pivot(pivotColumn: String): RelationalGroupedDataset
pivot(pivotColumn: String, values: Seq[Any]): RelationalGroupedDataset
pivot(pivotColumn: Column): RelationalGroupedDataset (1)
pivot(pivotColumn: Column, values: Seq[Any]): RelationalGroupedDataset (1)RelationalGroupedDataset — Untyped Row-based Grouping
RelationalGroupedDataset is an interface to calculate aggregates over groups of rows in a DataFrame.
|
Note
|
KeyValueGroupedDataset is used for typed aggregates over groups of custom Scala objects (not Rows). |
RelationalGroupedDataset is a result of executing the following grouping operators:
| Operator | Description |
|---|---|
|
|
|
|
|
|
|
|
|
|
Pivots on a column (with new columns per distinct value) |
|
|
|
Note
|
spark.sql.retainGroupColumns configuration property controls whether to retain columns used for aggregation or not (in
|
Computing Aggregates Using Aggregate Column Expressions or Function Names — agg Operator
agg(expr: Column, exprs: Column*): DataFrame
agg(exprs: Map[String, String]): DataFrame
agg(aggExpr: (String, String), aggExprs: (String, String)*): DataFrameagg creates a DataFrame with the rows being the result of executing grouping expressions (specified using columns or names) over row groups.
val countsAndSums = spark.
range(10). // <-- 10-element Dataset
withColumn("group", 'id % 2). // <-- define grouping column
groupBy("group"). // <-- group by groups
agg(count("id") as "count", sum("id") as "sum")
scala> countsAndSums.show
+-----+-----+---+
|group|count|sum|
+-----+-----+---+
| 0| 5| 20|
| 1| 5| 25|
+-----+-----+---+Internally, agg creates a DataFrame with Aggregate or Pivot logical operators.
// groupBy above
scala> println(countsAndSums.queryExecution.logical.numberedTreeString)
00 'Aggregate [group#179L], [group#179L, count('id) AS count#188, sum('id) AS sum#190]
01 +- Project [id#176L, (id#176L % cast(2 as bigint)) AS group#179L]
02 +- Range (0, 10, step=1, splits=Some(8))
// rollup operator
val rollupQ = spark.range(2).rollup('id).agg(count('id))
scala> println(rollupQ.queryExecution.logical.numberedTreeString)
00 'Aggregate [rollup('id)], [unresolvedalias('id, None), count('id) AS count(id)#267]
01 +- Range (0, 2, step=1, splits=Some(8))
// cube operator
val cubeQ = spark.range(2).cube('id).agg(count('id))
scala> println(cubeQ.queryExecution.logical.numberedTreeString)
00 'Aggregate [cube('id)], [unresolvedalias('id, None), count('id) AS count(id)#280]
01 +- Range (0, 2, step=1, splits=Some(8))
// pivot operator
val pivotQ = spark.
range(10).
withColumn("group", 'id % 2).
groupBy("group").
pivot("group").
agg(count("id"))
scala> println(pivotQ.queryExecution.logical.numberedTreeString)
00 'Pivot [group#296L], group#296: bigint, [0, 1], [count('id)]
01 +- Project [id#293L, (id#293L % cast(2 as bigint)) AS group#296L]
02 +- Range (0, 10, step=1, splits=Some(8)) Creating DataFrame from Aggregate Expressions — toDF Internal Method
toDF(aggExprs: Seq[Expression]): DataFrame|
Caution
|
FIXME |
Internally, toDF branches off per group type.
|
Caution
|
FIXME |
For PivotType, toDF creates a DataFrame with Pivot unary logical operator.
aggregateNumericColumns Internal Method
aggregateNumericColumns(colNames: String*)(f: Expression => AggregateFunction): DataFrameaggregateNumericColumns…FIXME
Creating RelationalGroupedDataset Instance
RelationalGroupedDataset takes the following when created:
-
Grouping expressions
-
Group type (to indicate the "source" operator)
-
GroupByTypefor groupBy -
CubeType -
RollupType -
PivotType
-
pivot Operator
pivot(pivotColumn: String): RelationalGroupedDataset (1)
pivot(pivotColumn: String, values: Seq[Any]): RelationalGroupedDataset (2)
pivot(pivotColumn: Column): RelationalGroupedDataset (3)
pivot(pivotColumn: Column, values: Seq[Any]): RelationalGroupedDataset (3)-
Selects distinct and sorted values on
pivotColumnand calls the otherpivot(that results in 3 extra "scanning" jobs) -
Preferred as more efficient because the unique values are aleady provided
-
New in 2.4.0
pivot pivots on a pivotColumn column, i.e. adds new columns per distinct values in pivotColumn.
|
Note
|
pivot is only supported after groupBy operation.
|
|
Note
|
Only one pivot operation is supported on a RelationalGroupedDataset.
|
val visits = Seq(
(0, "Warsaw", 2015),
(1, "Warsaw", 2016),
(2, "Boston", 2017)
).toDF("id", "city", "year")
val q = visits
.groupBy("city") // <-- rows in pivot table
.pivot("year") // <-- columns (unique values queried)
.count() // <-- values in cells
scala> q.show
+------+----+----+----+
| city|2015|2016|2017|
+------+----+----+----+
|Warsaw| 1| 1|null|
|Boston|null|null| 1|
+------+----+----+----+
scala> q.explain
== Physical Plan ==
HashAggregate(keys=[city#8], functions=[pivotfirst(year#9, count(1) AS `count`#222L, 2015, 2016, 2017, 0, 0)])
+- Exchange hashpartitioning(city#8, 200)
+- HashAggregate(keys=[city#8], functions=[partial_pivotfirst(year#9, count(1) AS `count`#222L, 2015, 2016, 2017, 0, 0)])
+- *HashAggregate(keys=[city#8, year#9], functions=[count(1)])
+- Exchange hashpartitioning(city#8, year#9, 200)
+- *HashAggregate(keys=[city#8, year#9], functions=[partial_count(1)])
+- LocalTableScan [city#8, year#9]
scala> visits
.groupBy('city)
.pivot("year", Seq("2015")) // <-- one column in pivot table
.count
.show
+------+----+
| city|2015|
+------+----+
|Warsaw| 1|
|Boston|null|
+------+----+|
Important
|
Use pivot with a list of distinct values to pivot on so Spark does not have to compute the list itself (and run three extra "scanning" jobs).
|

Figure 1. pivot in web UI (Distinct Values Defined Explicitly)
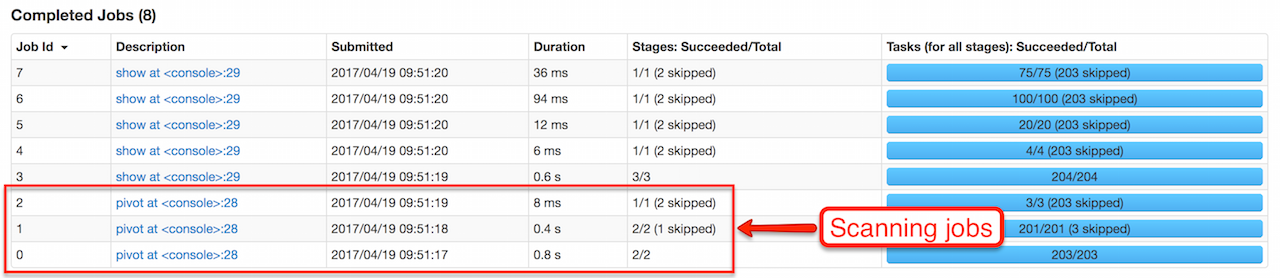
Figure 2. pivot in web UI — Three Extra Scanning Jobs Due to Unspecified Distinct Values
|
Note
|
spark.sql.pivotMaxValues (default: 10000) controls the maximum number of (distinct) values that will be collected without error (when doing pivot without specifying the values for the pivot column).
|
Internally, pivot creates a RelationalGroupedDataset with PivotType group type and pivotColumn resolved using the DataFrame’s columns with values as Literal expressions.
|
Note
|
|
strToExpr Internal Method
strToExpr(expr: String): (Expression => Expression)strToExpr…FIXME
|
Note
|
strToExpr is used exclusively when RelationalGroupedDataset is requested to agg with aggregation functions specified by name
|
alias Method
alias(expr: Expression): NamedExpressionalias…FIXME
|
Note
|
alias is used exclusively when RelationalGroupedDataset is requested to create a DataFrame from aggregate expressions.
|