// arguably the most trivial example
// just a dataset of 3 rows per group
// to demo how partitions and frames work
// note the rows per groups are not consecutive (in the middle)
val metrics = Seq(
(0, 0, 0), (1, 0, 1), (2, 5, 2), (3, 0, 3), (4, 0, 1), (5, 5, 3), (6, 5, 0)
).toDF("id", "device", "level")
scala> metrics.show
+---+------+-----+
| id|device|level|
+---+------+-----+
| 0| 0| 0|
| 1| 0| 1|
| 2| 5| 2| // <-- this row for device 5 is among the rows of device 0
| 3| 0| 3| // <-- as above but for device 0
| 4| 0| 1| // <-- almost as above but there is a group of two rows for device 0
| 5| 5| 3|
| 6| 5| 0|
+---+------+-----+
// create windows of rows to use window aggregate function over every window
import org.apache.spark.sql.expressions.Window
val rangeWithTwoDevicesById = Window.
partitionBy('device).
orderBy('id).
rangeBetween(start = -1, end = Window.currentRow) // <-- demo rangeBetween first
val sumOverRange = metrics.withColumn("sum", sum('level) over rangeWithTwoDevicesById)
// Logical plan with Window unary logical operator
val optimizedPlan = sumOverRange.queryExecution.optimizedPlan
scala> println(optimizedPlan)
Window [sum(cast(level#9 as bigint)) windowspecdefinition(device#8, id#7 ASC NULLS FIRST, RANGE BETWEEN 1 PRECEDING AND CURRENT ROW) AS sum#15L], [device#8], [id#7 ASC NULLS FIRST]
+- LocalRelation [id#7, device#8, level#9]
// Physical plan with WindowExec unary physical operator (shown as Window)
scala> sumOverRange.explain
== Physical Plan ==
Window [sum(cast(level#9 as bigint)) windowspecdefinition(device#8, id#7 ASC NULLS FIRST, RANGE BETWEEN 1 PRECEDING AND CURRENT ROW) AS sum#15L], [device#8], [id#7 ASC NULLS FIRST]
+- *Sort [device#8 ASC NULLS FIRST, id#7 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(device#8, 200)
+- LocalTableScan [id#7, device#8, level#9]
// Going fairly low-level...you've been warned
val plan = sumOverRange.queryExecution.executedPlan
import org.apache.spark.sql.execution.window.WindowExec
val we = plan.asInstanceOf[WindowExec]
val windowRDD = we.execute()
scala> :type windowRDD
org.apache.spark.rdd.RDD[org.apache.spark.sql.catalyst.InternalRow]
scala> windowRDD.toDebugString
res0: String =
(200) MapPartitionsRDD[5] at execute at <console>:35 []
| MapPartitionsRDD[4] at execute at <console>:35 []
| ShuffledRowRDD[3] at execute at <console>:35 []
+-(7) MapPartitionsRDD[2] at execute at <console>:35 []
| MapPartitionsRDD[1] at execute at <console>:35 []
| ParallelCollectionRDD[0] at execute at <console>:35 []
// no computation on the source dataset has really occurred
// Let's trigger a RDD action
scala> windowRDD.first
res0: org.apache.spark.sql.catalyst.InternalRow = [0,2,5,2,2]
scala> windowRDD.foreach(println)
[0,2,5,2,2]
[0,0,0,0,0]
[0,5,5,3,3]
[0,6,5,0,3]
[0,1,0,1,1]
[0,3,0,3,3]
[0,4,0,1,4]
scala> sumOverRange.show
+---+------+-----+---+
| id|device|level|sum|
+---+------+-----+---+
| 2| 5| 2| 2|
| 5| 5| 3| 3|
| 6| 5| 0| 3|
| 0| 0| 0| 0|
| 1| 0| 1| 1|
| 3| 0| 3| 3|
| 4| 0| 1| 4|
+---+------+-----+---+
// use rowsBetween
val rowsWithTwoDevicesById = Window.
partitionBy('device).
orderBy('id).
rowsBetween(start = -1, end = Window.currentRow)
val sumOverRows = metrics.withColumn("sum", sum('level) over rowsWithTwoDevicesById)
// let's see the result first to have them close
// and compare row- vs range-based windows
scala> sumOverRows.show
+---+------+-----+---+
| id|device|level|sum|
+---+------+-----+---+
| 2| 5| 2| 2|
| 5| 5| 3| 5| <-- a difference
| 6| 5| 0| 3|
| 0| 0| 0| 0|
| 1| 0| 1| 1|
| 3| 0| 3| 4| <-- another difference
| 4| 0| 1| 4|
+---+------+-----+---+
val rowsOptimizedPlan = sumOverRows.queryExecution.optimizedPlan
scala> println(rowsOptimizedPlan)
Window [sum(cast(level#901 as bigint)) windowspecdefinition(device#900, id#899 ASC NULLS FIRST, ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS sum#1458L], [device#900], [id#899 ASC NULLS FIRST]
+- LocalRelation [id#899, device#900, level#901]
scala> sumOverRows.explain
== Physical Plan ==
Window [sum(cast(level#901 as bigint)) windowspecdefinition(device#900, id#899 ASC NULLS FIRST, ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS sum#1458L], [device#900], [id#899 ASC NULLS FIRST]
+- *Sort [device#900 ASC NULLS FIRST, id#899 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(device#900, 200)
+- LocalTableScan [id#899, device#900, level#901]WindowExec Unary Physical Operator
WindowExec is a unary physical operator (i.e. with one child physical operator) for window aggregation execution (i.e. represents Window unary logical operator at execution time).
WindowExec is created exclusively when BasicOperators execution planning strategy resolves a Window unary logical operator.
// a more involved example
val dataset = spark.range(start = 0, end = 13, step = 1, numPartitions = 4)
import org.apache.spark.sql.expressions.Window
val groupsOrderById = Window.partitionBy('group).rangeBetween(-2, Window.currentRow).orderBy('id)
val query = dataset.
withColumn("group", 'id % 4).
select('*, sum('id) over groupsOrderById as "sum")
scala> query.explain
== Physical Plan ==
Window [sum(id#25L) windowspecdefinition(group#244L, id#25L ASC NULLS FIRST, RANGE BETWEEN 2 PRECEDING AND CURRENT ROW) AS sum#249L], [group#244L], [id#25L ASC NULLS FIRST]
+- *Sort [group#244L ASC NULLS FIRST, id#25L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(group#244L, 200)
+- *Project [id#25L, (id#25L % 4) AS group#244L]
+- *Range (0, 13, step=1, splits=4)
val plan = query.queryExecution.executedPlan
import org.apache.spark.sql.execution.window.WindowExec
val we = plan.asInstanceOf[WindowExec]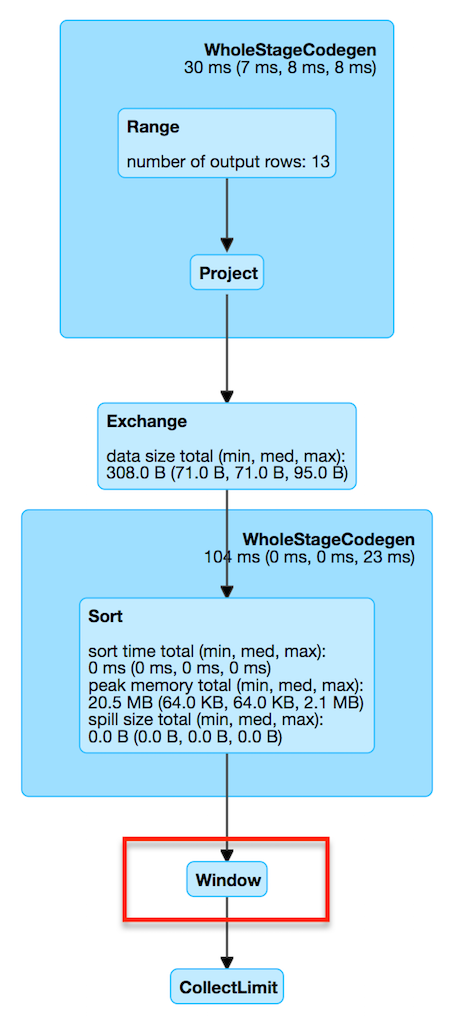
Figure 1. WindowExec in web UI (Details for Query)
The output schema of WindowExec are the attributes of the child physical operator and the window expressions.
// the whole schema is as follows
val schema = query.queryExecution.executedPlan.output.toStructType
scala> println(schema.treeString)
root
|-- id: long (nullable = false)
|-- group: long (nullable = true)
|-- sum: long (nullable = true)
// Let's see ourselves how the schema is made up of
scala> :type we
org.apache.spark.sql.execution.window.WindowExec
// child's output
scala> println(we.child.output.toStructType.treeString)
root
|-- id: long (nullable = false)
|-- group: long (nullable = true)
// window expressions' output
val weExprSchema = we.windowExpression.map(_.toAttribute).toStructType
scala> println(weExprSchema.treeString)
root
|-- sum: long (nullable = true)The required child output distribution of a WindowExec operator is one of the following:
-
AllTuples when the window partition specification expressions is empty
-
ClusteredDistribution (with the window partition specification expressions) with the partition specification specified
If no window partition specification is specified, WindowExec prints out the following WARN message to the logs:
WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.|
Tip
|
Enable Add the following line to Refer to Logging. |
Executing Physical Operator (Generating RDD[InternalRow]) — doExecute Method
doExecute(): RDD[InternalRow]|
Note
|
doExecute is part of SparkPlan Contract to generate the runtime representation of a structured query as a distributed computation over internal binary rows on Apache Spark (i.e. RDD[InternalRow]).
|
doExecute executes the single child physical operator and maps over partitions using a custom Iterator[InternalRow].
|
Note
|
When executed, doExecute creates a MapPartitionsRDD with the child physical operator’s RDD[InternalRow].
|
scala> :type we
org.apache.spark.sql.execution.window.WindowExec
val windowRDD = we.execute
scala> :type windowRDD
org.apache.spark.rdd.RDD[org.apache.spark.sql.catalyst.InternalRow]
scala> println(windowRDD.toDebugString)
(200) MapPartitionsRDD[5] at execute at <console>:35 []
| MapPartitionsRDD[4] at execute at <console>:35 []
| ShuffledRowRDD[3] at execute at <console>:35 []
+-(7) MapPartitionsRDD[2] at execute at <console>:35 []
| MapPartitionsRDD[1] at execute at <console>:35 []
| ParallelCollectionRDD[0] at execute at <console>:35 []Internally, doExecute first takes WindowExpressions and their WindowFunctionFrame factory functions (from window frame factories) followed by executing the single child physical operator and mapping over partitions (using RDD.mapPartitions operator).
doExecute creates an Iterator[InternalRow] (of UnsafeRow exactly).
Mapping Over UnsafeRows per Partition — Iterator[InternalRow]
When created, Iterator[InternalRow] first creates two UnsafeProjection conversion functions (to convert InternalRows to UnsafeRows) as result and grouping.
|
Note
|
grouping conversion function is created for window partition specifications expressions and used exclusively to create nextGroup when Iterator[InternalRow] is requested next row.
|
|
Tip
|
Enable Add the following line to Refer to Logging. |
Iterator[InternalRow] then fetches the first row from the upstream RDD and initializes nextRow and nextGroup UnsafeRows.
|
Note
|
nextGroup is the result of converting nextRow using grouping conversion function.
|
doExecute creates a ExternalAppendOnlyUnsafeRowArray buffer using spark.sql.windowExec.buffer.spill.threshold property (default: 4096) as the threshold for the number of rows buffered.
doExecute creates a SpecificInternalRow for the window function result (as windowFunctionResult).
|
Note
|
SpecificInternalRow is also used in the generated code for the UnsafeProjection for the result.
|
doExecute takes the window frame factories and generates WindowFunctionFrame per factory (using the SpecificInternalRow created earlier).
|
Caution
|
FIXME |
|
Note
|
ExternalAppendOnlyUnsafeRowArray is used to collect UnsafeRow objects from the child’s partitions (one partition per buffer and up to spark.sql.windowExec.buffer.spill.threshold).
|
next Method
override final def next(): InternalRow|
Note
|
next is part of Scala’s scala.collection.Iterator interface that returns the next element and discards it from the iterator.
|
next method of the final Iterator is…FIXME
next first fetches a new partition, but only when…FIXME
|
Note
|
next loads all the rows in nextGroup.
|
|
Caution
|
FIXME What’s nextGroup?
|
next takes one UnsafeRow from bufferIterator.
|
Caution
|
FIXME bufferIterator seems important for the iteration.
|
next then requests every WindowFunctionFrame to write the current rowIndex and UnsafeRow.
|
Caution
|
FIXME rowIndex?
|
next joins the current UnsafeRow and windowFunctionResult (i.e. takes two InternalRows and makes them appear as a single concatenated InternalRow).
next increments rowIndex.
In the end, next uses the UnsafeProjection function (that was created using createResultProjection) and projects the joined InternalRow to the result UnsafeRow.
Fetching All Rows In Partition — fetchNextPartition Internal Method
fetchNextPartition(): UnitfetchNextPartition first copies the current nextGroup UnsafeRow (that was created using grouping projection function) and clears the internal buffer.
fetchNextPartition then collects all UnsafeRows for the current nextGroup in buffer.
With the buffer filled in (with UnsafeRows per partition), fetchNextPartition prepares every WindowFunctionFrame function in frames one by one (and passing buffer).
In the end, fetchNextPartition resets rowIndex to 0 and requests buffer to generate an iterator (available as bufferIterator).
|
Note
|
fetchNextPartition is used internally when doExecute's Iterator is requested for the next UnsafeRow (when bufferIterator is uninitialized or was drained, i.e. holds no elements, but there are still rows in the upstream operator’s partition).
|
fetchNextRow Internal Method
fetchNextRow(): UnitfetchNextRow checks whether there is the next row available (using the upstream Iterator.hasNext) and sets nextRowAvailable mutable internal flag.
If there is a row available, fetchNextRow sets nextRow internal variable to the next UnsafeRow from the upstream’s RDD.
fetchNextRow also sets nextGroup internal variable as an UnsafeRow for nextRow using grouping function.
|
Note
|
|
If no row is available, fetchNextRow nullifies nextRow and nextGroup internal variables.
|
Note
|
fetchNextRow is used internally when doExecute's Iterator is created and fetchNextPartition is called.
|
createResultProjection Internal Method
createResultProjection(expressions: Seq[Expression]): UnsafeProjectioncreateResultProjection creates a UnsafeProjection function for expressions window function Catalyst expressions so that the window expressions are on the right side of child’s output.
|
Note
|
UnsafeProjection is a Scala function that produces UnsafeRow for an InternalRow. |
Internally, createResultProjection first creates a translation table with a BoundReference per expression (in the input expressions).
|
Note
|
BoundReference is a Catalyst expression that is a reference to a value in internal binary row at a specified position and of specified data type.
|
createResultProjection then creates a window function bound references for window expressions so unbound expressions are transformed to the BoundReferences.
In the end, createResultProjection creates a UnsafeProjection with:
|
Note
|
createResultProjection is used exclusively when WindowExec is executed.
|
Creating WindowExec Instance
WindowExec takes the following when created:
-
Window named expressions
-
Window partition specification expressions
-
Window order specification (as a collection of
SortOrderexpressions) -
Child physical operator
Lookup Table for WindowExpressions and Factory Functions for WindowFunctionFrame — windowFrameExpressionFactoryPairs Lazy Value
windowFrameExpressionFactoryPairs:
Seq[(mutable.Buffer[WindowExpression], InternalRow => WindowFunctionFrame)]windowFrameExpressionFactoryPairs is a lookup table with window expressions and factory functions for WindowFunctionFrame (per key-value pair in framedFunctions lookup table).
A factory function is a function that takes an InternalRow and produces a WindowFunctionFrame (described in the table below)
Internally, windowFrameExpressionFactoryPairs first builds framedFunctions lookup table with 4-element tuple keys and 2-element expression list values (described in the table below).
windowFrameExpressionFactoryPairs finds WindowExpression expressions in the input windowExpression and for every WindowExpression takes the window frame specification (of type SpecifiedWindowFrame that is used to find frame type and start and end frame positions).
| Element | Description |
|---|---|
Name of the kind of function |
|
|
|
Window frame’s start position |
|
Window frame’s end position |
|
| Element | Description |
|---|---|
Collection of window expressions |
|
Collection of window functions |
|
windowFrameExpressionFactoryPairs creates a AggregateProcessor for AGGREGATE frame keys in framedFunctions lookup table.
| Frame Name | FrameKey | WindowFunctionFrame |
|---|---|---|
Offset Frame |
|
|
Growing Frame |
|
|
Shrinking Frame |
|
|
Moving Frame |
|
|
|
|
Note
|
lazy val in Scala is computed when first accessed and once only (for the entire lifetime of the owning object instance).
|
|
Note
|
windowFrameExpressionFactoryPairs is used exclusively when WindowExec is executed.
|
createBoundOrdering Internal Method
createBoundOrdering(frame: FrameType, bound: Expression, timeZone: String): BoundOrderingcreateBoundOrdering…FIXME
|
Note
|
createBoundOrdering is used exclusively when WindowExec physical operator is requested for the window frame factories.
|