import org.apache.spark.streaming._
val sc = SparkContext.getOrCreate
val ssc = new StreamingContext(sc, Seconds(5))StreamingContext — The Entry Point to Spark Streaming
StreamingContext is the entry point for all Spark Streaming functionality. Whatever you do in Spark Streaming has to start from creating an instance of StreamingContext.
|
Note
|
StreamingContext belongs to org.apache.spark.streaming package.
|
With an instance of StreamingContext in your hands, you can create ReceiverInputDStreams or set the checkpoint directory.
Once streaming pipelines are developed, you start StreamingContext to set the stream transformations in motion. You stop the instance when you are done.
Creating Instance
You can create a new instance of StreamingContext using the following constructors. You can group them by whether a StreamingContext constructor creates it from scratch or it is recreated from a checkpoint directory (follow the links for their extensive coverage).
-
Creating StreamingContext from scratch:
-
StreamingContext(conf: SparkConf, batchDuration: Duration) -
StreamingContext(master: String, appName: String, batchDuration: Duration, sparkHome: String, jars: Seq[String], environment: Map[String,String]) -
StreamingContext(sparkContext: SparkContext, batchDuration: Duration)
-
-
Recreating StreamingContext from a checkpoint file (where
pathis the checkpoint directory):-
StreamingContext(path: String) -
StreamingContext(path: String, hadoopConf: Configuration) -
StreamingContext(path: String, sparkContext: SparkContext)
-
|
Note
|
StreamingContext(path: String) uses SparkHadoopUtil.get.conf.
|
|
Note
|
When a StreamingContext is created and spark.streaming.checkpoint.directory setting is set, the value gets passed on to checkpoint method. |
Creating StreamingContext from Scratch
When you create a new instance of StreamingContext, it first checks whether a SparkContext or the checkpoint directory are given (but not both!)
|
Tip
|
WARN StreamingContext: spark.master should be set as local[n], n > 1 in local mode if you have receivers to get data, otherwise Spark jobs will not get resources to process the received data. |
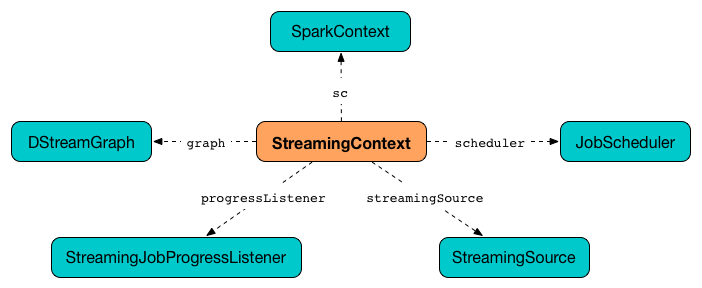
Figure 1. StreamingContext and Dependencies
A DStreamGraph is created.
A JobScheduler is created.
A StreamingJobProgressListener is created.
Streaming tab in web UI is created (when spark.ui.enabled is enabled).
A StreamingSource is instantiated.
At this point, StreamingContext enters INITIALIZED state.
Creating ReceiverInputDStreams
StreamingContext offers the following methods to create ReceiverInputDStreams:
-
actorStream[T](props: Props, name: String, storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2, supervisorStrategy: SupervisorStrategy = ActorSupervisorStrategy.defaultStrategy): ReceiverInputDStream[T] -
socketTextStream(hostname: String, port: Int, storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2): ReceiverInputDStream[String] -
socketStream[T](hostname: String, port: Int, converter: (InputStream) ⇒ Iterator[T], storageLevel: StorageLevel): ReceiverInputDStream[T] -
rawSocketStream[T](hostname: String, port: Int, storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2): ReceiverInputDStream[T]
StreamingContext offers the following methods to create InputDStreams:
-
queueStream[T](queue: Queue[RDD[T]], oneAtATime: Boolean = true): InputDStream[T] -
queueStream[T](queue: Queue[RDD[T]], oneAtATime: Boolean, defaultRDD: RDD[T]): InputDStream[T]
You can also use two additional methods in StreamingContext to build (or better called compose) a custom DStream:
-
union[T](streams: Seq[DStream[T]]): DStream[T]
receiverStream method
receiverStream[T: ClassTag](receiver: Receiver[T]): ReceiverInputDStream[T]You can register a custom input dstream using receiverStream method. It accepts a Receiver.
|
Note
|
You can find an example of a custom Receiver in Custom Receiver.
|
transform method
transform[T](dstreams: Seq[DStream[_]], transformFunc: (Seq[RDD[_]], Time) => RDD[T]): DStream[T] remember method
remember(duration: Duration): Unitremember method sets the remember interval (for the graph of output dstreams). It simply calls DStreamGraph.remember method and exits.
|
Caution
|
FIXME figure |
Checkpoint Interval
The checkpoint interval is an internal property of StreamingContext and corresponds to batch interval or checkpoint interval of the checkpoint (when checkpoint was present).
|
Note
|
The checkpoint interval property is also called graph checkpointing interval. |
checkpoint interval is mandatory when checkpoint directory is defined (i.e. not null).
Checkpoint Directory
A checkpoint directory is a HDFS-compatible directory where checkpoints are written to.
|
Note
|
"A HDFS-compatible directory" means that it is Hadoop’s Path class to handle all file system-related operations. |
Its initial value depends on whether the StreamingContext was (re)created from a checkpoint or not, and is the checkpoint directory if so. Otherwise, it is not set (i.e. null).
You can set the checkpoint directory when a StreamingContext is created or later using checkpoint method.
Internally, a checkpoint directory is tracked as checkpointDir.
|
Tip
|
Refer to Checkpointing for more detailed coverage. |
Initial Checkpoint
Initial checkpoint is the checkpoint (file) this StreamingContext has been recreated from.
The initial checkpoint is specified when a StreamingContext is created.
val ssc = new StreamingContext("_checkpoint") Marking StreamingContext As Recreated from Checkpoint — isCheckpointPresent method
isCheckpointPresent internal method behaves like a flag that remembers whether the StreamingContext instance was created from a checkpoint or not so the other internal parts of a streaming application can make decisions how to initialize themselves (or just be initialized).
isCheckpointPresent checks the existence of the initial checkpoint that gave birth to the StreamingContext.
Setting Checkpoint Directory — checkpoint method
checkpoint(directory: String): UnitYou use checkpoint method to set directory as the current checkpoint directory.
|
Note
|
Spark creates the directory unless it exists already. |
checkpoint uses SparkContext.hadoopConfiguration to get the file system and create directory on. The full path of the directory is passed on to SparkContext.setCheckpointDir method.
|
Note
|
Calling checkpoint with null as directory clears the checkpoint directory that effectively disables checkpointing.
|
|
Note
|
When StreamingContext is created and spark.streaming.checkpoint.directory setting is set, the value gets passed on to checkpoint method.
|
Starting StreamingContext — start method
start(): Unitstart() starts stream processing. It acts differently per state of StreamingContext and only INITIALIZED state makes for a proper startup.
|
Note
|
Consult States section in this document to learn about the states of StreamingContext. |
Starting in INITIALIZED state
Right after StreamingContext has been instantiated, it enters INITIALIZED state in which start first checks whether another StreamingContext instance has already been started in the JVM. It throws IllegalStateException exception if it was and exits.
java.lang.IllegalStateException: Only one StreamingContext may be started in this JVM. Currently running StreamingContext was started at [startSite]
If no other StreamingContext exists, it performs setup validation and starts JobScheduler (in a separate dedicated daemon thread called streaming-start).

Figure 2. When started, StreamingContext starts JobScheduler
It enters ACTIVE state.
It then register the shutdown hook stopOnShutdown and streaming metrics source. If web UI is enabled, it attaches the Streaming tab.
Given all the above has have finished properly, it is assumed that the StreamingContext started fine and so you should see the following INFO message in the logs:
INFO StreamingContext: StreamingContext startedStarting in ACTIVE state
When in ACTIVE state, i.e. after it has been started, executing start merely leads to the following WARN message in the logs:
WARN StreamingContext: StreamingContext has already been startedStarting in STOPPED state
Attempting to start StreamingContext in STOPPED state, i.e. after it has been stopped, leads to the IllegalStateException exception:
java.lang.IllegalStateException: StreamingContext has already been stopped Stopping StreamingContext — stop methods
You stop StreamingContext using one of the three variants of stop method:
-
stop(stopSparkContext: Boolean = true) -
stop(stopSparkContext: Boolean, stopGracefully: Boolean)
|
Note
|
The first stop method uses spark.streaming.stopSparkContextByDefault configuration setting that controls stopSparkContext input parameter.
|
stop methods stop the execution of the streams immediately (stopGracefully is false) or wait for the processing of all received data to be completed (stopGracefully is true).
stop reacts appropriately per the state of StreamingContext, but the end state is always STOPPED state with shutdown hook removed.
If a user requested to stop the underlying SparkContext (when stopSparkContext flag is enabled, i.e. true), it is now attempted to be stopped.
Stopping in ACTIVE state
It is only in ACTIVE state when stop does more than printing out WARN messages to the logs.
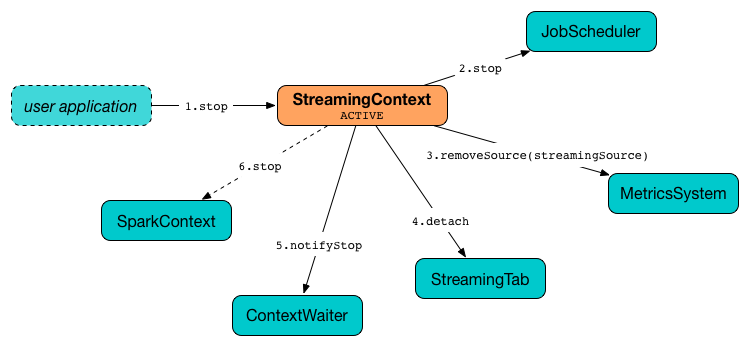
Figure 3. StreamingContext Stop Procedure
It does the following (in order):
-
StreamingSource is removed from MetricsSystem (using
MetricsSystem.removeSource) -
Streaming tab is detached (using
StreamingTab.detach). -
ContextWaiterisnotifyStop() -
shutdownHookRefis cleared.
At that point, you should see the following INFO message in the logs:
INFO StreamingContext: StreamingContext stopped successfullyStreamingContext enters STOPPED state.
Stopping in INITIALIZED state
When in INITIALIZED state, you should see the following WARN message in the logs:
WARN StreamingContext: StreamingContext has not been started yetStreamingContext enters STOPPED state.
stopOnShutdown Shutdown Hook
stopOnShutdown is a JVM shutdown hook to clean up after StreamingContext when the JVM shuts down, e.g. all non-daemon thread exited, System.exit was called or ^C was typed.
|
Note
|
It is registered to ShutdownHookManager when StreamingContext starts. |
|
Note
|
ShutdownHookManager uses org.apache.hadoop.util.ShutdownHookManager for its work.
|
When executed, it first reads spark.streaming.stopGracefullyOnShutdown setting that controls whether to stop StreamingContext gracefully or not. You should see the following INFO message in the logs:
INFO Invoking stop(stopGracefully=[stopGracefully]) from shutdown hookWith the setting it stops StreamingContext without stopping the accompanying SparkContext (i.e. stopSparkContext parameter is disabled).
Setup Validation — validate method
validate(): Unitvalidate() method validates configuration of StreamingContext.
|
Note
|
The method is executed when StreamingContext is started.
|
It first asserts that DStreamGraph has been assigned (i.e. graph field is not null) and triggers validation of DStreamGraph.
|
Caution
|
It appears that graph could never be null, though.
|
If checkpointing is enabled, it ensures that checkpoint interval is set and checks whether the current streaming runtime environment can be safely serialized by serializing a checkpoint for fictitious batch time 0 (not zero time).
If dynamic allocation is enabled, it prints the following WARN message to the logs:
WARN StreamingContext: Dynamic Allocation is enabled for this application. Enabling Dynamic allocation for Spark Streaming applications can cause data loss if Write Ahead Log is not enabled for non-replayable sources like Flume. See the programming guide for details on how to enable the Write Ahead Log
States
StreamingContext can be in three states:
-
INITIALIZED, i.e. after it was instantiated. -
ACTIVE, i.e. after it was started. -
STOPPED, i.e. after it has been stopped