
StateStoreRestoreExec Unary Physical Operator — Restoring Streaming State From State Store
StateStoreRestoreExec is a unary physical operator that restores (reads) a streaming state from a state store (for the keys from the child physical operator).
|
Note
|
A unary physical operator ( Read up on UnaryExecNode (and physical operators in general) in The Internals of Spark SQL book. |
StateStoreRestoreExec is created exclusively when StatefulAggregationStrategy execution planning strategy is requested to plan a streaming aggregation for execution (Aggregate logical operators in the logical plan of a streaming query).
Figure 1. StateStoreRestoreExec and StatefulAggregationStrategy
The optional StatefulOperatorStateInfo is initially undefined (i.e. when StateStoreRestoreExec is created). StateStoreRestoreExec is updated to hold the streaming batch-specific execution property when IncrementalExecution prepares a streaming physical plan for execution (and state preparation rule is executed when StreamExecution plans a streaming query for a streaming batch).

Figure 2. StateStoreRestoreExec and IncrementalExecution
When executed, StateStoreRestoreExec executes the child physical operator and creates a StateStoreRDD to map over partitions with storeUpdateFunction that restores the state for the keys in the input rows if available.
The output schema of StateStoreRestoreExec is exactly the child's output schema.
The output partitioning of StateStoreRestoreExec is exactly the child's output partitioning.
Performance Metrics (SQLMetrics)
| Key | Name (in UI) | Description |
|---|---|---|
|
number of output rows |
The number of input rows from the child physical operator (for which |
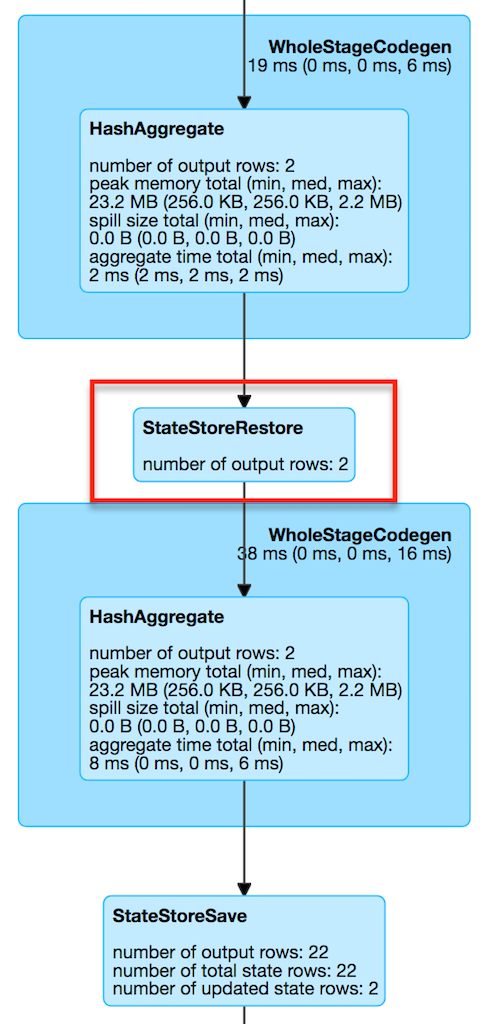
Figure 3. StateStoreRestoreExec in web UI (Details for Query)
Creating StateStoreRestoreExec Instance
StateStoreRestoreExec takes the following to be created:
-
Key expressions, i.e. Catalyst attributes for the grouping keys
-
Optional StatefulOperatorStateInfo (default:
None) -
Version of the state format (based on the spark.sql.streaming.aggregation.stateFormatVersion configuration property)
StateStoreRestoreExec and StreamingAggregationStateManager — stateManager Property
stateManager: StreamingAggregationStateManagerstateManager is a StreamingAggregationStateManager that is created together with StateStoreRestoreExec.
The StreamingAggregationStateManager is created for the keys, the output schema of the child physical operator and the version of the state format.
The StreamingAggregationStateManager is used when StateStoreRestoreExec is requested to generate a recipe for a distributed computation (as a RDD[InternalRow]) for the following:
Executing Physical Operator (Generating RDD[InternalRow]) — doExecute Method
doExecute(): RDD[InternalRow]|
Note
|
doExecute is part of SparkPlan Contract to generate the runtime representation of an physical operator as a distributed computation over internal binary rows on Apache Spark (i.e. RDD[InternalRow]).
|
Internally, doExecute executes child physical operator and creates a StateStoreRDD with storeUpdateFunction that does the following per child operator’s RDD partition:
-
Generates an unsafe projection to access the key field (using keyExpressions and the output schema of child operator).
-
For every input row (as
InternalRow)-
Extracts the key from the row (using the unsafe projection above)
-
Gets the saved state in
StateStorefor the key if available (it might not be if the key appeared in the input the first time) -
Increments numOutputRows metric (that in the end is the number of rows from the child operator)
-
Generates collection made up of the current row and possibly the state for the key if available
-
|
Note
|
The number of rows from StateStoreRestoreExec is the number of rows from the child operator with additional rows for the saved state.
|
|
Note
|
There is no way in StateStoreRestoreExec to find out how many rows had associated state available in a state store. You would have to use the corresponding StateStoreSaveExec operator’s metrics (most likely number of total state rows but that could depend on the output mode).
|