log4j.logger.org.apache.spark.streaming.scheduler.JobGenerator=DEBUGJobGenerator
JobGenerator asynchronously generates streaming jobs every batch interval (using recurring timer) that may or may not be checkpointed afterwards. It also periodically requests clearing up metadata and checkpoint data for each input dstream.
|
Note
|
JobGenerator is completely owned and managed by JobScheduler, i.e. JobScheduler creates an instance of JobGenerator and starts it (while being started itself).
|
|
Tip
|
Enable Add the following line to Refer to Logging. |
Starting JobGenerator (start method)
start(): Unitstart method creates and starts the internal JobGeneratorEvent handler.
|
Note
|
start is called when JobScheduler starts.
|
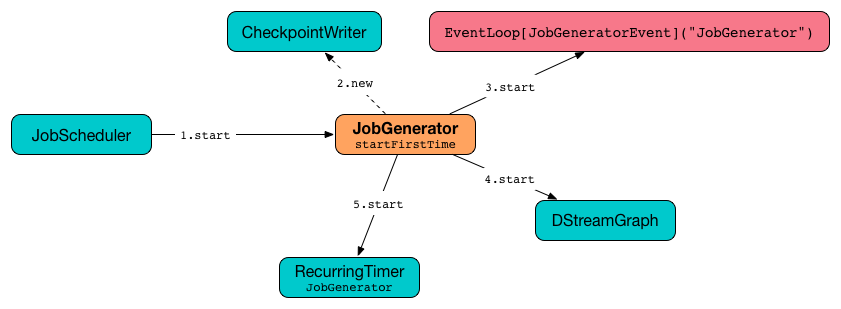
Figure 1. JobGenerator Start (First Time) procedure (tip: follow the numbers)
It first checks whether or not the internal event loop has already been created which is the way to know that the JobScheduler was started. If so, it does nothing and exits.
Only if checkpointing is enabled, it creates CheckpointWriter.
It then creates and starts the internal JobGeneratorEvent handler.
Depending on whether checkpoint directory is available or not it restarts itself or starts, respectively.
Start Time and startFirstTime Method
startFirstTime(): UnitstartFirstTime starts DStreamGraph and the timer.
|
Note
|
startFirstTime is called when JobGenerator starts (and no checkpoint directory is available).
|
It first requests timer for the start time and passes the start time along to DStreamGraph.start and RecurringTimer.start.
|
Note
|
The start time has the property of being a multiple of batch interval and after the current system time. It is in the hands of recurring timer to calculate a time with the property given a batch interval. |
|
Note
|
Because of the property of the start time, DStreamGraph.start is passed the time of one batch interval before the calculated start time. |
|
Note
|
When recurring timer starts for |
Right before the method finishes, you should see the following INFO message in the logs:
INFO JobGenerator: Started JobGenerator at [startTime] msStopping JobGenerator (stop method)
stop(processReceivedData: Boolean): Unitstop stops a JobGenerator. The processReceivedData flag tells whether to stop JobGenerator gracefully, i.e. after having processed all received data and pending streaming jobs, or not.
|
Note
|
|
It first checks whether eventLoop internal event loop was ever started (through checking null).
|
Warning
|
It doesn’t set eventLoop to null (but it is assumed to be the marker).
|
When JobGenerator should stop immediately, i.e. ignoring unprocessed data and pending streaming jobs (processReceivedData flag is disabled), you should see the following INFO message in the logs:
INFO JobGenerator: Stopping JobGenerator immediatelyIt requests the timer to stop forcefully (interruptTimer is enabled) and stops the graph.
Otherwise, when JobGenerator should stop gracefully, i.e. processReceivedData flag is enabled, you should see the following INFO message in the logs:
INFO JobGenerator: Stopping JobGenerator gracefullyYou should immediately see the following INFO message in the logs:
INFO JobGenerator: Waiting for all received blocks to be consumed for job generationJobGenerator waits spark.streaming.gracefulStopTimeout milliseconds or until ReceiverTracker has any blocks left to be processed (whatever is shorter) before continuing.
|
Note
|
Poll (sleeping) time is 100 milliseconds and is not configurable.
|
When a timeout occurs, you should see the WARN message in the logs:
WARN JobGenerator: Timed out while stopping the job generator (timeout = [stopTimeoutMs])After the waiting is over, you should see the following INFO message in the logs:
INFO JobGenerator: Waited for all received blocks to be consumed for job generationIt requests timer to stop generating streaming jobs (interruptTimer flag is disabled) and stops the graph.
You should see the following INFO message in the logs:
INFO JobGenerator: Stopped generation timerYou should immediately see the following INFO message in the logs:
INFO JobGenerator: Waiting for jobs to be processed and checkpoints to be writtenJobGenerator waits spark.streaming.gracefulStopTimeout milliseconds or until all the batches have been processed (whatever is shorter) before continuing. It waits for batches to complete using last processed batch internal property that should eventually be exactly the time when the timer was stopped (it returns the last time for which the streaming job was generated).
|
Note
|
spark.streaming.gracefulStopTimeout is ten times the batch interval by default. |
After the waiting is over, you should see the following INFO message in the logs:
INFO JobGenerator: Waited for jobs to be processed and checkpoints to be writtenRegardless of processReceivedData flag, if checkpointing was enabled, it stops CheckpointWriter.
It then stops the event loop.
As the last step, when JobGenerator is assumed to be stopped completely, you should see the following INFO message in the logs:
INFO JobGenerator: Stopped JobGeneratorStarting from Checkpoint (restart method)
restart(): Unitrestart starts JobGenerator from checkpoint. It basically reconstructs the runtime environment of the past execution that may have stopped immediately, i.e. without waiting for all the streaming jobs to complete when checkpoint was enabled, or due to a abrupt shutdown (a unrecoverable failure or similar).
|
Note
|
restart is called when JobGenerator starts and checkpoint is present.
|
restart first calculates the batches that may have been missed while JobGenerator was down, i.e. batch times between the current restart time and the time of initial checkpoint.
|
Warning
|
restart doesn’t check whether the initial checkpoint exists or not that may lead to NPE.
|
You should see the following INFO message in the logs:
INFO JobGenerator: Batches during down time ([size] batches): [downTimes]It then ask the initial checkpoint for pending batches, i.e. the times of streaming job sets.
|
Caution
|
FIXME What are the pending batches? Why would they ever exist? |
You should see the following INFO message in the logs:
INFO JobGenerator: Batches pending processing ([size] batches): [pendingTimes]It then computes the batches to reschedule, i.e. pending and down time batches that are before restart time.
You should see the following INFO message in the logs:
INFO JobGenerator: Batches to reschedule ([size] batches): [timesToReschedule]For each batch to reschedule, restart requests ReceiverTracker to allocate blocks to batch and submits streaming job sets for execution.
|
Note
|
restart mimics generateJobs method.
|
It restarts the timer (by using restartTime as startTime).
You should see the following INFO message in the logs:
INFO JobGenerator: Restarted JobGenerator at [restartTime]Last Processed Batch (aka lastProcessedBatch)
JobGenerator tracks the last batch time for which the batch was completed and cleanups performed as lastProcessedBatch internal property.
The only purpose of the lastProcessedBatch property is to allow for stopping the streaming context gracefully, i.e. to wait until all generated streaming jobs are completed.
|
Note
|
It is set to the batch time after ClearMetadata Event is processed (when checkpointing is disabled). |
JobGenerator eventLoop and JobGeneratorEvent Handler
JobGenerator uses the internal EventLoop event loop to process JobGeneratorEvent events asynchronously (one event at a time) on a separate dedicated single thread.
|
Note
|
EventLoop uses unbounded java.util.concurrent.LinkedBlockingDeque.
|
For every JobGeneratorEvent event, you should see the following DEBUG message in the logs:
DEBUG JobGenerator: Got event [event]There are 4 JobGeneratorEvent event types:
See below in the document for the extensive coverage of the supported JobGeneratorEvent event types.
GenerateJobs Event and generateJobs method
|
Note
|
GenerateJobs events are posted regularly by the internal timer RecurringTimer every batch interval. The time parameter is exactly the current batch time.
|
When GenerateJobs(time: Time) event is received the internal generateJobs method is called that submits a collection of streaming jobs for execution.
generateJobs(time: Time)It first calls ReceiverTracker.allocateBlocksToBatch (it does nothing when there are no receiver input streams in use), and then requests DStreamGraph for streaming jobs for a given batch time.
If the above two calls have finished successfully, InputInfoTracker is requested for record statistics of every registered input dstream for the given batch time that, together with the collection of streaming jobs (from DStreamGraph), is then passed on to JobScheduler.submitJobSet (as a JobSet).
In case of failure, JobScheduler.reportError is called.
Ultimately, DoCheckpoint event is posted (with clearCheckpointDataLater being disabled, i.e. false).
DoCheckpoint Event and doCheckpoint method
|
Note
|
DoCheckpoint events are posted by JobGenerator itself as part of generating streaming jobs (with clearCheckpointDataLater being disabled, i.e. false) and clearing metadata (with clearCheckpointDataLater being enabled, i.e. true).
|
DoCheckpoint events trigger execution of doCheckpoint method.
doCheckpoint(time: Time, clearCheckpointDataLater: Boolean)If checkpointing is disabled or the current batch time is not eligible for checkpointing, the method does nothing and exits.
|
Note
|
A current batch is eligible for checkpointing when the time interval between current batch time and zero time is a multiple of checkpoint interval.
|
|
Caution
|
FIXME Who checks and when whether checkpoint interval is greater than batch interval or not? What about checking whether a checkpoint interval is a multiple of batch time? |
|
Caution
|
FIXME What happens when you start a StreamingContext with a checkpoint directory that was used before? |
Otherwise, when checkpointing should be performed, you should see the following INFO message in the logs:
INFO JobGenerator: Checkpointing graph for time [time] msIt requests DStreamGraph for updating checkpoint data and CheckpointWriter for writing a new checkpoint. Both are given the current batch time.
ClearMetadata Event and clearMetadata method
|
Note
|
ClearMetadata are posted after a micro-batch for a batch time has completed.
|
It removes old RDDs that have been generated and collected so far by output streams (managed by DStreamGraph). It is a sort of garbage collector.
When ClearMetadata(time) arrives, it first asks DStreamGraph to clear metadata for the given time.
If checkpointing is enabled, it posts a DoCheckpoint event (with clearCheckpointDataLater being enabled, i.e. true) and exits.
Otherwise, when checkpointing is disabled, it asks DStreamGraph for the maximum remember duration across all the input streams and requests ReceiverTracker and the InputInfoTracker to do their cleanups.
|
Caution
|
FIXME Describe cleanups of ReceiverTracker. |
Eventually, it marks the batch as fully processed, i.e. that the batch completed as well as checkpointing or metadata cleanups, using the internal lastProcessedBatch marker.
ClearCheckpointData Event and clearCheckpointData method
|
Note
|
ClearCheckpointData event is posted after checkpoint is saved and checkpoint cleanup is requested.
|
ClearCheckpointData events trigger execution of clearCheckpointData method.
clearCheckpointData(time: Time)In short, clearCheckpointData requests the DStreamGraph, ReceiverTracker, and InputInfoTracker to do their cleaning and marks the current batch time as fully processed.
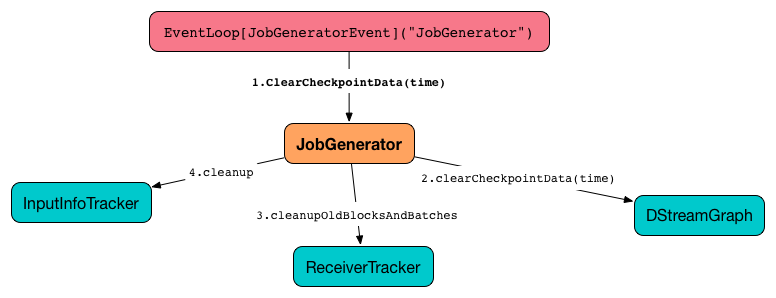
Figure 2. JobGenerator and ClearCheckpointData event
When executed, clearCheckpointData first requests DStreamGraph to clear checkpoint data for the given batch time.
It then asks DStreamGraph for the maximum remember interval. Given the maximum remember interval JobGenerator requests ReceiverTracker to cleanup old blocks and batches and InputInfoTracker to do cleanup for data accumulated before the maximum remember interval (from time).
Having done that, the current batch time is marked as fully processed.
Whether or Not to Checkpoint (aka shouldCheckpoint)
shouldCheckpoint flag is used to control a CheckpointWriter as well as whether to post DoCheckpoint in clearMetadata or not.
shouldCheckpoint flag is enabled (i.e. true) when checkpoint interval and checkpoint directory are defined (i.e. not null) in StreamingContext.
|
Note
|
However the flag is completely based on the properties of StreamingContext, these dependent properties are used by JobScheduler only. Really? |
|
Caution
|
FIXME Report an issue When and what for are they set? Can one of Answer: See Setup Validation. |
|
Caution
|
Potential bug: Can StreamingContext have no checkpoint duration set? At least, the batch interval must be set. In other words, it’s StreamingContext to say whether to checkpoint or not and there should be a method in StreamingContext not JobGenerator.
|
timer RecurringTimer
timer RecurringTimer (with the name being JobGenerator) is used to posts GenerateJobs events to the internal JobGeneratorEvent handler every batch interval.
|
Note
|
timer is created when JobGenerator is. It starts when JobGenerator starts (for the first time only).
|