StateDStream
StateDStream is the specialized DStream that is the result of updateStateByKey stateful operator. It is a wrapper around a parent key-value pair dstream to build stateful pipeline (by means of updateStateByKey operator) and as a stateful dstream enables checkpointing (and hence requires some additional setup).
It uses a parent key-value pair dstream, updateFunc update state function, a partitioner, a flag whether or not to preservePartitioning and an optional key-value pair initialRDD.
It works with MEMORY_ONLY_SER storage level enabled.
The only dependency of StateDStream is the input parent key-value pair dstream.
The slide duration is exactly the same as that in parent.
It forces checkpointing regardless of the current dstream configuration, i.e. the internal mustCheckpoint is enabled.
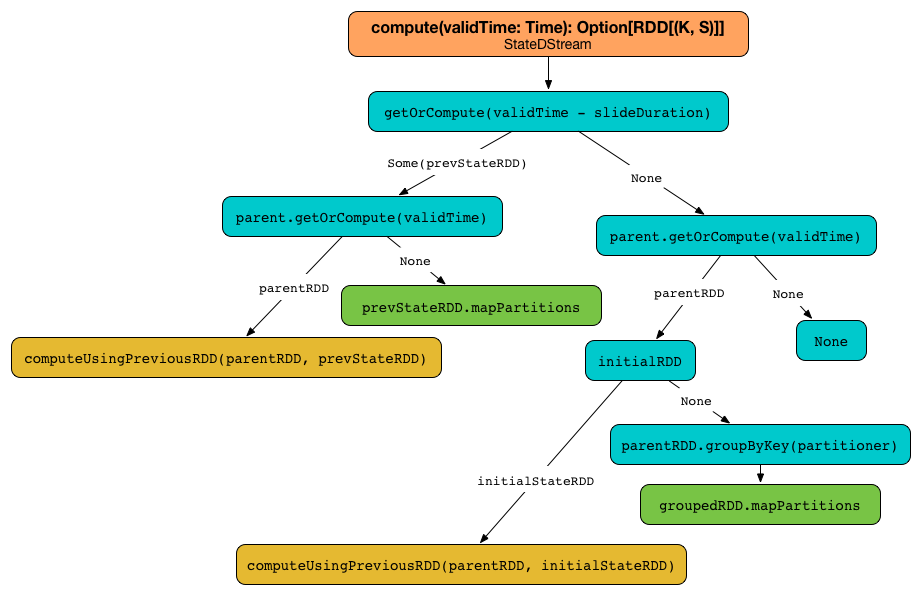
When requested to compute a RDD it first attempts to get the state RDD for the previous batch (using DStream.getOrCompute). If there is one, parent stream is requested for a RDD for the current batch (using DStream.getOrCompute). If parent has computed one, computeUsingPreviousRDD(parentRDD, prevStateRDD) is called.
|
Caution
|
FIXME When could getOrCompute not return an RDD? How does this apply to the StateDStream? What about the parent’s getOrCompute?
|
If however parent has not generated a RDD for the current batch but the state RDD existed, updateFn is called for every key of the state RDD to generate a new state per partition (using RDD.mapPartitions)
|
Note
|
No input data for already-running input stream triggers (re)computation of the state RDD (per partition). |
Figure 1. Computing stateful RDDs (StateDStream.compute)
If the state RDD has been found, which means that this is the first input data batch, parent stream is requested to getOrCompute the RDD for the current batch.
Otherwise, when no state RDD exists, parent stream is requested for a RDD for the current batch (using DStream.getOrCompute) and when no RDD was generated for the batch, no computation is triggered.
|
Note
|
When the stream processing starts, i.e. no state RDD exists, and there is no input data received, no computation is triggered. |
Given no state RDD and with parent RDD computed, when initialRDD is NONE, the input data batch (as parent RDD) is grouped by key (using groupByKey with partitioner) and then the update state function updateFunc is applied to the partitioned input data (using RDD.mapPartitions) with None state. Otherwise, computeUsingPreviousRDD(parentRDD, initialStateRDD) is called.
updateFunc - State Update Function
The signature of updateFunc is as follows:
updateFunc: (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)]It should be read as given a collection of triples of a key, new records for the key, and the current state for the key, generate a collection of keys and their state.
computeUsingPreviousRDD
computeUsingPreviousRDD(parentRDD: RDD[(K, V)], prevStateRDD: RDD[(K, S)]): Option[RDD[(K, S)]]The computeUsingPreviousRDD method uses cogroup and mapPartitions to build the final state RDD.
|
Note
|
Regardless of the return type Option[RDD[(K, S)]] that really allows no state, it will always return some state.
|
It first performs cogroup of parentRDD and prevStateRDD using the constructor’s partitioner so it has a pair of iterators of elements of each RDDs per every key.
|
Note
|
It is acceptable to end up with keys that have no new records per batch, but these keys do have a state (since they were received previously when no state might have been built yet). |
|
Note
|
The signature of |
It defines an internal update function finalFunc that maps over the collection of all the keys, new records per key, and at-most-one-element state per key to build new iterator that ensures that:
-
a state per key exists (it is
Noneor the state built so far) -
the lazy iterable of new records is transformed into an eager sequence.
|
Caution
|
FIXME Why is the transformation from an Iterable into a Seq so important? Why could not the constructor’s updateFunc accept the former? |
With every triple per every key, the internal update function calls the constructor’s updateFunc.
The state RDD is a cogrouped RDD (on parentRDD and prevStateRDD using the constructor’s partitioner) with every element per partition mapped over using the internal update function finalFunc and the constructor’s preservePartitioning (through mapPartitions).
|
Caution
|
FIXME Why is preservePartitioning important? What happens when mapPartitions does not preserve partitioning (which by default it does not!)
|