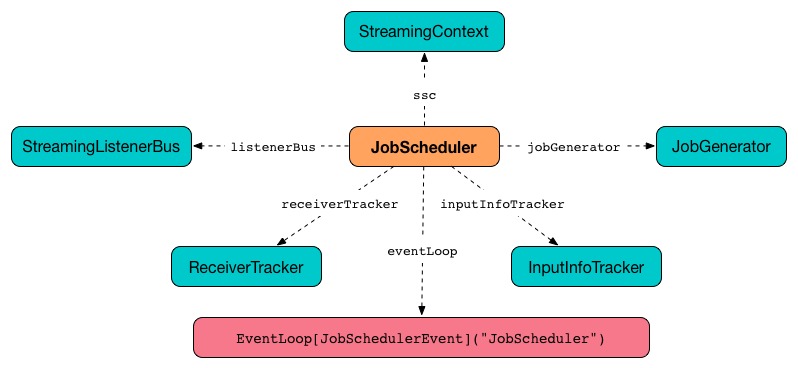
JobScheduler
Streaming scheduler (JobScheduler) schedules streaming jobs to be run as Spark jobs. It is created as part of creating a StreamingContext and starts with it.
Figure 1. JobScheduler and Dependencies
It tracks jobs submitted for execution (as JobSets via submitJobSet method) in jobSets internal map.
|
Note
|
JobSets are submitted by JobGenerator. |
It uses a streaming scheduler queue for streaming jobs to be executed.
|
Tip
|
Enable Add the following line to Refer to Logging. |
Starting JobScheduler (start method)
start(): UnitWhen JobScheduler starts (i.e. when start is called), you should see the following DEBUG message in the logs:
DEBUG JobScheduler: Starting JobSchedulerIt then goes over all the dependent services and starts them one by one as depicted in the figure.
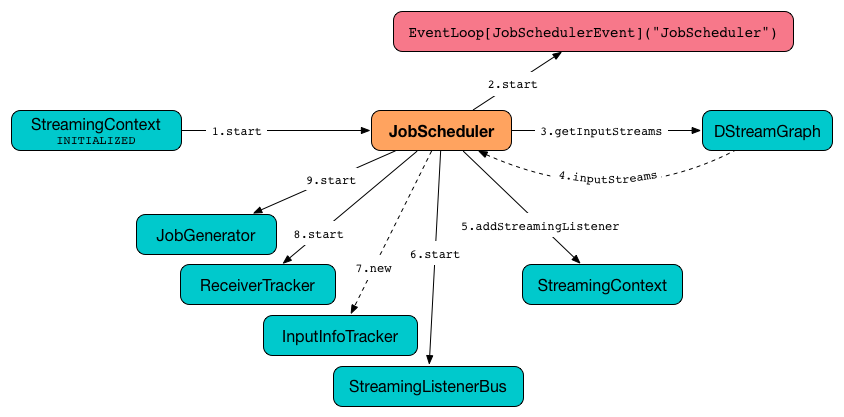
Figure 2. JobScheduler Start procedure
It first starts JobSchedulerEvent Handler.
It asks DStreamGraph for input dstreams and registers their RateControllers (if defined) as streaming listeners. It starts StreamingListenerBus afterwards.
It creates ReceiverTracker and InputInfoTracker. It then starts the ReceiverTracker.
It starts JobGenerator.
Just before start finishes, you should see the following INFO message in the logs:
INFO JobScheduler: Started JobSchedulerStopping JobScheduler (stop method)
stop(processAllReceivedData: Boolean): Unitstop stops JobScheduler.
|
Note
|
It is called when StreamingContext is being stopped. |
You should see the following DEBUG message in the logs:
DEBUG JobScheduler: Stopping JobScheduler|
Note
|
ReceiverTracker is only assigned (and started) while JobScheduler is starting. |
You should see the following DEBUG message in the logs:
DEBUG JobScheduler: Stopping job executorjobExecutor Thread Pool is shut down (using jobExecutor.shutdown()).
If the stop should wait for all received data to be processed (the input parameter processAllReceivedData is true), stop awaits termination of jobExecutor Thread Pool for 1 hour (it is assumed that it is enough and is not configurable). Otherwise, it waits for 2 seconds.
jobExecutor Thread Pool is forcefully shut down (using jobExecutor.shutdownNow()) unless it has terminated already.
You should see the following DEBUG message in the logs:
DEBUG JobScheduler: Stopped job executorStreamingListenerBus and eventLoop - JobSchedulerEvent Handler are stopped.
You should see the following INFO message in the logs:
INFO JobScheduler: Stopped JobScheduler Submitting Collection of Jobs for Execution — submitJobSet method
When submitJobSet(jobSet: JobSet) is called, it reacts appropriately per jobSet JobSet given.
|
Note
|
The method is called by JobGenerator only (as part of JobGenerator.generateJobs and JobGenerator.restart). |
When no streaming jobs are inside the jobSet, you should see the following INFO in the logs:
INFO JobScheduler: No jobs added for time [jobSet.time]Otherwise, when there is at least one streaming job inside the jobSet, StreamingListenerBatchSubmitted (with data statistics of every registered input stream for which the streaming jobs were generated) is posted to StreamingListenerBus.
The JobSet is added to the internal jobSets registry.
It then goes over every streaming job in the jobSet and executes a JobHandler (on jobExecutor Thread Pool).
At the end, you should see the following INFO message in the logs:
INFO JobScheduler: Added jobs for time [jobSet.time] msJobHandler
JobHandler is a thread of execution for a streaming job (that simply calls Job.run).
|
Note
|
It is called when a new JobSet is submitted (see submitJobSet in this document). |
When started, it prepares the environment (so the streaming job can be nicely displayed in the web UI under /streaming/batch/?id=[milliseconds]) and posts JobStarted event to JobSchedulerEvent event loop.
It runs the streaming job that executes the job function as defined while generating a streaming job for an output stream.
|
Note
|
This is when Spark is requested to run a Spark job. |
You may see similar-looking INFO messages in the logs (it depends on the operators you use):
INFO SparkContext: Starting job: print at <console>:39
INFO DAGScheduler: Got job 0 (print at <console>:39) with 1 output partitions
...
INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (KafkaRDD[2] at createDirectStream at <console>:36)
...
INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 987 bytes result sent to driver
...
INFO DAGScheduler: Job 0 finished: print at <console>:39, took 0.178689 sIt posts JobCompleted event to JobSchedulerEvent event loop.
jobExecutor Thread Pool
While JobScheduler is instantiated, the daemon thread pool streaming-job-executor-ID with spark.streaming.concurrentJobs threads is created.
It is used to execute JobHandler for jobs in JobSet (see submitJobSet in this document).
It shuts down when StreamingContext stops.
eventLoop - JobSchedulerEvent Handler
JobScheduler uses EventLoop for JobSchedulerEvent events. It accepts JobStarted and JobCompleted events. It also processes ErrorReported events.
JobStarted and JobScheduler.handleJobStart
When JobStarted event is received, JobScheduler.handleJobStart is called.
|
Note
|
It is JobHandler to post JobStarted.
|
handleJobStart(job: Job, startTime: Long) takes a JobSet (from jobSets) and checks whether it has already been started.
It posts StreamingListenerBatchStarted to StreamingListenerBus when the JobSet is about to start.
It posts StreamingListenerOutputOperationStarted to StreamingListenerBus.
You should see the following INFO message in the logs:
INFO JobScheduler: Starting job [job.id] from job set of time [jobSet.time] msJobCompleted and JobScheduler.handleJobCompletion
When JobCompleted event is received, it triggers JobScheduler.handleJobCompletion(job: Job, completedTime: Long).
|
Note
|
JobHandler posts JobCompleted events when it finishes running a streaming job.
|
handleJobCompletion looks the JobSet up (from the jobSets internal registry) and calls JobSet.handleJobCompletion(job) (that marks the JobSet as completed when no more streaming jobs are incomplete). It also calls Job.setEndTime(completedTime).
It posts StreamingListenerOutputOperationCompleted to StreamingListenerBus.
You should see the following INFO message in the logs:
INFO JobScheduler: Finished job [job.id] from job set of time [jobSet.time] msIf the entire JobSet is completed, it removes it from jobSets, and calls JobGenerator.onBatchCompletion.
You should see the following INFO message in the logs:
INFO JobScheduler: Total delay: [totalDelay] s for time [time] ms (execution: [processingDelay] s)It posts StreamingListenerBatchCompleted to StreamingListenerBus.
It reports an error if the job’s result is a failure.
StreamingListenerBus and StreamingListenerEvents
StreamingListenerBus is a asynchronous listener bus to post StreamingListenerEvent events to streaming listeners.
Internal Registries
JobScheduler maintains the following information in internal registries:
-
jobSets- a mapping between time and JobSets. See JobSet.
JobSet
A JobSet represents a collection of streaming jobs that were created at (batch) time for output streams (that have ultimately produced a streaming job as they may opt out).
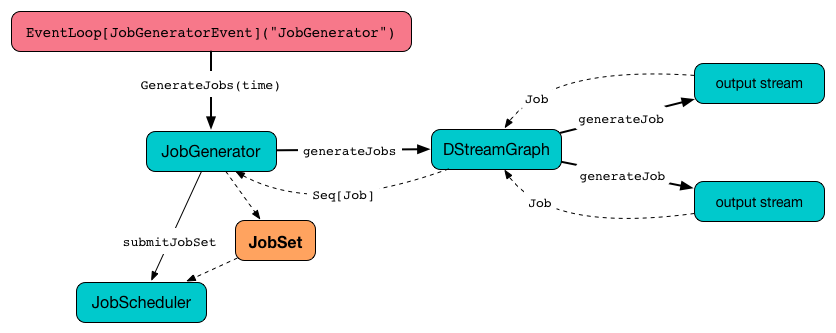
Figure 3. JobSet Created and Submitted to JobScheduler
JobSet tracks what streaming jobs are in incomplete state (in incompleteJobs internal registry).
|
Note
|
At the beginning (when JobSet is created) all streaming jobs are incomplete.
|
|
Caution
|
FIXME There is a duplication in how streaming jobs are tracked as completed since a Job knows about its _endTime. Is this a optimization? How much time does it buy us?
|
A JobSet tracks the following moments in its lifecycle:
-
submissionTimebeing the time when the instance was created. -
processingStartTimebeing the time when the first streaming job in the collection was started. -
processingEndTimebeing the time when the last streaming job in the collection finished processing.
A JobSet changes state over time. It can be in the following states:
-
Created after a
JobSetwas created.submissionTimeis set. -
Started after
JobSet.handleJobStartwas called.processingStartTimeis set. -
Completed after
JobSet.handleJobCompletionand no more jobs are incomplete (inincompleteJobsinternal registry).processingEndTimeis set.

Figure 4. JobSet States
Given the states a JobSet has delays:
-
Processing delay is the time spent for processing all the streaming jobs in a
JobSetfrom the time the very first job was started, i.e. the time between started and completed states. -
Total delay is the time from the batch time until the
JobSetwas completed.
|
Note
|
Total delay is always longer than processing delay. |
You can map a JobSet to a BatchInfo using toBatchInfo method.
|
Note
|
BatchInfo is used to create and post StreamingListenerBatchSubmitted, StreamingListenerBatchStarted, and StreamingListenerBatchCompleted events.
|
JobSet is used (created or processed) in: