QueryExecution — Structured Query Execution Pipeline
QueryExecution is the execution pipeline (workflow) of a structured query.
QueryExecution is made up of execution stages (phases).
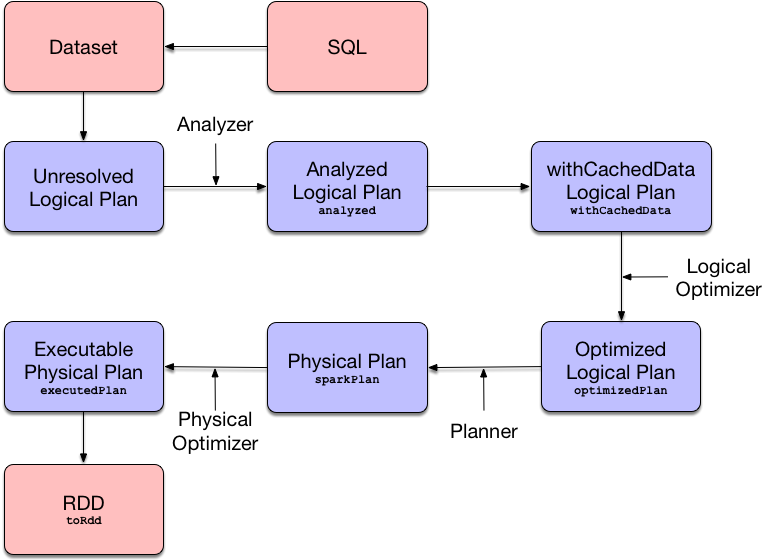
Figure 1. Query Execution — From SQL through Dataset to RDD
|
Note
|
When you execute an operator on a Dataset it triggers query execution that gives the good ol' RDD of internal binary rows, i.e. RDD[InternalRow], that is Spark’s execution plan followed by executing an RDD action and so the result of the structured query.
|
QueryExecution is part of any Dataset using queryExecution attribute.
val ds: Dataset[Long] = ...
val queryExec = ds.queryExecutionQueryExecution is the result of executing a LogicalPlan in a SparkSession (and so you could create a Dataset from a logical operator or use the QueryExecution after executing a logical operator).
val plan: LogicalPlan = ...
val qe = new QueryExecution(sparkSession, plan)| Attribute / Phase | Description | ||||||
|---|---|---|---|---|---|---|---|
|
Analyzed logical plan that has passed Analyzer's check rules.
|
||||||
|
analyzed logical plan after
|
||||||
|
Optimized logical plan that is the result of executing the logical query plan optimizer on the withCachedData logical plan. |
||||||
|
Physical plan (after SparkPlanner has planned the optimized logical plan).
|
||||||
|
Optimized physical query plan that is in the final optimized "shape" and therefore ready for execution, i.e. the physical sparkPlan with physical preparation rules applied.
|
||||||
|
Spark Core’s execution graph of a distributed computation ( The
|
You can access the lazy attributes as follows:
val dataset: Dataset[Long] = ...
dataset.queryExecution.executedPlanQueryExecution uses the Catalyst Query Optimizer and Tungsten for better structured query performance.
| Name | Description |
|---|---|
QueryExecution uses the input SparkSession to access the current SparkPlanner (through SessionState) when it is created. It then computes a SparkPlan (a PhysicalPlan exactly) using the planner. It is available as the sparkPlan attribute.
|
Note
|
A variant of Refer to IncrementalExecution — QueryExecution of Streaming Datasets in the Spark Structured Streaming gitbook. |
|
Tip
|
Use explain operator to know about the logical and physical plans of a Dataset.
|
val ds = spark.range(5)
scala> ds.queryExecution
res17: org.apache.spark.sql.execution.QueryExecution =
== Parsed Logical Plan ==
Range 0, 5, 1, 8, [id#39L]
== Analyzed Logical Plan ==
id: bigint
Range 0, 5, 1, 8, [id#39L]
== Optimized Logical Plan ==
Range 0, 5, 1, 8, [id#39L]
== Physical Plan ==
WholeStageCodegen
: +- Range 0, 1, 8, 5, [id#39L]|
Note
|
QueryExecution belongs to org.apache.spark.sql.execution package.
|
|
Note
|
QueryExecution is a transient feature of a Dataset, i.e. it is not preserved across serializations.
|
Text Representation With Statistics — stringWithStats Method
stringWithStats: StringstringWithStats…FIXME
|
Note
|
stringWithStats is used exclusively when ExplainCommand logical command is executed (with cost flag enabled).
|
Physical Query Optimizations (Physical Plan Preparation Rules) — preparations Method
preparations: Seq[Rule[SparkPlan]]preparations is the set of the physical query optimization rules that transform a physical query plan to be more efficient and optimized for execution (i.e. Rule[SparkPlan]).
The preparations physical query optimizations are applied sequentially (one by one) to a physical plan in the following order:
|
Note
|
|
Applying preparations Physical Query Optimization Rules to Physical Plan — prepareForExecution Method
prepareForExecution(plan: SparkPlan): SparkPlanprepareForExecution takes physical preparation rules and applies them one by one to the input physical plan.
|
Note
|
prepareForExecution is used exclusively when QueryExecution is requested to prepare the physical plan for execution.
|
assertSupported Method
assertSupported(): UnitassertSupported requests UnsupportedOperationChecker to checkForBatch when…FIXME
|
Note
|
assertSupported is used exclusively when QueryExecution is requested for withCachedData logical plan.
|
Creating Analyzed Logical Plan and Checking Correctness — assertAnalyzed Method
assertAnalyzed(): UnitassertAnalyzed triggers initialization of analyzed (which is almost like executing it).
|
Note
|
assertAnalyzed executes analyzed by accessing it and throwing the result away. Since analyzed is a lazy value in Scala, it will then get initialized for the first time and stays so forever.
|
assertAnalyzed then requests Analyzer to validate analysis of the logical plan (i.e. analyzed).
|
Note
|
In Scala the access path looks as follows. |
In case of any AnalysisException, assertAnalyzed creates a new AnalysisException to make sure that it holds analyzed and reports it.
|
Note
|
|
Building Text Representation with Cost Stats — toStringWithStats Method
toStringWithStats: StringtoStringWithStats is a mere alias for completeString with appendStats flag enabled.
|
Note
|
toStringWithStats is a custom toString with cost statistics.
|
// test dataset
val dataset = spark.range(20).limit(2)
// toStringWithStats in action - note Optimized Logical Plan section with Statistics
scala> dataset.queryExecution.toStringWithStats
res6: String =
== Parsed Logical Plan ==
GlobalLimit 2
+- LocalLimit 2
+- Range (0, 20, step=1, splits=Some(8))
== Analyzed Logical Plan ==
id: bigint
GlobalLimit 2
+- LocalLimit 2
+- Range (0, 20, step=1, splits=Some(8))
== Optimized Logical Plan ==
GlobalLimit 2, Statistics(sizeInBytes=32.0 B, rowCount=2, isBroadcastable=false)
+- LocalLimit 2, Statistics(sizeInBytes=160.0 B, isBroadcastable=false)
+- Range (0, 20, step=1, splits=Some(8)), Statistics(sizeInBytes=160.0 B, isBroadcastable=false)
== Physical Plan ==
CollectLimit 2
+- *Range (0, 20, step=1, splits=Some(8))|
Note
|
toStringWithStats is used exclusively when ExplainCommand is executed (only when cost attribute is enabled).
|
Transforming SparkPlan Execution Result to Hive-Compatible Output Format — hiveResultString Method
hiveResultString(): Seq[String]hiveResultString returns the result as a Hive-compatible output format.
scala> spark.range(5).queryExecution.hiveResultString
res0: Seq[String] = ArrayBuffer(0, 1, 2, 3, 4)
scala> spark.read.csv("people.csv").queryExecution.hiveResultString
res4: Seq[String] = ArrayBuffer(id name age, 0 Jacek 42)Internally, hiveResultString transformation the SparkPlan.
| SparkPlan | Description |
|---|---|
Executes |
|
Executes |
|
Any other SparkPlan |
Executes |
|
Note
|
hiveResultString is used exclusively when SparkSQLDriver (of ThriftServer) runs a command.
|
Extended Text Representation with Logical and Physical Plans — toString Method
toString: String|
Note
|
toString is part of Java’s Object Contract to…FIXME.
|
toString is a mere alias for completeString with appendStats flag disabled.
|
Note
|
toString is on the "other" side of toStringWithStats which has appendStats flag enabled.
|
Simple (Basic) Text Representation — simpleString Method
simpleString: StringsimpleString requests the optimized SparkPlan for the text representation (of all nodes in the query tree) with verbose flag turned off.
In the end, simpleString adds == Physical Plan == header to the text representation and redacts sensitive information.
import org.apache.spark.sql.{functions => f}
val q = spark.range(10).withColumn("rand", f.rand())
val output = q.queryExecution.simpleString
scala> println(output)
== Physical Plan ==
*(1) Project [id#5L, rand(6017561978775952851) AS rand#7]
+- *(1) Range (0, 10, step=1, splits=8)|
Note
|
|
Redacting Sensitive Information — withRedaction Internal Method
withRedaction(message: String): StringwithRedaction takes the value of spark.sql.redaction.string.regex configuration property (as the regular expression to point at sensitive information) and requests Spark Core’s Utils to redact sensitive information in the input message.
|
Note
|
Internally, Spark Core’s Utils.redact uses Java’s Regex.replaceAllIn to replace all matches of a pattern with a string.
|
|
Note
|
withRedaction is used when QueryExecution is requested for the simple, extended and with statistics text representations.
|