateStreamTime is used exclusively when AssignedStreamsTasks is requested to punctuate running stream tasks.
|
Attempting to Punctuate by System Time — maybePunctuateSystemTime Method
boolean maybePunctuateSystemTime()maybePunctuateSystemTime…FIXME
|
Note
|
maybePunctuateSystemTime is used exclusively when AssignedStreamsTasks is requested to punctuate running stream tasks.
|
Scheduling Cancellable Periodic Action (Punctuator) — schedule Method
// PUBLIC API
Cancellable schedule(
long interval,
PunctuationType type,
Punctuator punctuator)
// PACKAGE PROTECTED
Cancellable schedule(
long startTime,
long interval,
PunctuationType type,
Punctuator punctuator)schedule chooses the PunctuationQueue and the startTime per the specified PunctuationType that can either be STREAM_TIME or WALL_CLOCK_TIME.
For STREAM_TIME, schedule always uses 0L as the startTime and the stream-time PunctuationQueue.
For WALL_CLOCK_TIME, schedule uses the current time and the specified interval as the startTime and the system-time PunctuationQueue.
schedule then creates a new PunctuationSchedule (with the current processor of the InternalProcessorContext) and requests the appropriate PunctuationQueue to schedule it.
|
Note
|
schedule is used exclusively when ProcessorContextImpl is requested to schedule a cancellable periodic action.
|
Initializing State Stores — initializeStateStores Method
boolean initializeStateStores()|
Note
|
initializeStateStores is part of Task Contract to initialize state stores.
|
initializeStateStores prints out the following TRACE message to the logs:
Initializing state storesinitializeStateStores registerStateStores.
In the end, initializeStateStores returns true if the task has any changelog partitions. Otherwise, initializeStateStores returns false.
Committing Task — commit Method
void commit() (1)
void commit(
boolean startNewTransaction)-
Uses
startNewTransactionflag enabled (true)
|
Note
|
commit is part of Task Contract to commit the task.
|
commit simply commits with the startNewTransaction flag enabled (true).
commit Internal Method
void commit(
boolean startNewTransaction)commit prints out the following DEBUG message to the logs:
Committingcommit flushState.
(only when exactly-once support is disabled) commit requests the ProcessorStateManager to checkpoint with the checkpointable offsets.
For every partition and offset (in the consumedOffsets internal registry), commit requests the ProcessorStateManager to putOffsetLimit with the partition and the offset incremented.
(only when exactly-once support is disabled), commit requests the Consumer to synchronously commit (Consumer.commitSync) the partitions and offsets from the consumedOffsets internal registry).
|
Note
|
Consumer.commitSync commits the specified offsets for a given list of partitions. This commits offsets to Kafka. The offsets committed using this API will be used on the first fetch after every rebalance and also on startup. The committed offset should be the next message your application will consume (and that’s why the offsets are incremented).
|
With exactly-once support enabled, commit requests the Producer to sendOffsetsToTransaction for the partitions and offsets in the consumedOffsets internal registry and the applicationId. commit requests the Producer to commitTransaction and sets the transactionInFlight off (false). With the given transactionInFlight enabled (true), commit requests the Producer to beginTransaction and sets the transactionInFlight on (true).
In the end, commit sets the commitNeeded and commitRequested flags off (false), and requests the TaskMetrics for the taskCommitTimeSensor to record the duration (i.e. the time since commit was executed).
activeTaskCheckpointableOffsets Method
Map<TopicPartition, Long> activeTaskCheckpointableOffsets()|
Note
|
activeTaskCheckpointableOffsets is part of the AbstractTask Contract to return the checkpointable offsets.
|
activeTaskCheckpointableOffsets…FIXME
Flushing State Stores And Producer (RecordCollector) — flushState Method
void flushState()|
Note
|
flushState is part of AbstractTask Contract to flush all state stores registered with the task.
|
flushState prints out the following TRACE message to the logs:
Flushing state and producerflushState flushes state stores.
flushState requests the RecordCollector to flush (the internal Kafka producer).
isProcessable Method
boolean isProcessable(
long now)isProcessable returns true when one of the following is met:
-
All RecordQueues have at least one record buffered of the PartitionGroup
-
The task is enforced to be processable, i.e. the time between
nowand the idleStartTime is at least or larger than the max.task.idle.ms configuration property (default:0L)
Otherwise, isProcessable returns false.
|
Note
|
(FIXME) isProcessable does some minor accounting.
|
|
Note
|
isProcessable is used exclusively when AssignedStreamsTasks is requested to request the running stream tasks to process records (one record per task).
|
Resuming Task — resume Method
void resume()|
Note
|
resume is part of the Task Contract to resume the task.
|
resume prints out the following DEBUG message to the logs:
Resumingresume then does further processing only when Exactly-Once Support is enabled.
resume…FIXME
numBuffered Method
int numBuffered()numBuffered simply requests the PartitionGroup for the numBuffered.
|
Note
|
numBuffered seems to be used for tests only.
|
Requesting Commit — requestCommit Method
void requestCommit()requestCommit simply turns the commitRequested internal flag on (true).
|
Note
|
requestCommit is used exclusively when ProcessorContextImpl is requested to commit.
|
Purgable Offsets of Repartition Topics (of Topology) — purgableOffsets Method
Map<TopicPartition, Long> purgableOffsets()In essence, purgableOffsets returns the partition-offset pairs for the consumedOffsets of the repartition topics (i.e. the ProcessorTopology uses as repartition topics).
purgableOffsets…FIXME
|
Note
|
purgableOffsets is used exclusively when AssignedStreamsTasks is requested for the purgable offsets of the repartition topics (of a topology).
|
initializeTransactions Internal Method
void initializeTransactions()initializeTransactions simply requests the Producer to initTransactions.
In case of TimeoutException, initializeTransactions prints out the following ERROR message to the logs:
Timeout exception caught when initializing transactions for task [id]. This might happen if the broker is slow to respond, if the network connection to the broker was interrupted, or if similar circumstances arise. You can increase producer parameter `max.block.ms` to increase this timeout.In the end, initializeTransactions throws a StreamsException.
[logPrefix]Failed to initialize task [id] due to timeout.|
Note
|
initializeTransactions is used when StreamTask is created and requested to resume (both with exactly-once support enabled).
|
Updating InternalProcessorContext — updateProcessorContext Internal Method
void updateProcessorContext(
StampedRecord record,
ProcessorNode currNode)updateProcessorContext requests the InternalProcessorContext to set the current ProcessorRecordContext to a new ProcessorRecordContext (per the input StampedRecord).
updateProcessorContext then requests the InternalProcessorContext to set the current ProcessorNode to the input ProcessorNode.
|
Note
|
updateProcessorContext is used when StreamTask is requested to process a single record and execute a scheduled periodic action (aka punctuate).
|
Internal Properties
| Name | Description |
|---|---|
|
Flag that indicates whether a commit was requested ( Default: Disabled ( Used exclusively when |
|
Consumer offsets by TopicPartitions ( Used when requested for the purgable offsets of the repartition topics of a topology, to activeTaskCheckpointableOffsets, and to commit |
|
|
|
Kafka Producer ( Created when Cleared (nullified) when Used for the following:
|
|
RecordInfo (that holds a RecordQueue with the source processor node and the partition the currently-processed stamped record came from) Created empty alongside the StreamTask and "fill up" with the RecordQueue when requested to process a single record |
|
|
|
|
|
TaskMetrics for the TaskId and the StreamsMetricsImpl Used when
|
|
Flag that controls whether the producer should abort transaction (with exactly-once support enabled) Default:
|