mapWithState(spec: StateSpec[K, V, ST, MT]): MapWithStateDStream[K, V, ST, MT]Working with State using Stateful Operators
Building Stateful Stream Processing Pipelines using Spark (Streaming)
Stateful operators (like mapWithState or updateStateByKey) are part of the set of additional operators available on DStreams of key-value pairs, i.e. instances of DStream[(K, V)]. They allow you to build stateful stream processing pipelines and are also called cumulative calculations.
The motivation for the stateful operators is that by design streaming operators are stateless and know nothing about the previous records and hence a state. If you’d like to react to new records appropriately given the previous records you would have to resort to using persistent storages outside Spark Streaming.
|
Note
|
These additional operators are available automatically on pair DStreams through the Scala implicit conversion DStream.toPairDStreamFunctions.
|
mapWithState Operator
You create StateSpec instances for mapWithState operator using the factory methods StateSpec.function.
mapWithState creates a MapWithStateDStream dstream.
mapWithState Example
import org.apache.spark.streaming.{ StreamingContext, Seconds }
val ssc = new StreamingContext(sc, batchDuration = Seconds(5))
// checkpointing is mandatory
ssc.checkpoint("_checkpoints")
val rdd = sc.parallelize(0 to 9).map(n => (n, n % 2 toString))
import org.apache.spark.streaming.dstream.ConstantInputDStream
val sessions = new ConstantInputDStream(ssc, rdd)
import org.apache.spark.streaming.{State, StateSpec, Time}
val updateState = (batchTime: Time, key: Int, value: Option[String], state: State[Int]) => {
println(s">>> batchTime = $batchTime")
println(s">>> key = $key")
println(s">>> value = $value")
println(s">>> state = $state")
val sum = value.getOrElse("").size + state.getOption.getOrElse(0)
state.update(sum)
Some((key, value, sum)) // mapped value
}
val spec = StateSpec.function(updateState)
val mappedStatefulStream = sessions.mapWithState(spec)
mappedStatefulStream.print()StateSpec - Specification of mapWithState
StateSpec is a state specification of mapWithState and describes how the corresponding state RDD should work (RDD-wise) and maintain a state (streaming-wise).
|
Note
|
StateSpec is a Scala sealed abstract class and hence all the implementations are in the same compilation unit, i.e. source file.
|
It requires the following:
-
initialStatewhich is the initial state of the transformation, i.e. pairedRDD[(KeyType, StateType). -
numPartitionswhich is the number of partitions of the state RDD. It uses HashPartitioner with the given number of partitions. -
partitionerwhich is the partitioner of the state RDD. -
timeoutthat sets the idle duration after which the state of an idle key will be removed. A key and its state is considered idle if it has not received any data for at least the given idle duration.
StateSpec.function Factory Methods
You create StateSpec instances using the factory methods StateSpec.function (that differ in whether or not you want to access a batch time and return an optional mapped value):
// batch time and optional mapped return value
StateSpec.function(f: (Time, K, Option[V], State[S]) => Option[M]): StateSpec[K, V, S, M]
// no batch time and mandatory mapped value
StateSpec.function(f: (K, Option[V], State[S]) => M): StateSpec[K, V, S, M]Internally, the StateSpec.function executes ClosureCleaner.clean to clean up the input function f and makes sure that f can be serialized and sent over the wire (cf. Closure Cleaning (clean method)). It will throw an exception when the input function cannot be serialized.
updateStateByKey Operator
updateStateByKey(updateFn: (Seq[V], Option[S]) => Option[S]): DStream[(K, S)] (1)
updateStateByKey(updateFn: (Seq[V], Option[S]) => Option[S],
numPartitions: Int): DStream[(K, S)] (2)
updateStateByKey(updateFn: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner): DStream[(K, S)] (3)
updateStateByKey(updateFn: (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)],
partitioner: Partitioner,
rememberPartitioner: Boolean): DStream[(K, S)] (4)
updateStateByKey(updateFn: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner,
initialRDD: RDD[(K, S)]): DStream[(K, S)]
updateStateByKey(updateFn: (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)],
partitioner: Partitioner,
rememberPartitioner: Boolean,
initialRDD: RDD[(K, S)]): DStream[(K, S)]-
When not specified explicitly, the partitioner used is HashPartitioner with the number of partitions being the default level of parallelism of a Task Scheduler.
-
You may however specify the number of partitions explicitly for HashPartitioner to use.
-
This is the "canonical"
updateStateByKeythe other two variants (without a partitioner or the number of partitions) use that allows specifying a partitioner explicitly. It then executes the "last"updateStateByKeywithrememberPartitionerenabled. -
The "last"
updateStateByKey
updateStateByKey stateful operator allows for maintaining per-key state and updating it using updateFn. The updateFn is called for each key, and uses new data and existing state of the key, to generate an updated state.
|
Tip
|
You should use mapWithState operator instead as a much performance effective alternative. |
|
Note
|
Please consult SPARK-2629 Improved state management for Spark Streaming for performance-related changes to the operator. |
The state update function updateFn scans every key and generates a new state for every key given a collection of values per key in a batch and the current state for the key (if exists).
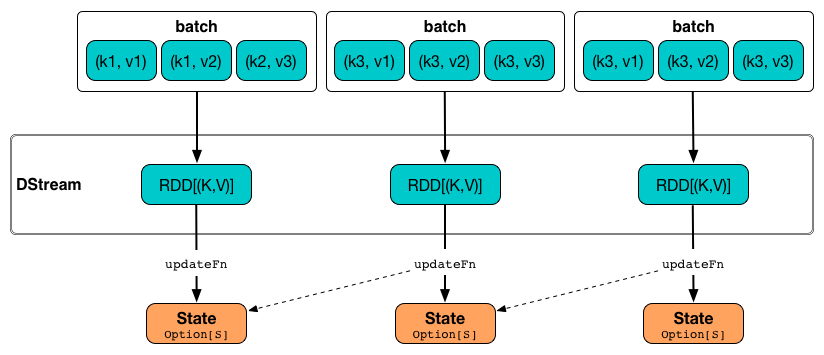
Figure 1. updateStateByKey in motion
Internally, updateStateByKey executes SparkContext.clean on the input function updateFn.
|
Note
|
The operator does not offer any timeout of idle data. |
updateStateByKey creates a StateDStream stream.
updateStateByKey Example
import org.apache.spark.streaming.{ StreamingContext, Seconds }
val ssc = new StreamingContext(sc, batchDuration = Seconds(5))
// checkpointing is mandatory
ssc.checkpoint("_checkpoints")
val rdd = sc.parallelize(0 to 9).map(n => (n, n % 2 toString))
import org.apache.spark.streaming.dstream.ConstantInputDStream
val clicks = new ConstantInputDStream(ssc, rdd)
// helper functions
val inc = (n: Int) => n + 1
def buildState: Option[Int] = {
println(s">>> >>> Initial execution to build state or state is deliberately uninitialized yet")
println(s">>> >>> Building the state being the number of calls to update state function, i.e. the number of batches")
Some(1)
}
// the state update function
val updateFn: (Seq[String], Option[Int]) => Option[Int] = { case (vs, state) =>
println(s">>> update state function with values only, i.e. no keys")
println(s">>> vs = $vs")
println(s">>> state = $state")
state.map(inc).orElse(buildState)
}
val statefulStream = clicks.updateStateByKey(updateFn)
statefulStream.print()