// Use ShuffledHashJoinExec's selection requirements
// 1. Disable auto broadcasting
// JoinSelection (canBuildLocalHashMap specifically) requires that
// plan.stats.sizeInBytes < autoBroadcastJoinThreshold * numShufflePartitions
// That gives that autoBroadcastJoinThreshold has to be at least 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1)
scala> println(spark.sessionState.conf.numShufflePartitions)
200
// 2. Disable preference on SortMergeJoin
spark.conf.set("spark.sql.join.preferSortMergeJoin", false)
val dataset = Seq(
(0, "playing"),
(1, "with"),
(2, "ShuffledHashJoinExec")
).toDF("id", "token")
// Self LEFT SEMI join
val q = dataset.join(dataset, Seq("id"), "leftsemi")
val sizeInBytes = q.queryExecution.optimizedPlan.stats.sizeInBytes
scala> println(sizeInBytes)
72
// 3. canBuildLeft is on for leftsemi
// the right join side is at least three times smaller than the left side
// Even though it's a self LEFT SEMI join there are two different join sides
// How is that possible?
// BINGO! ShuffledHashJoin is here!
// Enable DEBUG logging level
import org.apache.log4j.{Level, Logger}
val logger = "org.apache.spark.sql.catalyst.planning.ExtractEquiJoinKeys"
Logger.getLogger(logger).setLevel(Level.DEBUG)
// ShuffledHashJoin with BuildRight
scala> q.explain
== Physical Plan ==
ShuffledHashJoin [id#37], [id#41], LeftSemi, BuildRight
:- Exchange hashpartitioning(id#37, 200)
: +- LocalTableScan [id#37, token#38]
+- Exchange hashpartitioning(id#41, 200)
+- LocalTableScan [id#41]
scala> println(q.queryExecution.executedPlan.numberedTreeString)
00 ShuffledHashJoin [id#37], [id#41], LeftSemi, BuildRight
01 :- Exchange hashpartitioning(id#37, 200)
02 : +- LocalTableScan [id#37, token#38]
03 +- Exchange hashpartitioning(id#41, 200)
04 +- LocalTableScan [id#41]ShuffledHashJoinExec Binary Physical Operator for Shuffled Hash Join
ShuffledHashJoinExec is a binary physical operator to execute a shuffled hash join.
ShuffledHashJoinExec performs a hash join of two child relations by first shuffling the data using the join keys.
ShuffledHashJoinExec is selected to represent a Join logical operator when JoinSelection execution planning strategy is executed and spark.sql.join.preferSortMergeJoin configuration property is off.
|
Note
|
spark.sql.join.preferSortMergeJoin is an internal configuration property and is enabled by default. That means that JoinSelection execution planning strategy (and so Spark Planner) prefers sort merge join over shuffled hash join. In other words, you will hardly see shuffled hash joins in your structured queries unless you turn |
Beside the spark.sql.join.preferSortMergeJoin configuration property one of the following requirements has to hold:
-
(For a right build side, i.e.
BuildRight) canBuildRight, canBuildLocalHashMap for the right join side and finally the right join side is at least three times smaller than the left side -
(For a right build side, i.e.
BuildRight) Left join keys are not orderable, i.e. cannot be sorted -
(For a left build side, i.e.
BuildLeft) canBuildLeft, canBuildLocalHashMap for left join side and finally left join side is at least three times smaller than right
|
Tip
|
Enable |
| Key | Name (in web UI) | Description |
|---|---|---|
avg hash probe |
||
data size of build side |
||
time to build hash map |
||
number of output rows |
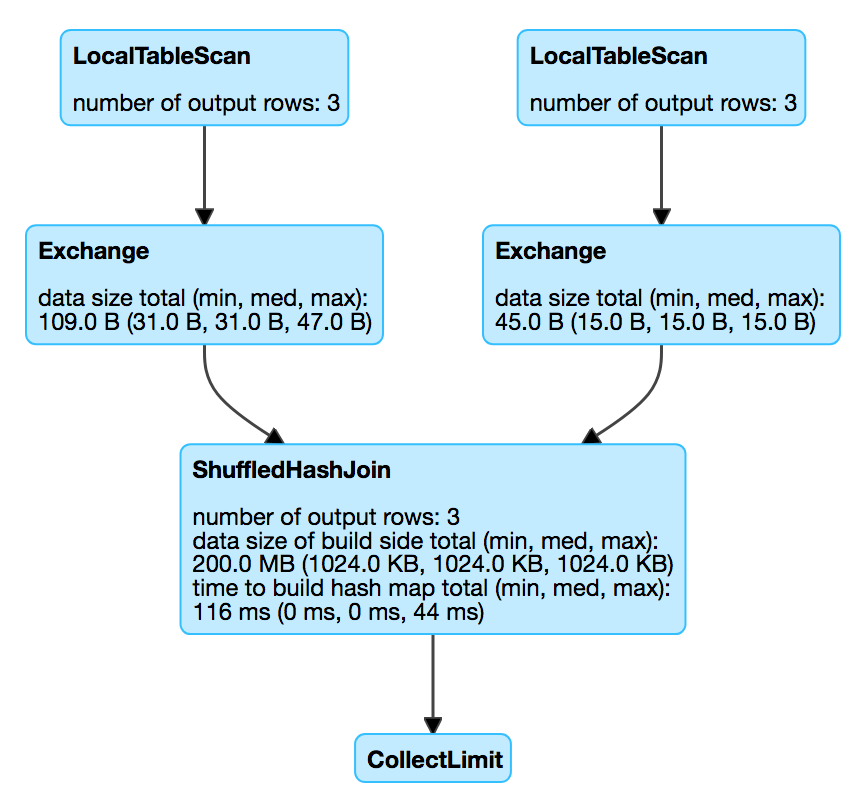
Figure 1. ShuffledHashJoinExec in web UI (Details for Query)
| Left Child | Right Child |
|---|---|
Executing Physical Operator (Generating RDD[InternalRow]) — doExecute Method
doExecute(): RDD[InternalRow]|
Note
|
doExecute is part of SparkPlan Contract to generate the runtime representation of a structured query as a distributed computation over internal binary rows on Apache Spark (i.e. RDD[InternalRow]).
|
doExecute requests streamedPlan physical operator to execute (and generate a RDD[InternalRow]).
doExecute requests streamedPlan physical operator’s RDD[InternalRow] to zip partition-wise with buildPlan physical operator’s RDD[InternalRow] (using RDD.zipPartitions method with preservesPartitioning flag disabled).
|
Note
|
|
doExecute uses RDD.zipPartitions with a function applied to zipped partitions that takes two iterators of rows from the partitions of streamedPlan and buildPlan.
For every partition (and pairs of rows from the RDD), the function buildHashedRelation on the partition of buildPlan and join the streamedPlan partition iterator, the HashedRelation, numOutputRows and avgHashProbe SQL metrics.
Building HashedRelation for Internal Rows — buildHashedRelation Internal Method
buildHashedRelation(iter: Iterator[InternalRow]): HashedRelationbuildHashedRelation creates a HashedRelation (for the input iter iterator of InternalRows, buildKeys and the current TaskMemoryManager).
|
Note
|
buildHashedRelation uses TaskContext.get() to access the current TaskContext that in turn is used to access the TaskMemoryManager.
|
buildHashedRelation records the time to create the HashedRelation as buildTime.
buildHashedRelation requests the HashedRelation for estimatedSize that is recorded as buildDataSize.
|
Note
|
buildHashedRelation is used exclusively when ShuffledHashJoinExec is requested to execute (when streamedPlan and buildPlan physical operators are executed and their RDDs zipped partition-wise using RDD.zipPartitions method).
|
Creating ShuffledHashJoinExec Instance
ShuffledHashJoinExec takes the following when created:
-
Left join key expressions
-
Right join key expressions
-
Optional join condition expression
-
Left physical operator
-
Right physical operator