
StateStoreSaveExec Unary Physical Operator — Saving Streaming State To State Store
StateStoreSaveExec is a unary physical operator that saves a streaming state to a state store with support for streaming watermark.
|
Note
|
A unary physical operator ( Read up on UnaryExecNode (and physical operators in general) in The Internals of Spark SQL book. |
StateStoreSaveExec is created exclusively when StatefulAggregationStrategy execution planning strategy is requested to plan a streaming aggregation for execution (Aggregate logical operators in the logical plan of a streaming query).
Figure 1. StateStoreSaveExec and StatefulAggregationStrategy
The optional properties, i.e. the StatefulOperatorStateInfo, the output mode, and the event-time watermark, are initially undefined when StateStoreSaveExec is created. StateStoreSaveExec is updated to hold execution-specific configuration when IncrementalExecution is requested to prepare the logical plan (of a streaming query) for execution (when the state preparation rule is executed).

Figure 2. StateStoreSaveExec and IncrementalExecution
|
Note
|
Unlike StateStoreRestoreExec operator, StateStoreSaveExec takes output mode and event time watermark when created.
|
When executed, StateStoreSaveExec creates a StateStoreRDD to map over partitions with storeUpdateFunction that manages the StateStore.
Figure 3. StateStoreSaveExec creates StateStoreRDD
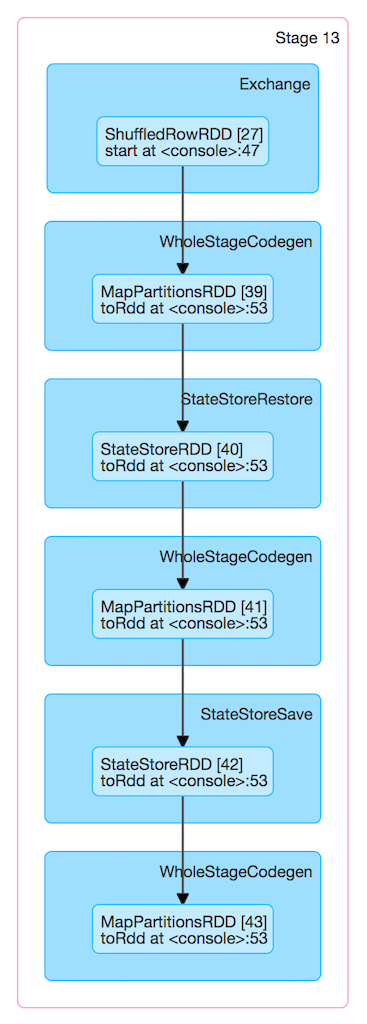
Figure 4. StateStoreSaveExec and StateStoreRDD (after streamingBatch.toRdd.count)
|
Note
|
The number of partitions of StateStoreRDD (and hence the number of Spark tasks) is what was defined for the child physical plan. There will be that many |
|
Note
|
StateStoreSaveExec behaves differently per output mode.
|
When executed, StateStoreSaveExec executes the child physical operator and creates a StateStoreRDD (with storeUpdateFunction specific to the output mode).
The output schema of StateStoreSaveExec is exactly the child's output schema.
The output partitioning of StateStoreSaveExec is exactly the child's output partitioning.
StateStoreRestoreExec uses a StreamingAggregationStateManager (that is created for the keyExpressions, the output of the child physical operator and the stateFormatVersion).
|
Tip
|
Enable Add the following line to Refer to Logging. |
Performance Metrics (SQLMetrics)
StateStoreSaveExec uses the performance metrics as other stateful physical operators that write to a state store.

Figure 5. StateStoreSaveExec in web UI (Details for Query)
The following table shows how the performance metrics are computed (and so their exact meaning).
| Name (in web UI) | Description |
|---|---|
total time to update rows |
Time taken to read the input rows and store them in a state store (possibly filtering out expired rows per watermarkPredicateForData predicate) The number of rows stored is the number of updated state rows metric
|
total time to remove rows |
|
time to commit changes |
|
number of output rows |
|
number of total state rows |
Number of entries in a state store at the very end of executing the StateStoreSaveExec operator (aka numTotalStateRows) Corresponds to |
number of updated state rows |
Number of the entries that were stored as updates in a state store in a trigger and for the keys in the result rows of the upstream physical operator (aka numUpdatedStateRows)
Corresponds to |
memory used by state |
Estimated memory used by a StateStore (aka stateMemory) after |
Creating StateStoreSaveExec Instance
StateStoreSaveExec takes the following to be created:
-
Key expressions, i.e. Catalyst attributes for the grouping keys
-
Execution-specific StatefulOperatorStateInfo (default:
None) -
Execution-specific output mode (default:
None) -
Event-time watermark (default:
None) -
Version of the state format (based on the spark.sql.streaming.aggregation.stateFormatVersion configuration property)
Executing Physical Operator (Generating RDD[InternalRow]) — doExecute Method
doExecute(): RDD[InternalRow]|
Note
|
doExecute is part of SparkPlan Contract to generate the runtime representation of an physical operator as a distributed computation over internal binary rows on Apache Spark (i.e. RDD[InternalRow]).
|
Internally, doExecute initializes metrics.
|
Note
|
doExecute requires that the optional outputMode is at this point defined (that should have happened when IncrementalExecution had prepared a streaming aggregation for execution).
|
doExecute executes child physical operator and creates a StateStoreRDD with storeUpdateFunction that:
-
Generates an unsafe projection to access the key field (using keyExpressions and the output schema of child).
-
Branches off per output mode: Append, Complete and Update.
doExecute throws an UnsupportedOperationException when executed with an invalid output mode:
Invalid output mode: [outputMode]Append Output Mode
|
Note
|
Append is the default output mode when not specified explicitly. |
|
Note
|
Append output mode requires that a streaming query defines event-time watermark (e.g. using withWatermark operator) on the event-time column that is used in aggregation (directly or using window standard function).
|
For Append output mode, doExecute does the following:
-
Finds late (aggregate) rows from child physical operator (that have expired per watermark)
-
Stores the late rows in the state store and increments the numUpdatedStateRows metric
-
Creates an iterator that removes the late rows from the state store when requested the next row and in the end commits the state updates
|
Tip
|
Refer to Demo: Streaming Watermark with Aggregation in Append Output Mode for an example of StateStoreSaveExec with Append output mode.
|
|
Caution
|
FIXME When is "Filtering state store on:" printed out? |
-
Uses watermarkPredicateForData predicate to exclude matching rows and (like in Complete output mode) stores all the remaining rows in
StateStore. -
(like in Complete output mode) While storing the rows, increments numUpdatedStateRows metric (for every row) and records the total time in allUpdatesTimeMs metric.
-
Takes all the rows from
StateStoreand returns aNextIteratorthat:-
In
getNext, finds the first row that matches watermarkPredicateForKeys predicate, removes it fromStateStore, and returns it back.If no row was found,
getNextalso marks the iterator as finished. -
In
close, records the time to iterate over all the rows in allRemovalsTimeMs metric, commits the updates toStateStorefollowed by recording the time in commitTimeMs metric and recording StateStore metrics.
-
Complete Output Mode
For Complete output mode, doExecute does the following:
-
Takes all
UnsafeRowrows (from the parent iterator) -
Stores the rows by key in the state store eagerly (i.e. all rows that are available in the parent iterator before proceeding)
-
In the end, reads the key-row pairs from the state store and passes the rows along (i.e. to the following physical operator)
The number of keys stored in the state store is recorded in numUpdatedStateRows metric.
|
Note
|
In Complete output mode the numOutputRows metric is exactly the numTotalStateRows metric.
|
|
Tip
|
Refer to Demo: StateStoreSaveExec with Complete Output Mode for an example of StateStoreSaveExec with Complete output mode.
|
-
Stores all rows (as
UnsafeRow) inStateStore. -
While storing the rows, increments numUpdatedStateRows metric (for every row) and records the total time in allUpdatesTimeMs metric.
-
Records
0in allRemovalsTimeMs metric. -
Commits the state updates to
StateStoreand records the time in commitTimeMs metric. -
In the end, takes all the rows stored in
StateStoreand increments numOutputRows metric.
Update Output Mode
For Update output mode, doExecute returns an iterator that filters out late aggregate rows (per watermark if defined) and stores the "young" rows in the state store (one by one, i.e. every next).
With no more rows available, that removes the late rows from the state store (all at once) and commits the state updates.
|
Tip
|
Refer to Demo: StateStoreSaveExec with Update Output Mode for an example of StateStoreSaveExec with Update output mode.
|
doExecute returns Iterator of rows that uses watermarkPredicateForData predicate to filter out late rows.
In hasNext, when rows are no longer available:
-
Records the total time to iterate over all the rows in allUpdatesTimeMs metric.
-
removeKeysOlderThanWatermark and records the time in allRemovalsTimeMs metric.
-
Commits the updates to
StateStoreand records the time in commitTimeMs metric.
In next, stores a row in StateStore and increments numOutputRows and numUpdatedStateRows metrics.
Checking Out Whether Last Batch Execution Requires Another Non-Data Batch or Not — shouldRunAnotherBatch Method
shouldRunAnotherBatch(
newMetadata: OffsetSeqMetadata): Boolean|
Note
|
shouldRunAnotherBatch is part of the StateStoreWriter Contract to indicate whether MicroBatchExecution should run another non-data batch (based on the updated OffsetSeqMetadata with the current event-time watermark and the batch timestamp).
|
shouldRunAnotherBatch is positive (true) when all of the following are met:
-
Output mode is either Append or Update
-
Event-time watermark is defined and is older (below) the current event-time watermark (of the given
OffsetSeqMetadata)
Otherwise, shouldRunAnotherBatch is negative (false).