log4j.logger.org.apache.spark.streaming.scheduler.InputInfoTracker=INFOInputInfoTracker
InputInfoTracker tracks batch times and input record statistics for all registered input dstreams. It is used when JobGenerator submits streaming jobs for a batch interval and in turn propagated to streaming listeners (as StreamingListenerBatchSubmitted events).
|
Note
|
InputInfoTracker is managed by JobScheduler, i.e. it is created when JobScheduler starts and is stopped alongside.
|
InputInfoTracker uses internal registry batchTimeToInputInfos to maintain the mapping of batch times and input dstreams (i.e. another mapping between input stream ids and StreamInputInfo).
InputInfoTracker accumulates batch statistics for every batch when input streams are computing RDDs (and call reportInfo).
|
Note
|
It is up to input dstreams to have these batch statistics collected (and requires calling reportInfo method explicitly). The following input streams report information: |
|
Tip
|
Enable Add the following line to Refer to Logging. |
Batch Intervals and Input DStream Statistics — batchTimeToInputInfos Registry
batchTimeToInputInfos: HashMap[Time, HashMap[Int, StreamInputInfo]]batchTimeToInputInfos keeps track of batches (Time) with input dstreams (Int) that reported their statistics per batch.
Reporting Input DStream Statistics for Batch — reportInfo Method
reportInfo(batchTime: Time, inputInfo: StreamInputInfo): UnitreportInfo adds the input inputInfo for the batchTime to batchTimeToInputInfos.
Internally, reportInfo accesses the input dstream reports for batchTime using the internal batchTimeToInputInfos registry (creating a new empty one if batchTime has not been registered yet).
reportInfo then makes sure that the inputInfo input dstream has not been registered already for the input batchTime and throws a IllegalStateException otherwise.
Input stream [inputStreamId] for batch [batchTime] is already added into InputInfoTracker, this is an illegal stateUltimatelly, reportInfo adds the input report to batchTimeToInputInfos.
Requesting Statistics For Input DStreams For Batch — getInfo Method
getInfo(batchTime: Time): Map[Int, StreamInputInfo]getInfo returns all the reported input dstream statistics for batchTime. It returns an empty collection if there are no reports for a batch.
|
Note
|
getInfo is used when JobGenerator has successfully generated streaming jobs (and submits the jobs to JobScheduler).
|
Removing Batch Statistics — cleanup Method
cleanup(batchThreshTime: Time): Unitcleanup removes statistics for batches older than batchThreshTime. It removes the batches from batchTimeToInputInfos registry.
When executed, you should see the following INFO message (akin to garbage collection):
INFO InputInfoTracker: remove old batch metadata: [timesToCleanup] StreamInputInfo — Input Record Statistics
StreamInputInfo is used by input dstreams to report their statistics with InputInfoTracker.
StreamInputInfo contains:
-
The id of the input dstream
-
The number of records in a batch
-
A metadata (with
Description)
|
Note
|
Description is used in BatchPage (Details of batch) in web UI for Streaming under Input Metadata.
|
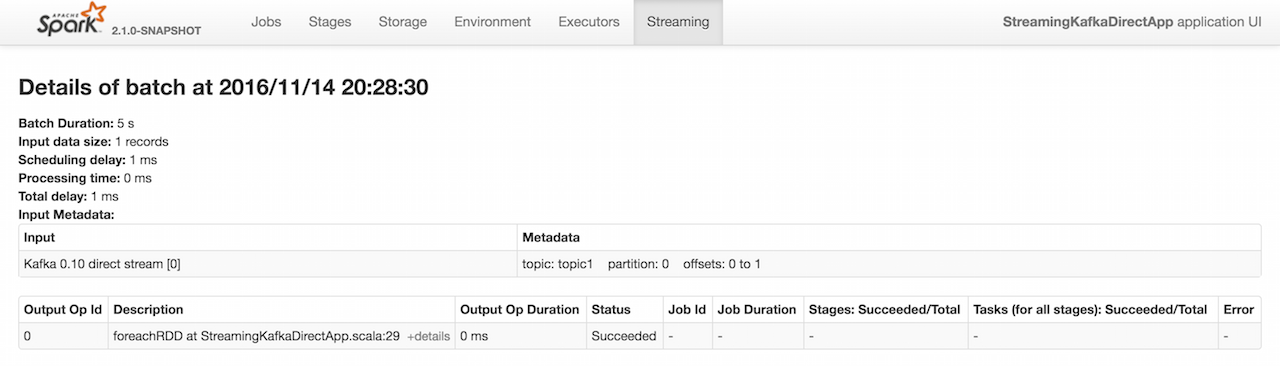
Figure 1. Details of batch in web UI for Kafka 0.10 direct stream with Metadata