Analyzer: Unresolved Logical Plan ==> Analyzed Logical PlanAnalyzer — Logical Query Plan Analyzer
Analyzer (aka Spark Analyzer or Query Analyzer) is the logical query plan analyzer that semantically validates and transforms an unresolved logical plan to an analyzed logical plan.
Analyzer is a concrete RuleExecutor of LogicalPlan (i.e. RuleExecutor[LogicalPlan]) with the logical evaluation rules.
Analyzer uses SessionCatalog while resolving relational entities, e.g. databases, tables, columns.
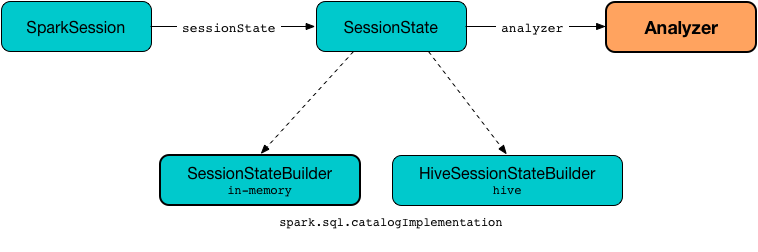
Figure 1. Creating Analyzer
Analyzer is available as the analyzer property of a session-specific SessionState.
scala> :type spark
org.apache.spark.sql.SparkSession
scala> :type spark.sessionState.analyzer
org.apache.spark.sql.catalyst.analysis.AnalyzerYou can access the analyzed logical plan of a structured query (as a Dataset) using Dataset.explain basic action (with extended flag enabled) or SQL’s EXPLAIN EXTENDED SQL command.
// sample structured query
val inventory = spark
.range(5)
.withColumn("new_column", 'id + 5 as "plus5")
// Using explain operator (with extended flag enabled)
scala> inventory.explain(extended = true)
== Parsed Logical Plan ==
'Project [id#0L, ('id + 5) AS plus5#2 AS new_column#3]
+- AnalysisBarrier
+- Range (0, 5, step=1, splits=Some(8))
== Analyzed Logical Plan ==
id: bigint, new_column: bigint
Project [id#0L, (id#0L + cast(5 as bigint)) AS new_column#3L]
+- Range (0, 5, step=1, splits=Some(8))
== Optimized Logical Plan ==
Project [id#0L, (id#0L + 5) AS new_column#3L]
+- Range (0, 5, step=1, splits=Some(8))
== Physical Plan ==
*(1) Project [id#0L, (id#0L + 5) AS new_column#3L]
+- *(1) Range (0, 5, step=1, splits=8)Alternatively, you can access the analyzed logical plan using QueryExecution and its analyzed property (that together with numberedTreeString method is a very good "debugging" tool).
val analyzedPlan = inventory.queryExecution.analyzed
scala> println(analyzedPlan.numberedTreeString)
00 Project [id#0L, (id#0L + cast(5 as bigint)) AS new_column#3L]
01 +- Range (0, 5, step=1, splits=Some(8))Analyzer defines extendedResolutionRules extension point for additional logical evaluation rules that a custom Analyzer can use to extend the Resolution rule batch. The rules are added at the end of the Resolution batch.
|
Note
|
SessionState uses its own Analyzer with custom extendedResolutionRules, postHocResolutionRules, and extendedCheckRules extension methods.
|
| Name | Description |
|---|---|
Additional rules for Resolution batch. Empty by default |
|
Set when |
|
The only rules in Post-Hoc Resolution batch if defined (that are executed in one pass, i.e. |
Analyzer is used by QueryExecution to resolve the managed LogicalPlan (and, as a sort of follow-up, assert that a structured query has already been properly analyzed, i.e. no failed or unresolved or somehow broken logical plan operators and expressions exist).
|
Tip
|
Enable
Add the following line to Refer to Logging. The reason for such weird-looking logger names is that |
Executing Logical Evaluation Rules — execute Method
Analyzer is a RuleExecutor that defines the logical rules (i.e. resolving, removing, and in general modifying it), e.g.
-
Resolves unresolved relations and functions (including UnresolvedGenerators) using provided SessionCatalog
-
…
| Batch Name | Strategy | Rules | Description |
|---|---|---|---|
Resolves UnresolvedHint logical operators with |
|||
Resolves UnresolvedHint logical operators with |
|||
RemoveAllHints |
Removes all UnresolvedHint logical operators |
||
|
Checks whether a function identifier (referenced by an UnresolvedFunction) exists in the function registry. Throws a |
||
CTESubstitution |
Resolves |
||
Substitutes an UnresolvedWindowExpression with a WindowExpression for WithWindowDefinition logical operators. |
|||
EliminateUnions |
Eliminates |
||
SubstituteUnresolvedOrdinals |
Replaces ordinals in Sort and Aggregate logical operators with UnresolvedOrdinal expressions |
||
ResolveTableValuedFunctions |
Replaces |
||
Resolves: |
|||
Resolves CreateNamedStruct expressions (with |
|||
ResolveDeserializer |
|||
ResolveNewInstance |
|||
ResolveUpCast |
|||
Resolves grouping expressions up in a logical plan tree:
Expects that all children of a logical operator are already resolved (and given it belongs to a fixed-point batch it will likely happen at some iteration). Fails analysis when
|
|||
Resolves Pivot logical operator to |
|||
ResolveMissingReferences |
|||
ResolveGenerate |
|||
Resolves functions using SessionCatalog: If [name] is expected to be a generator. However, its class is [className], which is not a generator. |
|||
Replaces
|
|||
Resolves subquery expressions (i.e. ScalarSubquery, Exists and In) |
|||
Resolves WindowExpression expressions |
|||
ResolveNaturalAndUsingJoin |
|||
GlobalAggregates |
Resolves (aka replaces) |
||
ResolveAggregateFunctions |
|
||
Resolves TimeWindow expressions to |
|||
Resolves UnresolvedInlineTable operators to LocalRelations |
|||
|
|||
|
|||
Nondeterministic |
|
PullOutNondeterministic |
|
UDF |
|
||
FixNullability |
|
FixNullability |
|
ResolveTimeZone |
|
ResolveTimeZone |
Replaces |
|
Tip
|
Consult the sources of Analyzer for the up-to-date list of the evaluation rules.
|
Creating Analyzer Instance
Analyzer takes the following when created:
-
Maximum number of iterations (of the FixedPoint rule batches, i.e. Hints, Substitution, Resolution and Cleanup)
Analyzer initializes the internal registries and counters.
|
Note
|
Analyzer can also be created without specifying the maxIterations argument which is then configured using optimizerMaxIterations configuration setting.
|
resolver Method
resolver: Resolverresolver requests CatalystConf for Resolver.
|
Note
|
Resolver is a mere function of two String parameters that returns true if both refer to the same entity (i.e. for case insensitive equality).
|
resolveExpression Method
resolveExpression(
expr: Expression,
plan: LogicalPlan,
throws: Boolean = false): ExpressionresolveExpression…FIXME
|
Note
|
resolveExpression is a protected[sql] method.
|
|
Note
|
resolveExpression is used when…FIXME
|
commonNaturalJoinProcessing Internal Method
commonNaturalJoinProcessing(
left: LogicalPlan,
right: LogicalPlan,
joinType: JoinType,
joinNames: Seq[String],
condition: Option[Expression]): ProjectcommonNaturalJoinProcessing…FIXME
|
Note
|
commonNaturalJoinProcessing is used when…FIXME
|
executeAndCheck Method
executeAndCheck(plan: LogicalPlan): LogicalPlanexecuteAndCheck…FIXME
|
Note
|
executeAndCheck is used exclusively when QueryExecution is requested for the analyzed logical plan.
|