logicalPlan: LogicalPlanStreamExecution — Base of Stream Execution Engines
StreamExecution is the base of stream execution engines (aka streaming query processing engines) that can run a structured query (on a stream execution thread).
|
Note
|
Continuous query, streaming query, continuous Dataset, streaming Dataset are all considered high-level synonyms for an executable entity that stream execution engines run using the analyzed logical plan internally. |
| Property | Description | ||
|---|---|---|---|
|
Analyzed logical plan of the streaming query to execute Used when
|
||
|
Executes (runs) the activated streaming query Used exclusively when |
Streaming Query and Stream Execution Engine
import org.apache.spark.sql.streaming.StreamingQuery
assert(sq.isInstanceOf[StreamingQuery])
import org.apache.spark.sql.execution.streaming.StreamingQueryWrapper
val se = sq.asInstanceOf[StreamingQueryWrapper].streamingQuery
scala> :type se
org.apache.spark.sql.execution.streaming.StreamExecution
StreamExecution uses the spark.sql.streaming.minBatchesToRetain configuration property to allow the StreamExecutions to discard old log entries (from the offset and commit logs).
| StreamExecution | Description |
|---|---|
Used in Continuous Stream Processing |
|
Used in Micro-Batch Stream Processing |
|
Note
|
StreamExecution does not support adaptive query execution and cost-based optimizer (and turns them off when requested to run stream processing).
|
StreamExecution is the execution environment of a single streaming query (aka streaming Dataset) that is executed every trigger and in the end adds the results to a sink.
|
Note
|
StreamExecution corresponds to a single streaming query with one or more streaming sources and exactly one streaming sink.
|
import org.apache.spark.sql.streaming.Trigger
import scala.concurrent.duration._
val q = spark.
readStream.
format("rate").
load.
writeStream.
format("console").
trigger(Trigger.ProcessingTime(10.minutes)).
start
scala> :type q
org.apache.spark.sql.streaming.StreamingQuery
// Pull out StreamExecution off StreamingQueryWrapper
import org.apache.spark.sql.execution.streaming.{StreamExecution, StreamingQueryWrapper}
val se = q.asInstanceOf[StreamingQueryWrapper].streamingQuery
scala> :type se
org.apache.spark.sql.execution.streaming.StreamExecution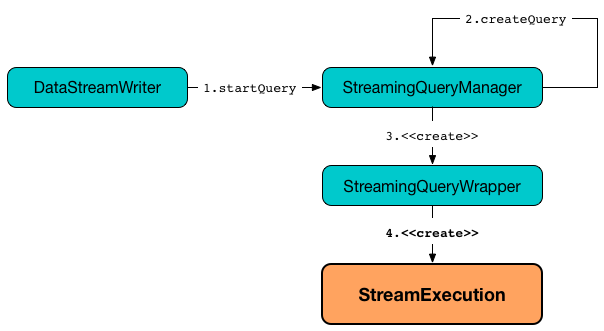
Figure 1. Creating Instance of StreamExecution
|
Note
|
DataStreamWriter describes how the results of executing batches of a streaming query are written to a streaming sink. |
When started, StreamExecution starts a stream execution thread that simply runs stream processing (and hence the streaming query).

Figure 2. StreamExecution’s Starting Streaming Query (on Execution Thread)
StreamExecution is a ProgressReporter and reports status of the streaming query (i.e. when it starts, progresses and terminates) by posting StreamingQueryListener events.
import org.apache.spark.sql.streaming.Trigger
import scala.concurrent.duration._
val sq = spark
.readStream
.text("server-logs")
.writeStream
.format("console")
.queryName("debug")
.trigger(Trigger.ProcessingTime(20.seconds))
.start
// Enable the log level to see the INFO and DEBUG messages
// log4j.logger.org.apache.spark.sql.execution.streaming.StreamExecution=DEBUG
17/06/18 21:21:07 INFO StreamExecution: Starting new streaming query.
17/06/18 21:21:07 DEBUG StreamExecution: getOffset took 5 ms
17/06/18 21:21:07 DEBUG StreamExecution: Stream running from {} to {}
17/06/18 21:21:07 DEBUG StreamExecution: triggerExecution took 9 ms
17/06/18 21:21:07 DEBUG StreamExecution: Execution stats: ExecutionStats(Map(),List(),Map())
17/06/18 21:21:07 INFO StreamExecution: Streaming query made progress: {
"id" : "8b57b0bd-fc4a-42eb-81a3-777d7ba5e370",
"runId" : "920b227e-6d02-4a03-a271-c62120258cea",
"name" : "debug",
"timestamp" : "2017-06-18T19:21:07.693Z",
"numInputRows" : 0,
"processedRowsPerSecond" : 0.0,
"durationMs" : {
"getOffset" : 5,
"triggerExecution" : 9
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "FileStreamSource[file:/Users/jacek/dev/oss/spark/server-logs]",
"startOffset" : null,
"endOffset" : null,
"numInputRows" : 0,
"processedRowsPerSecond" : 0.0
} ],
"sink" : {
"description" : "org.apache.spark.sql.execution.streaming.ConsoleSink@2460208a"
}
}
17/06/18 21:21:10 DEBUG StreamExecution: Starting Trigger Calculation
17/06/18 21:21:10 DEBUG StreamExecution: getOffset took 3 ms
17/06/18 21:21:10 DEBUG StreamExecution: triggerExecution took 3 ms
17/06/18 21:21:10 DEBUG StreamExecution: Execution stats: ExecutionStats(Map(),List(),Map())StreamExecution tracks streaming data sources in uniqueSources internal registry.
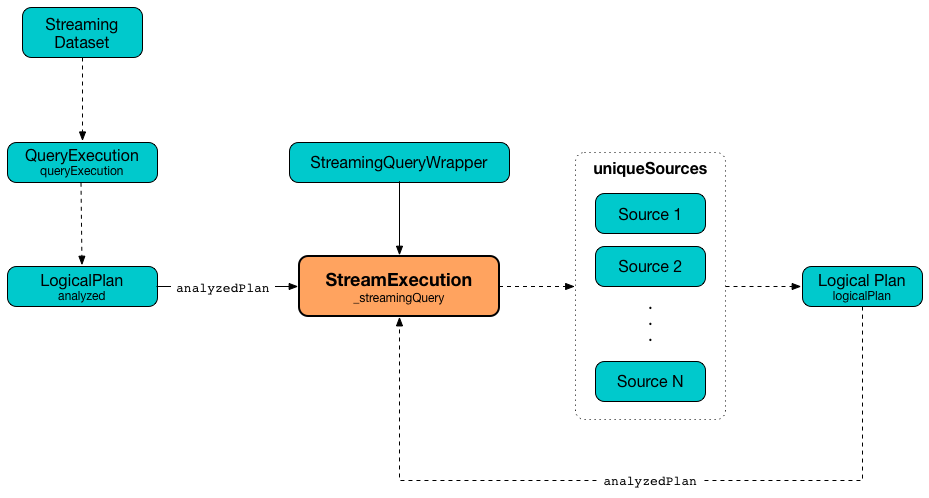
Figure 3. StreamExecution’s uniqueSources Registry of Streaming Data Sources
StreamExecution collects durationMs for the execution units of streaming batches.
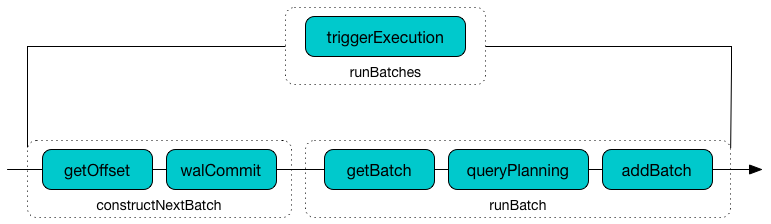
Figure 4. StreamExecution’s durationMs
scala> :type q
org.apache.spark.sql.streaming.StreamingQuery
scala> println(q.lastProgress)
{
"id" : "03fc78fc-fe19-408c-a1ae-812d0e28fcee",
"runId" : "8c247071-afba-40e5-aad2-0e6f45f22488",
"name" : null,
"timestamp" : "2017-08-14T20:30:00.004Z",
"batchId" : 1,
"numInputRows" : 432,
"inputRowsPerSecond" : 0.9993568953312452,
"processedRowsPerSecond" : 1380.1916932907347,
"durationMs" : {
"addBatch" : 237,
"getBatch" : 26,
"getOffset" : 0,
"queryPlanning" : 1,
"triggerExecution" : 313,
"walCommit" : 45
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8]",
"startOffset" : 0,
"endOffset" : 432,
"numInputRows" : 432,
"inputRowsPerSecond" : 0.9993568953312452,
"processedRowsPerSecond" : 1380.1916932907347
} ],
"sink" : {
"description" : "ConsoleSink[numRows=20, truncate=true]"
}
}StreamExecution uses OffsetSeqLog and BatchCommitLog metadata logs for write-ahead log (to record offsets to be processed) and that have already been processed and committed to a streaming sink, respectively.
|
Tip
|
Monitor offsets and commits metadata logs to know the progress of a streaming query.
|
StreamExecution delays polling for new data for 10 milliseconds (when no data was available to process in a batch). Use spark.sql.streaming.pollingDelay Spark property to control the delay.
Every StreamExecution is uniquely identified by an ID of the streaming query (which is the id of the StreamMetadata).
|
Note
|
Since the StreamMetadata is persisted (to the metadata file in the checkpoint directory), the streaming query ID "survives" query restarts as long as the checkpoint directory is preserved.
|
StreamExecution is also uniquely identified by a run ID of the streaming query. A run ID is a randomly-generated 128-bit universally unique identifier (UUID) that is assigned at the time StreamExecution is created.
|
Note
|
runId does not "survive" query restarts and will always be different yet unique (across all active queries).
|
|
Note
|
The name, id and runId are all unique across all active queries (in a StreamingQueryManager). The difference is that: |
StreamExecution uses a StreamMetadata that is persisted in the metadata file in the checkpoint directory. If the metadata file is available it is read and is the way to recover the ID of a streaming query when resumed (i.e. restarted after a failure or a planned stop).
StreamExecution uses __is_continuous_processing local property (default: false) to differentiate between ContinuousExecution (true) and MicroBatchExecution (false) which is used when StateStoreRDD is requested to compute a partition (and finds a StateStore for a given version).
|
Tip
|
Enable Add the following line to Refer to Logging. |
Creating StreamExecution Instance
StreamExecution takes the following to be created:
StreamExecution initializes the internal properties.
|
Note
|
StreamExecution is a Scala abstract class and cannot be created directly. It is created indirectly when the concrete StreamExecutions are.
|
Write-Ahead Log (WAL) of Offsets — offsetLog Property
offsetLog: OffsetSeqLogoffsetLog is a Hadoop DFS-based metadata storage (of OffsetSeqs) with offsets metadata directory.
offsetLog is used as Write-Ahead Log of Offsets to persist offsets of the data about to be processed in every trigger.
|
Note
|
Metadata log or metadata checkpoint are synonyms and are often used interchangeably. |
The number of entries in the OffsetSeqLog is controlled using spark.sql.streaming.minBatchesToRetain configuration property (default: 100). Stream execution engines discard (purge) offsets from the offsets metadata log when the current batch ID (in MicroBatchExecution) or the epoch committed (in ContinuousExecution) is above the threshold.
|
Note
|
|
State of Streaming Query (Execution) — state Property
state: AtomicReference[State]state indicates the internal state of execution of the streaming query (as java.util.concurrent.atomic.AtomicReference).
| Name | Description |
|---|---|
|
|
|
|
|
|
|
Used only when |
Available Offsets (StreamProgress) — availableOffsets Property
availableOffsets: StreamProgressavailableOffsets is a collection of offsets per streaming source to track what data (by offset) is available for processing for every streaming source in the streaming query (and have not yet been committed).
availableOffsets works in tandem with the committedOffsets internal registry.
availableOffsets is empty when StreamExecution is created (i.e. no offsets are reported for any streaming source in the streaming query).
|
Note
|
|
Committed Offsets (StreamProgress) — committedOffsets Property
committedOffsets: StreamProgresscommittedOffsets is a collection of offsets per streaming source to track what data (by offset) has already been processed and committed (to the sink or state stores) for every streaming source in the streaming query.
committedOffsets works in tandem with the availableOffsets internal registry.
|
Note
|
|
Fully-Qualified (Resolved) Path to Checkpoint Root Directory — resolvedCheckpointRoot Property
resolvedCheckpointRoot: StringresolvedCheckpointRoot is a fully-qualified path of the given checkpoint root directory.
The given checkpoint root directory is defined using checkpointLocation option or the spark.sql.streaming.checkpointLocation configuration property with queryName option.
checkpointLocation and queryName options are defined when StreamingQueryManager is requested to create a streaming query.
resolvedCheckpointRoot is used when creating the path to the checkpoint directory and when StreamExecution finishes running streaming batches.
resolvedCheckpointRoot is used for the logicalPlan (while transforming analyzedPlan and planning StreamingRelation logical operators to corresponding StreamingExecutionRelation physical operators with the streaming data sources created passing in the path to sources directory to store checkpointing metadata).
|
Tip
|
You can see |
Internally, resolvedCheckpointRoot creates a Hadoop org.apache.hadoop.fs.Path for checkpointRoot and makes it qualified.
|
Note
|
resolvedCheckpointRoot uses SparkSession to access SessionState for a Hadoop configuration.
|
Offset Commit Log — commits Metadata Checkpoint Directory
StreamExecution uses offset commit log (CommitLog with commits metadata checkpoint directory) for streaming batches successfully executed (with a single file per batch with a file name being the batch id) or committed epochs.
|
Note
|
Metadata log or metadata checkpoint are synonyms and are often used interchangeably. |
commitLog is used by the stream execution engines for the following:
-
MicroBatchExecutionis requested to run an activated streaming query (that in turn requests to populate the start offsets at the very beginning of the streaming query execution and later regularly every single batch) -
ContinuousExecutionis requested to run an activated streaming query in continuous mode (that in turn requests to retrieve the start offsets at the very beginning of the streaming query execution and later regularly every commit)
Last Query Execution Of Streaming Query (IncrementalExecution) — lastExecution Property
lastExecution: IncrementalExecution|
Note
|
lastExecution is part of the ProgressReporter Contract for the QueryExecution of a streaming query.
|
lastExecution is a IncrementalExecution (a QueryExecution of a streaming query) of the most recent (last) execution.
lastExecution is created when the stream execution engines are requested for the following:
-
MicroBatchExecutionis requested to run a single streaming micro-batch (when in queryPlanning Phase) -
ContinuousExecutionstream execution engine is requested to run a streaming query (when in queryPlanning Phase)
lastExecution is used when:
-
StreamExecutionis requested to explain a streaming query (via explainInternal) -
ProgressReporteris requested to extractStateOperatorMetrics, extractExecutionStats, and extractSourceToNumInputRows -
MicroBatchExecutionstream execution engine is requested to construct or skip the next streaming micro-batch (based on StateStoreWriters in a streaming query), run a single streaming micro-batch (when in addBatch Phase and updating watermark and committing offsets to offset commit log) -
ContinuousExecutionstream execution engine is requested to run a streaming query (when in runContinuous Phase) -
For debugging query execution of streaming queries (using
debugCodegen)
Explaining Streaming Query — explain Method
explain(): Unit (1)
explain(extended: Boolean): Unit-
Turns the
extendedflag off (false)
explain simply prints out explainInternal to the standard output.
|
Note
|
explain is used when…FIXME
|
explainInternal Method
explainInternal(extended: Boolean): StringexplainInternal…FIXME
|
Note
|
|
Stopping Streaming Sources and Readers — stopSources Method
stopSources(): UnitstopSources requests every streaming source (in the streaming query) to stop.
In case of an non-fatal exception, stopSources prints out the following WARN message to the logs:
Failed to stop streaming source: [source]. Resources may have leaked.|
Note
|
|
Running Stream Processing — runStream Internal Method
runStream(): UnitrunStream simply prepares the environment to execute the activated streaming query.
|
Note
|
runStream is used exclusively when the stream execution thread is requested to start (when DataStreamWriter is requested to start an execution of the streaming query).
|
Internally, runStream sets the job group (to all the Spark jobs started by this thread) as follows:
-
runId for the job group ID
-
getBatchDescriptionString for the job group description (to display in web UI)
-
interruptOnCancelflag on
|
Note
|
Read up on SparkContext.setJobGroup method in The Internals of Apache Spark book. |
runStream sets sql.streaming.queryId local property to id.
runStream requests the MetricsSystem to register the MetricsReporter when spark.sql.streaming.metricsEnabled configuration property is on (default: off / false).
runStream notifies StreamingQueryListeners that the streaming query has been started (by posting a new QueryStartedEvent event with id, runId, and name).
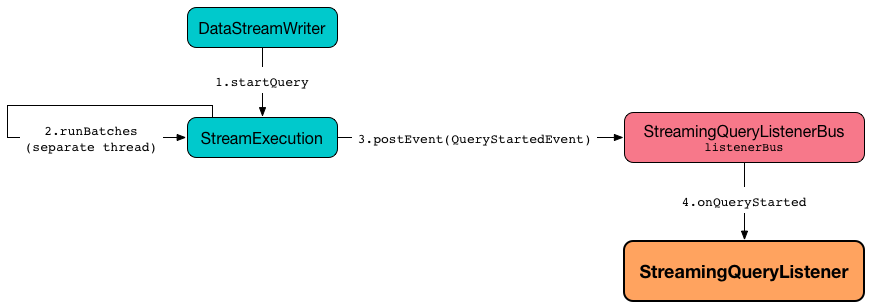
Figure 5. StreamingQueryListener Notified about Query’s Start (onQueryStarted)
runStream unblocks the main starting thread (by decrementing the count of the startLatch that when 0 lets the starting thread continue).
|
Caution
|
FIXME A picture with two parallel lanes for the starting thread and daemon one for the query. |
runStream updates the status message to be Initializing sources.
runStream initializes the analyzed logical plan.
|
Note
|
The analyzed logical plan is a lazy value in Scala and is initialized when requested the very first time. |
runStream disables adaptive query execution and cost-based join optimization (by turning spark.sql.adaptive.enabled and spark.sql.cbo.enabled configuration properties off, respectively).
runStream creates a new "zero" OffsetSeqMetadata.
(Only when in INITIALIZING state) runStream enters ACTIVE state:
-
Decrements the count of initializationLatch
-
Executes the activated streaming query (which is different per StreamExecution, i.e. ContinuousExecution or MicroBatchExecution).
|
Note
|
runBatches does the main work only when first started (i.e. when state is INITIALIZING).
|
runStream…FIXME (describe the failed and stop states)
Once TriggerExecutor has finished executing batches, runBatches updates the status message to Stopped.
|
Note
|
TriggerExecutor finishes executing batches when batch runner returns whether the streaming query is stopped or not (which is when the internal state is not TERMINATED).
|
|
Caution
|
FIXME Describe catch block for exception handling
|
Running Stream Processing — finally Block
runStream releases the startLatch and initializationLatch locks.
runStream stopSources.
runStream sets the state to TERMINATED.
runStream sets the StreamingQueryStatus with the isTriggerActive and isDataAvailable flags off (false).
runStream removes the stream metrics reporter from the application’s MetricsSystem.
runStream requests the StreamingQueryManager to handle termination of a streaming query.
runStream creates a new QueryTerminatedEvent (with the id and run id of the streaming query) and posts it.
With the deleteCheckpointOnStop flag enabled and no StreamingQueryException reported, runStream deletes the checkpoint directory recursively.
In the end, runStream releases the terminationLatch lock.
TriggerExecutor’s Batch Runner
Batch Runner (aka batchRunner) is an executable block executed by TriggerExecutor in runBatches.
batchRunner starts trigger calculation.
As long as the query is not stopped (i.e. state is not TERMINATED), batchRunner executes the streaming batch for the trigger.
In triggerExecution time-tracking section, runBatches branches off per currentBatchId.
| currentBatchId < 0 | currentBatchId >= 0 |
|---|---|
|
If there is data available in the sources, batchRunner marks currentStatus with isDataAvailable enabled.
|
Note
|
You can check out the status of a streaming query using status method. |
batchRunner then updates the status message to Processing new data and runs the current streaming batch.
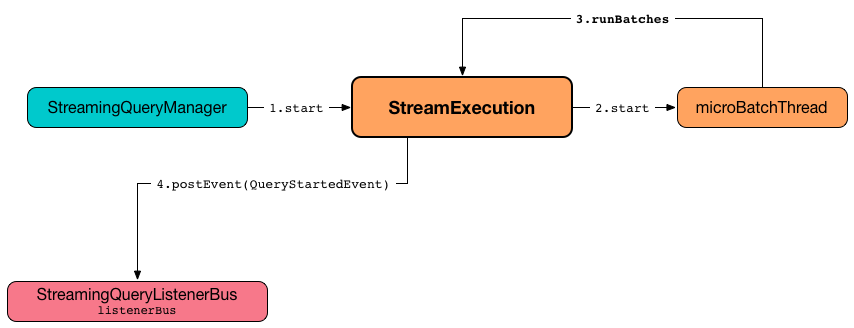
Figure 6. StreamExecution’s Running Batches (on Execution Thread)
After triggerExecution section has finished, batchRunner finishes the streaming batch for the trigger (and collects query execution statistics).
When there was data available in the sources, batchRunner updates committed offsets (by adding the current batch id to BatchCommitLog and adding availableOffsets to committedOffsets).
You should see the following DEBUG message in the logs:
DEBUG batch $currentBatchId committedbatchRunner increments the current batch id and sets the job description for all the following Spark jobs to include the new batch id.
When no data was available in the sources to process, batchRunner does the following:
-
Marks currentStatus with
isDataAvailabledisabled -
Updates the status message to Waiting for data to arrive
-
Sleeps the current thread for pollingDelayMs milliseconds.
batchRunner updates the status message to Waiting for next trigger and returns whether the query is currently active or not (so TriggerExecutor can decide whether to finish executing the batches or not)
Starting Streaming Query (on Stream Execution Thread) — start Method
start(): UnitWhen called, start prints out the following INFO message to the logs:
Starting [prettyIdString]. Use [resolvedCheckpointRoot] to store the query checkpoint.start then starts the stream execution thread (as a daemon thread).
|
Note
|
start uses Java’s java.lang.Thread.start to run the streaming query on a separate execution thread.
|
|
Note
|
When started, a streaming query runs in its own execution thread on JVM. |
In the end, start pauses the main thread (using the startLatch until StreamExecution is requested to run the streaming query that in turn sends a QueryStartedEvent to all streaming listeners followed by decrementing the count of the startLatch).
|
Note
|
start is used exclusively when StreamingQueryManager is requested to start a streaming query (when DataStreamWriter is requested to start an execution of the streaming query).
|
Path to Checkpoint Directory — checkpointFile Internal Method
checkpointFile(name: String): StringcheckpointFile gives the path of a directory with name in checkpoint directory.
|
Note
|
checkpointFile uses Hadoop’s org.apache.hadoop.fs.Path.
|
|
Note
|
checkpointFile is used for streamMetadata, OffsetSeqLog, BatchCommitLog, and lastExecution (for runBatch).
|
Posting StreamingQueryListener Event — postEvent Method
postEvent(event: StreamingQueryListener.Event): Unit|
Note
|
postEvent is a part of ProgressReporter Contract.
|
postEvent simply requests the StreamingQueryManager to post the input event (to the StreamingQueryListenerBus in the current SparkSession).
|
Note
|
postEvent uses SparkSession to access the current StreamingQueryManager.
|
|
Note
|
|
Waiting Until No New Data Available in Sources or Query Has Been Terminated — processAllAvailable Method
processAllAvailable(): Unit|
Note
|
processAllAvailable is a part of StreamingQuery Contract.
|
processAllAvailable reports the StreamingQueryException if reported (and returns immediately).
|
Note
|
streamDeathCause is reported exclusively when StreamExecution is requested to run stream execution (that terminated with an exception).
|
processAllAvailable returns immediately when StreamExecution is no longer active (in TERMINATED state).
processAllAvailable acquires a lock on the awaitProgressLock and turns the noNewData internal flag off (false).
processAllAvailable keeps polling with 10-second pauses (locked on awaitProgressLockCondition) until noNewData flag is turned on (true) or StreamExecution is no longer active (in TERMINATED state).
|
Note
|
The 10-second pause is hardcoded and cannot be changed. |
In the end, processAllAvailable releases awaitProgressLock lock.
processAllAvailable throws an IllegalStateException when executed on the stream execution thread:
Cannot wait for a query state from the same thread that is running the query Stream Execution Thread — queryExecutionThread Property
queryExecutionThread: QueryExecutionThreadqueryExecutionThread is a Java thread of execution (java.util.Thread) that runs a streaming query.
queryExecutionThread is started (as a daemon thread) when StreamExecution is requested to start. At that time, start prints out the following INFO message to the logs (with the prettyIdString and the resolvedCheckpointRoot):
Starting [prettyIdString]. Use [resolvedCheckpointRoot] to store the query checkpoint.When started, queryExecutionThread sets the call site and runs the streaming query.
queryExecutionThread uses the name stream execution thread for [id] (that uses prettyIdString for the id, i.e. queryName [id = [id], runId = [runId]]).
queryExecutionThread is a QueryExecutionThread that is a custom UninterruptibleThread from Apache Spark with runUninterruptibly method for running a block of code without being interrupted by Thread.interrupt().
Internal String Representation — toDebugString Internal Method
toDebugString(includeLogicalPlan: Boolean): StringtoDebugString…FIXME
|
Note
|
toDebugString is used exclusively when StreamExecution is requested to run stream processing (and an exception is caught).
|
Current Batch Metadata (Event-Time Watermark and Timestamp) — offsetSeqMetadata Internal Property
offsetSeqMetadata: OffsetSeqMetadataoffsetSeqMetadata is a OffsetSeqMetadata.
|
Note
|
offsetSeqMetadata is part of the ProgressReporter Contract to hold the current event-time watermark and timestamp.
|
offsetSeqMetadata is used to create an IncrementalExecution in the queryPlanning phase of the MicroBatchExecution and ContinuousExecution execution engines.
offsetSeqMetadata is initialized (with 0 for batchWatermarkMs and batchTimestampMs) when StreamExecution is requested to run stream processing.
offsetSeqMetadata is then updated (with the current event-time watermark and timestamp) when MicroBatchExecution is requested to construct the next streaming micro-batch.
|
Note
|
MicroBatchExecution uses the WatermarkTracker for the current event-time watermark and the trigger clock for the current batch timestamp.
|
offsetSeqMetadata is stored (checkpointed) in walCommit phase of MicroBatchExecution (and printed out as INFO message to the logs).
FIXME INFO messageoffsetSeqMetadata is restored (re-created) from a checkpointed state when MicroBatchExecution is requested to populate start offsets.
isActive Method
isActive: Boolean|
Note
|
isActive is part of the StreamingQuery Contract to indicate whether a streaming query is active (true) or not (false).
|
isActive is enabled (true) as long as the State is not TERMINATED.
exception Method
exception: Option[StreamingQueryException]|
Note
|
exception is part of the StreamingQuery Contract to indicate whether a streaming query…FIXME
|
exception…FIXME
Human-Readable HTML Description of Spark Jobs (for web UI) — getBatchDescriptionString Method
getBatchDescriptionString: StringgetBatchDescriptionString is a human-readable description (in HTML format) that uses the optional name if defined, the id, the runId and batchDescription that can be init (for the current batch ID negative) or the current batch ID itself.
getBatchDescriptionString is of the following format:
[name]<br/>id = [id]<br/>runId = [runId]<br/>batch = [batchDescription]
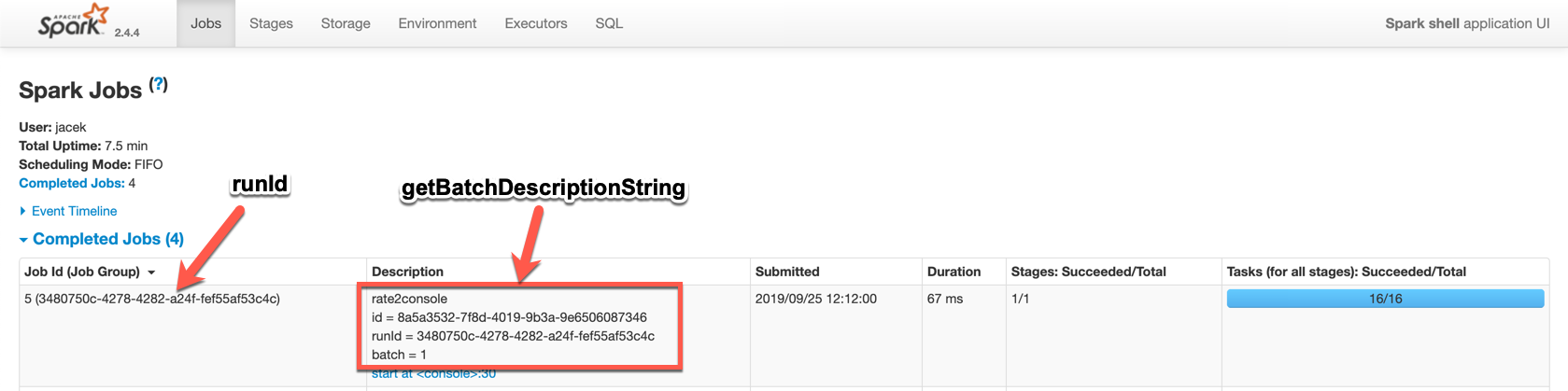
Figure 7. Monitoring Streaming Query using web UI (Spark Jobs)
|
Note
|
|
No New Data Available — noNewData Internal Flag
noNewData: BooleannoNewData is a flag that indicates that a batch has completed with no new data left and processAllAvailable could stop waiting till all streaming data is processed.
Default: false
Turned on (true) when:
-
MicroBatchExecutionstream execution engine is requested to construct or skip the next streaming micro-batch (while skipping the next micro-batch) -
ContinuousExecutionstream execution engine is requested to addOffset
Turned off (false) when:
-
MicroBatchExecutionstream execution engine is requested to construct or skip the next streaming micro-batch (right after the walCommit phase) -
StreamExecutionis requested to processAllAvailable
Internal Properties
| Name | Description | ||
|---|---|---|---|
|
Java’s fair reentrant mutual exclusion java.util.concurrent.locks.ReentrantLock (that favors granting access to the longest-waiting thread under contention) |
||
|
|||
|
|||
|
|
||
|
|||
|
Registry of the streaming sources (in the logical query plan) that have new data available in the current batch. The new data is a streaming
Set exclusively when Used exclusively when |
||
|
Time delay before polling new data again when no data was available Set to spark.sql.streaming.pollingDelay Spark property. Used when |
||
|
Pretty-identified string for identification in logs (with name if defined). |
||
|
Java’s java.util.concurrent.CountDownLatch with count Used when |
||
|
|||
|
MetricsReporter with spark.streaming.[name or id] source name |
||
|
Unique streaming sources (after being collected as
Used when
|