$ docker run -u $UID --privileged -v `pwd`:/antora --rm -t antora/antora antora-playbook.yml
// alternatively and recommended
$ docker run --entrypoint ash --privileged -v `pwd`:/antora --rm -it antora/antora
// Inside the container
/antora # antora version
2.2.0
/antora # antora local-antora-playbook.yml
// On your local computer (outside the container)
$ open .out/local/index.htmlThe Internals Of Apache Spark Online Book
The project contains the sources of The Internals Of Apache Spark online book.
Toolz
The project uses the following toolz:
-
Antora which is touted as The Static Site Generator for Tech Writers.
-
Asciidoc (with some Asciidoctor)
-
Atom editor with Asciidoc preview plugin
It’s all to make things harder…ekhm…reach higher levels of writing zen.
Generating Book
In order to generate the book, use the commands as described in Run Antora in a Container.
Below are the steps I’m taking to deploy a new version of the site.
IMPORTANT: If your Antora build does not seem to work properly, use docker run … --pull. This resets your cache.
Not Sphinx?! Why?
GitHub Flavored writing flow
While on writing route, I’m also aiming at mastering the git(hub) flow to write the book as described in Living the Future of Technical Writing (with pull requests for chapters, action items to show progress of each branch and such).
The branching and task progress features embrace the concept of working on a branch per chapter and using pull requests with GitHub Flavored Markdown for Task Lists. Once the tasks are defined, GitHub shows progress of a pull request with number of tasks completed and progress bar.
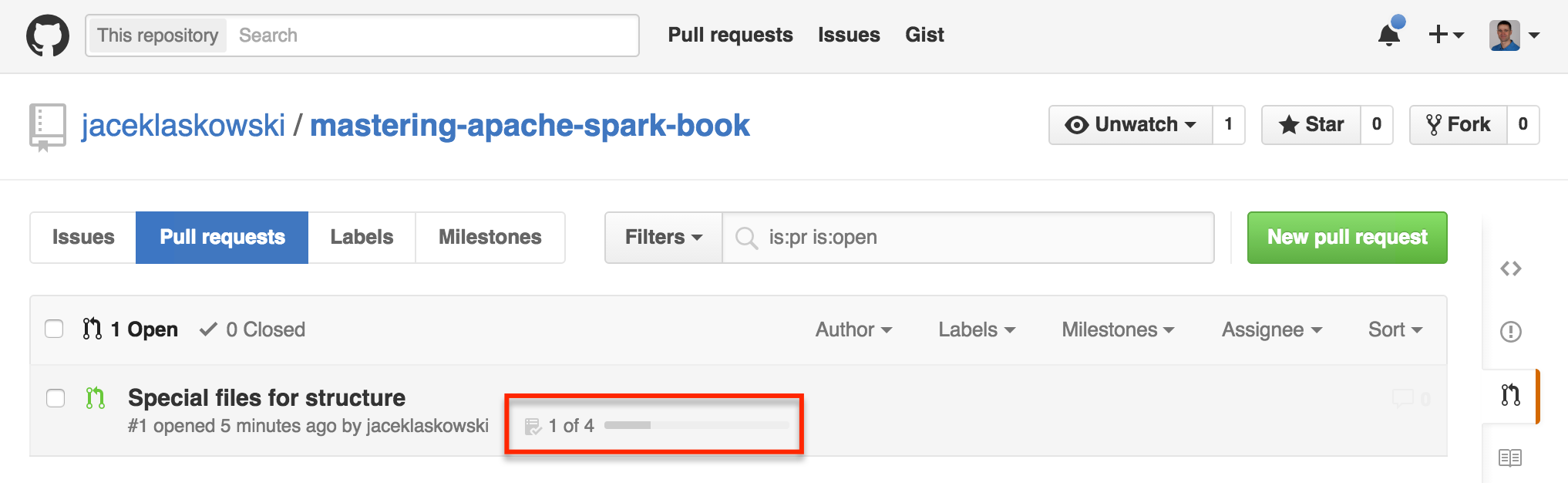
Figure 1. Pull request with 4 tasks of which 1 is completed